下载一首英文的歌词或文章
将所有,.?!’:等分隔符全部替换为空格
将所有大写转换为小写
生成单词列表
f=open('news.txt','r') news=f.read() f.close() sep=''',.'!"?:''' for c in sep: news=news.replace(c,' ') wordList=news.lower().split() for w in wordList: print(w)
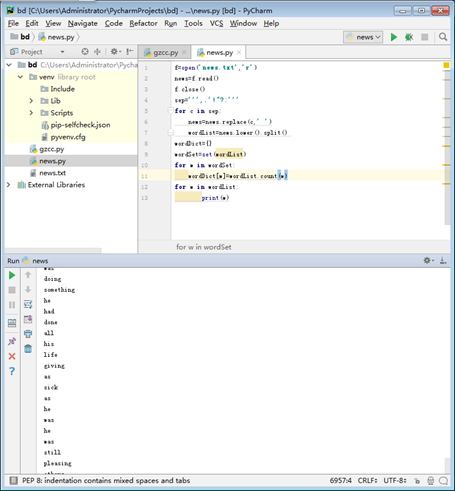
生成词频统计
f=open('news.txt','r') news=f.read() f.close() sep=''',.'!"?:''' for c in sep: news=news.replace(c,' ') wordList=news.lower().split() wordDict={} wordSet=set(wordList) for w in wordSet: wordDict[w]=wordList.count(w) for w in wordDict: print(w,wordDict[w])

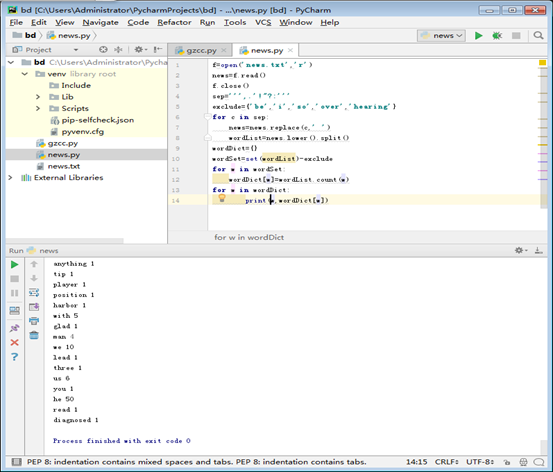
排除语法型词汇,代词、冠词、连词
f=open('news.txt','r') news=f.read() f.close() sep=''',.'!"?:''' exclude={'be','i','so','over','hearing'} for c in sep: news=news.replace(c,' ') wordList=news.lower().split() wordDict={} wordSet=set(wordList)-exclude for w in wordSet: wordDict[w]=wordList.count(w) for w in wordDict: print(w,wordDict[w])
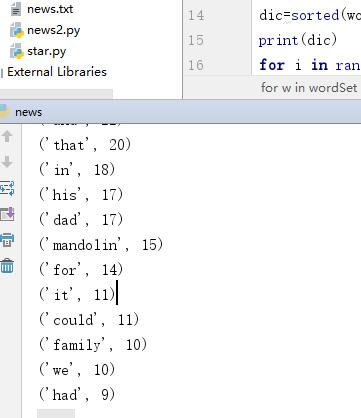
排序、输出词频最大TOP20
f=open('news.txt','r')
news=f.read()
f.close()
sep=''',.'!"?:'''
exclude={'be','i','so','over','hearing'}
for c in sep:
news=news.replace(c,' ')
wordList=news.lower().split()
wordDict={}
wordSet=set(wordList)-exclude
for w in wordSet:
wordDict[w]=wordList.count(w)
dic=sorted(wordDict.items(),key=lambda d:d[1],reverse=True)
print(dic)
for i in range(20):
print(dic[i])
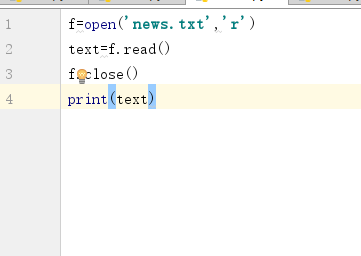
将分析对象存为utf-8编码的文件,通过文件读取的方式获得词频分析内容。
f=open('news.txt','r') text=f.read() f.close() print(text)