java 实现简单爬虫,爬取图片。
根据爬取页面内容,使用jsoup解析html页面,获取需要的路径,进行循环下载。
效果:
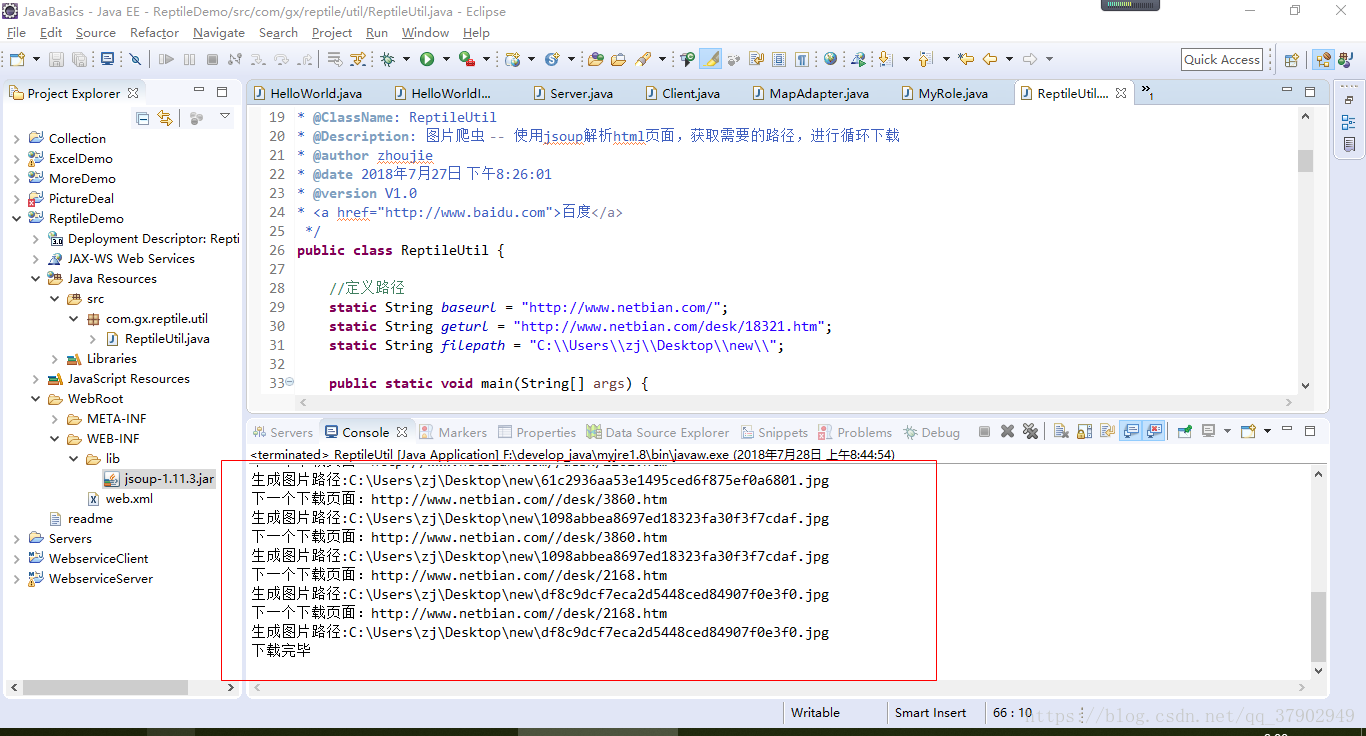
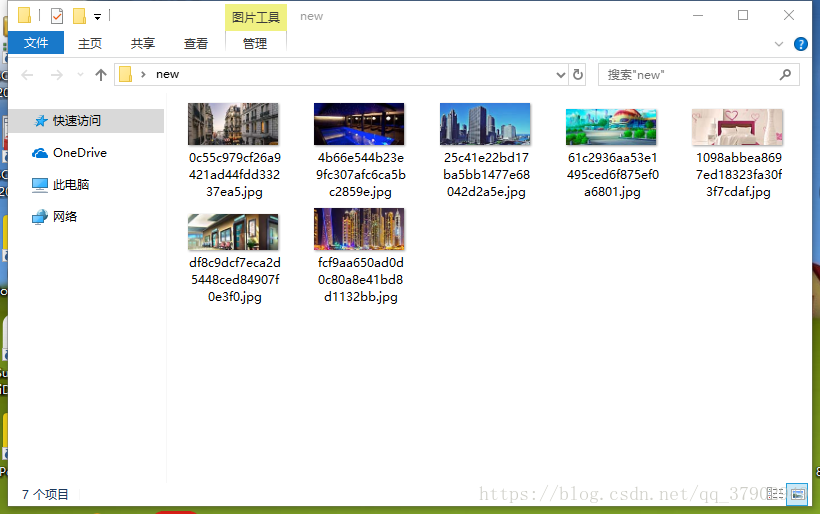
实现代码思路:
1、定义需要下载初始路径,这里下载的是http://www.netbian.com/desk/18321.htm高清壁纸
2、获取页面内容,定义方法getHtml(String url)
3、获取页面内容图片路径,定义方法getImgSrcListFromHtml(String html)
4、从页面内容中获取下一个页面路径,定义方法getNextPageUrl(String html)
5、下载图片,downloadImg(List<String> list, String filepath),实现:通过获取的流转成byte[]数组,再通过FileOutputStream写出
6、InputStream流转换byte[]定义方法getBytesFromInputStream(InputStream inputStream),实现:ByteArrayOutputStream的toByteArray()方法转byte[];
全部代码:
package com.gx.reptile.util;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
/**
*
* @ClassName: ReptileUtil
* @Description: 图片爬虫 -- 使用jsoup解析html页面,获取需要的路径,进行循环下载
* @author zhoujie
* @date 2018年7月27日 下午8:26:01
* @version V1.0
* <a href="http://www.baidu.com">百度</a>
*/
public class ReptileUtil {
//定义路径
static String baseurl = "http://www.netbian.com/";
static String geturl = "http://www.netbian.com/desk/18321.htm";
static String filepath = "C:\Users\zj\Desktop\new\";
public static void main(String[] args) {
System.out.println("初始下载页面:"+geturl);
String html = getHtml(geturl); //html页面内容
List<String> srclists = getImgSrcListFromHtml(html); //图片地址集合
downloadImg(srclists, filepath); //下载图片
//获取下一个页面进行下载
List<String> list = getNextPageUrl(html);
System.out.println(list.size());
for (int i = 0; i < list.size(); i++) {
String url = list.get(i);
System.out.println("下一个下载页面:"+url);
String html2 = getHtml(url); //html页面内容
List<String> srclists2 = getImgSrcListFromHtml(html2); //图片地址集合
downloadImg(srclists2, filepath); //下载图片
}
System.out.println("下载完毕");
}
/**
*
* @Title: getHtml
* @Description: 获取页面内容
* @param @param url
* @param @return 页面内容
* @return String 返回类型
* @throws
*/
public static String getHtml(String url){
String html = "";
try {
html = Jsoup.connect(url).execute().body();
} catch (IOException e) {
e.printStackTrace();
}
return html;
}
/**
*
* @Title: getImgSrcListFromHtml
* @Description: 获取页面内容图片路径
* @param @param html 页面内容
* @param @return 图片路径数组
* @return ArrayList<String> 返回类型
* @throws
*/
public static List<String> getImgSrcListFromHtml(String html){
List<String> list = new ArrayList<>();
//解析成html页面
Document document = Jsoup.parse(html);
//获取目标
Elements elements = document.select("div [class=pic]").select("img");
int len = elements.size();
for (int i = 0; i < len; i++) {
list.add(elements.get(i).attr("src"));
}
return list;
}
/**
*
* @Title: getNextPage
* @Description: 从页面内容中获取下一个页面路径
* @param 页面内容
* @return List<String> 返回页面url数组
* @throws
*/
public static List<String> getNextPageUrl(String html){
List<String> list = new ArrayList<>();
//解析成html页面
Document document = Jsoup.parse(html);
//获取目标
Elements elements = document.select("div [class=list]").select("a");
for (int i = 0;i<elements.size();i++) {
String url = baseurl + elements.get(i).attr("href");
list.add(url);
}
return list;
}
/**
*
* @Title: downloadImg
* @Description: 下载图片 -- 通过获取的流转成byte[]数组,再通过FileOutputStream写出
* @param @param list 图片路径数组
* @param @param filepath 保存文件夹位置
* @return void 返回类型
* @throws
*/
public static void downloadImg(List<String> list, String filepath){
URL newUrl = null;
HttpURLConnection hconnection = null;
InputStream inputStream = null;
FileOutputStream fileOutputStream = null;
byte[] bs = null;
try {
int len = list.size();
for (int i = 0; i < len; i++) {
newUrl = new URL(list.get(i));
hconnection = (HttpURLConnection) newUrl.openConnection(); //打开连接
inputStream = hconnection.getInputStream(); //获取流
bs = getBytesFromInputStream(inputStream); //流转btye[]
filepath = filepath + list.get(i).substring(list.get(i).lastIndexOf("/")+1); //获取图片名称
System.out.println("生成图片路径:"+filepath);
fileOutputStream = new FileOutputStream(new File(filepath));
fileOutputStream.write(bs); //写出
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
inputStream.close();
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
*
* @Title: getBytesFromInputStream
* @Description: InputStream流转换byte[]
* @param @param inputStream
* @param @return byte[]
* @return byte[] 返回类型
* @throws
*/
public static byte[] getBytesFromInputStream(InputStream inputStream){
byte[] bs = null;
try {
byte[] buffer = new byte[1024];
int len = 0;
ByteArrayOutputStream arrayOutputStream = new ByteArrayOutputStream(); //
while((len = inputStream.read(buffer)) != -1){
arrayOutputStream.write(buffer, 0 ,len);
}
bs = arrayOutputStream.toByteArray();
} catch (IOException e) {
e.printStackTrace();
}
return bs;
}
}
ok。