文章目录
1. 前言
Python其实已经实现过随机森林, 而且有并行化的参数n_jobs 来设置可以使用多个可用的cpu核并行计算。
n_jobs : int or None, optional (default=None)
The number of jobs to run in parallel for both fit and predict. None means 1 unless in a joblib.parallel_backend context. -1 means using all processors. See Glossary for more details.
当然我们使用的是多进程来实现并行化, 和scikit-learn有些不同
2. 随机森林原理
随机森林是一种集成算法(Ensemble Learning),它属于Bagging类型,通过组合多个弱分类器,最终结果通过投票或取均值,使得整体模型的结果具有较高的精确度和泛化性能。其可以取得不错成绩,主要归功于“随机”和“森林”,一个使它具有抗过拟合能力,一个使它更加精准。
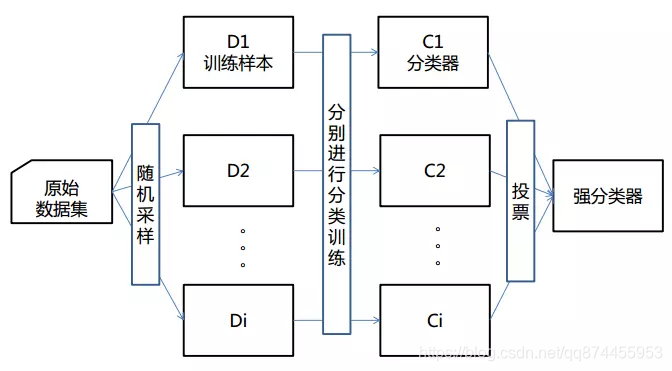
Bagging
Bagging也叫自举汇聚法(bootstrap aggregating),是一种在原始数据集上通过有放回抽样重新选出k个新数据集来训练分类器的集成技术。它使用训练出来的分类器的集合来对新样本进行分类,然后用多数投票或者对输出求均值的方法统计所有分类器的分类结果,结果最高的类别即为最终标签。此类算法可以有效降低bias,并能够降低variance。
3.实现原理
3.1并行化训练
由于随机森林是 通过bagging方法分成多个数据集,然后在生成的数据集上训练生成多个决策树, 因为每个决策树是相互独立的, 则可以在开启多个进程,每个进程都生成决策树, 然后把生成的决策树放到队列,用于训练
3.1.1训练函数
首先平均分出每个线程应该生成几颗决策树, 然后生成进程, 进行训练, 把训练生成的决策树加入到决策树队列(决策树森林)中, 这里用的决策树是直接调用的库决策树,若有兴趣,可以单撸一个决策树出来。
注意这里我选择让每个进程生成的决策树的个数相同, 所以 参数输入的决策树个数可能不是实际生成的决策树个数,例如 100颗决策树 8个进程, 则每个进程只会生成 int(100/8) = 12颗决策树
def fit(self, X, Y):
# 分出每个线程 应该生成几颗决策树
job_tree_num = int ( self.n_estimators / self.n_jobs)
processes = list()
#随机森林的决策树参数
dtr_args = {
"criterion": self.criterion,
"max_depth": self.max_depth,
"max_features": self.max_features,
"max_leaf_nodes": self.max_leaf_nodes,
"min_impurity_decrease": self.min_impurity_decrease,
"min_impurity_split": self.min_impurity_split,
"min_samples_leaf": self.min_samples_leaf,
"min_samples_split": self.min_samples_split,
"min_weight_fraction_leaf": self.min_weight_fraction_leaf,
"random_state": self.random_state,
"splitter": self.splitter
}
# 生成N个进程
for i in range(self.n_jobs):
# 参数
#job_forest_queue 为决策树队列 每个进程生成的决策树将加入到此队列 这是随机森林对象的一个属性
#i 为进程号
#job_tree_num 表示该进程需要生成的决策树
#X Y 表示训练数据 和结果数据
#dtr_args 表示传入的决策树参数
p = Process(target=signal_process_train, args=(self.job_forest_queue, i,job_tree_num , X, Y, dtr_args))
print ('process Num. ' + str(i) + " will start train")
p.start()
processes.append(p)
for p in processes:
p.join()
print ("Train end")
3.1.2 单进程训练函数
生成数据集模块——生成部分数据集
首先生成一个index, 长度为原来数据集的0.7倍,然后将其打乱,按照打乱的index加入数据,即可生成打乱的数据集, 大小为原来数据集的0.7倍
len = int(Y.shape[0] * 0.7)
indexs = np.arange(len)
np.random.shuffle(indexs)
x = []
y = []
for ind in indexs:
x.append(X.values[ind])
y.append(Y.values[ind])
单进程训练函数代码
循环生成决策树, 并且把生成的决策树加入到队列中
#单进程训练函数
def signal_process_train(job_forest_queue,process_num,job_tree_num,X, Y, dtr_args):
#循环生成决策树, 并且把生成的决策树加入到job_forest_queue 队列中
for i in range(0, job_tree_num):
# 使用bootstrap 方法生成 1个 训练集
len = int(Y.shape[0] * 0.7)
indexs = np.arange(len)
np.random.shuffle(indexs)
x = []
y = []
for ind in indexs:
x.append(X.values[ind])
y.append(Y.values[ind])
# 对这个样本 进行训练 并且根据传入的决策树参数 生成1棵决策树
dtr = DecisionTreeRegressor(n_job=1 ,criterion=dtr_args['criterion'], max_depth=dtr_args['max_depth'],
max_features=dtr_args['max_features'],max_leaf_nodes=dtr_args['max_leaf_nodes'],
min_impurity_decrease=dtr_args['min_impurity_decrease'],
min_impurity_split=dtr_args['min_impurity_split'],
min_samples_leaf=dtr_args['min_samples_leaf'], min_samples_split=dtr_args['min_samples_split'],
min_weight_fraction_leaf=dtr_args['min_weight_fraction_leaf'],
random_state=dtr_args['random_state'], splitter=dtr_args['splitter'])
dtr.fit(x,y)
if (i% int(job_tree_num/10 or i<10) == 0):
print ('process Num. ' + str(process_num) + " trained " + str(i) + ' tree')
# 决策树存进森林(决策树队列)
job_forest_queue.put(dtr)
print('process Num. ' + str(process_num) + ' train Done!!')
3.2 并行化预测
同理, 生成多个进程,每个进程在随机森林里得到树来进行预测, 每个进程返回这个进程处理的所有决策树的预测结果的平均值, 然后将每个进程返回的平均值再一次进行平均,则得到结果
3.2.1 预测函数
def predict(self, X):
result_queue = Manager().Queue()
processes = list()
# 分出每个线程 应该预测几颗决策树
job_tree_num = int(self.n_estimators / self.n_jobs)
# 生成N个进程
for i in range(self.n_jobs):
# 参数
# job_forest_queue 为决策树队列 这是随机森林对象的一个属性
# i 为进程号
# job_tree_num 表示该进程需要生成的决策树
# X 表示待预测数据
# result_queue 表示用于存放预测结果的数据
p = Process(target=signal_process_predict, args=(self.job_forest_queue, i, job_tree_num, X, result_queue))
print('process Num. ' + str(i) + " will start predict")
p.start()
processes.append(p)
for p in processes:
p.join()
result = np.zeros(X.shape[0])
#把每个进程的平均结果再一次加起来求平均, 得到最终结果
for i in range(result_queue.qsize()):
result = result + result_queue.get()
result = result / self.n_jobs
print("Predict end")
return result
3.2.2 单进程预测函数
每一次去除一棵树, 预测结果,然后将结果加起来,最后进程结束时, 把预测结果求平均,进行返回
#单进程预测函数
def signal_process_predict(job_forest_queue,process_num,job_tree_num,X,result_queue):
# 生成结果矩阵
result = np.zeros(X.shape[0])
for i in range(job_tree_num):
# 从队列中取出一颗树 进行预测
tree = job_forest_queue.get()
result_single = tree.predict(X)
# 将得出的结果加到总结果中
result = result +result_single
# 算出平均结果 放入结果队列中
result = result / job_tree_num
result_queue.put(result)
print('process ' + str(process_num) + ' predict Done!!')
4. 并行化结果分析
可以发现当进程数增加时, 训练时间会减少,并行化成功
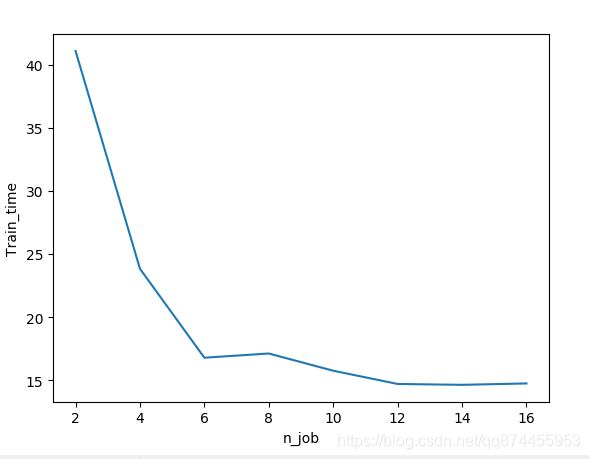
但是当进程数到一定大小后, 进程间的调度可能会消耗更多时间, 减少也不明显了
5. 源码
完整github地址如下: 若有错误,欢迎指正!
https://github.com/wangjiwu/parallel_random_forest
参考资料
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
https://www.jianshu.com/p/a779f0686acc
https://docs.python.org/3.7/library/multiprocessing.html#multiprocessing.Queue
https://www.cnblogs.com/shixisheng/p/7119217.html