慕课网学习笔记——XML
加油吧
XML是什么
- XML的全称是EXtensible Markup Language,可扩展标记语言
- 编写XML就是编写标签,与HTML非常相似,扩展名.xml
- 具有良好的人机可读性
XML与HTML的比较
- 两者相似
- XML没有预定义标签,HTML存在大量预定义标签
- XML重在保存和传输数据,HTML用于显示数据

XML的用途(web应用配置文件)
- java程序的配置描述文件
- 用于保存程序的产生数据
- 网络间的数据传输

XML文档结构
- 第一行必须是XML声明
- 有且只有一个根节点
- XML标签的书写规则与HTML相同
XML声明
<?xml version="1.0" encoding="UTF-8"?>
version="1.0"版本号
encoding="UTF-8"设置字符集,用于支持中文
我的第一份XML文档


1 <?xml version="1.0" encoding="UTF-8"?> 2 <!-- 人力资源管理系统 --> 3 <hr> 4 <employee no="100"> 5 <name>张三</name> 6 <age>31</age> 7 <salary>4000</salary> 8 <department> 9 <dname>会计部</dname> 10 <address>XXX</address> 11 </department> 12 </employee> 13 14 <employee no="101"> 15 <name>李四</name> 16 <age>31</age> 17 <salary>3000</salary> 18 <department> 19 <dname>工程部</dname> 20 <address>XXX</address> 21 </department> 22 </employee> 23 </hr>

XML标签书写规则
合法的标签名
标签名有意义
建议使用英文,小写字母,单词之间使用"-"分割
建议多级标签不要重名
适当的注释与缩进
适当的注释与缩进可以让XML文档更容易阅读
合理使用属性
标签属性用于描述标签不可或缺的信息
对标签分组或者为标签设置Id时常用属性表示
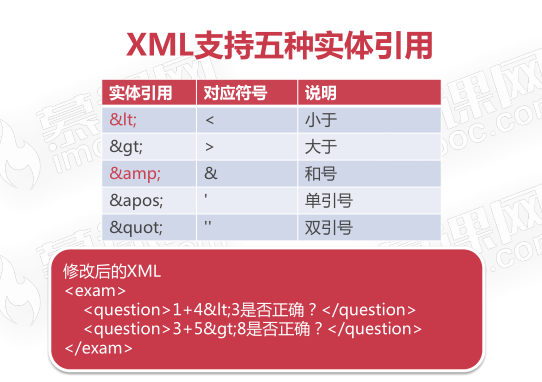
处理特殊字符
标签体,出现"<"、">"特殊字符,会破坏文档结构
解决方法1:使用实体引用
解决方法2:使用CDATA标签
CDATA指的是不应由XML解析器进行解析的文本数据
从<![CDATA[XXX]]> <!CDATA[[]]>
有序的子元素
在XML多层嵌套的子元素中,标签前后顺序应保持一致
XML语义约束
XML文档结构正确,但可能不是有效的
XML语义约束有两种定义方式:DTD与XML Schema
Document Type Definition
DTD文档类型定义,是一种简单易用的语义约束方式
扩展名为.dtd
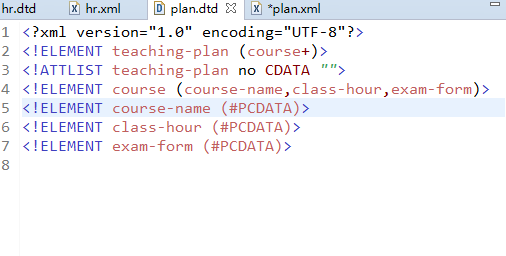
DTD定义节点

DTD定义节点数量

XML引用DTD文件
<!DOCTYPE 根节点 SYSTEM "dtd文件路径"
创建DTD文件,编写第一个DTD文件

XML Schema

第一个XML Schema
1 <?xml version="1.0" encoding="UTF-8"?> 2 <schema xmlns="http://www.w3.org/2001/XMLSchema"> 3 <element name="teaching-plan"> 4 <complexType> 5 <sequence> 6 <element name="course" minOccurs="1" maxOccurs="100"> 7 <complexType> 8 <sequence> 9 <element name="course-name" type="string"></element> 10 <element name="class-hour"> 11 <simpleType> 12 <restriction base="integer"> 13 <minInclusive value="20"></minInclusive> 14 <maxInclusive value="110"></maxInclusive> 15 </restriction> 16 </simpleType> 17 </element> 18 <element name="exam-form" type="string"></element> 19 </sequence> 20 </complexType> 21 </element> 22 </sequence> 23 <attribute name="id" type="string" use="required"></attribute> 24 </complexType> 25 </element> 26 </schema>
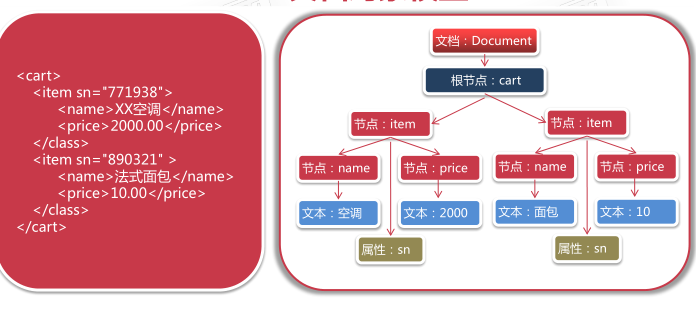
DOM文档对象模型
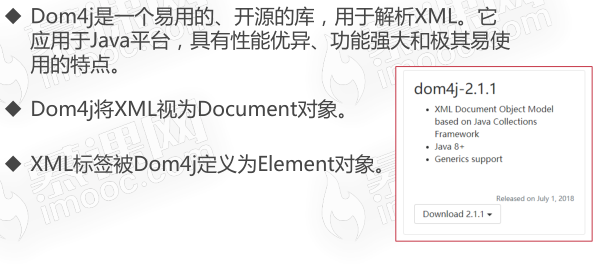
Dom4j
利用Dom4j读写xml文件
plan.xml
xml
1 <?xml version="1.0" encoding="UTF-8"?> 2 <!DOCTYPE plan SYSTEM "plan.dtd"> 3 <teaching-plan> 4 <course> 5 <course-name>大学英语</course-name> 6 <class-hour>36</class-hour> 7 <exam-form>考试</exam-form> 8 </course> 9 <course> 10 <course-name>高等数学</course-name> 11 <class-hour>70</class-hour> 12 <exam-form>考试</exam-form> 13 </course> 14 <course> 15 <course-name>计算机应用基础</course-name> 16 <class-hour>108</class-hour> 17 <exam-form>上机考试</exam-form> 18 </course> 19 <course> 20 <course-name>科学</course-name> 21 <class-hour>60</class-hour> 22 <exam-form>考试</exam-form> 23 </course> 24 </teaching-plan>
读取
1 package com.imooc.dom4j; 2 3 import java.util.List; 4 5 import org.dom4j.Document; 6 import org.dom4j.DocumentException; 7 import org.dom4j.Element; 8 import org.dom4j.io.SAXReader; 9 10 public class PlanReader { 11 public void readxml() { 12 String file="f:/workspace/xml/src/plan.xml"; 13 SAXReader reader=new SAXReader(); 14 try { 15 Document document=reader.read(file); 16 //获取XML文档的根节点,即hr标签 17 Element root=document.getRootElement(); 18 List<Element> courses=root.elements("course"); 19 for(Element course:courses ) { 20 Element courseName=course.element("course-name"); 21 String n=courseName.getText();//getText()方法用于获取标签文本 22 System.out.println(n); 23 System.out.println(course.elementText("class-hour")); 24 System.out.println(course.elementText("exam-form")); 25 } 26 } catch (Exception e) { 27 // TODO Auto-generated catch block 28 e.printStackTrace(); 29 } 30 } 31 32 public static void main(String[] args) { 33 PlanReader reader=new PlanReader(); 34 reader.readxml(); 35 } 36 }
写入
1 package com.imooc.dom4j; 2 3 import java.io.FileOutputStream; 4 import java.io.OutputStreamWriter; 5 import java.io.Writer; 6 7 import org.dom4j.Document; 8 import org.dom4j.DocumentException; 9 import org.dom4j.Element; 10 import org.dom4j.io.SAXReader; 11 12 public class PlanWriter { 13 public void writexml() { 14 String file="f:/workspace/xml/src/plan.xml"; 15 SAXReader reader=new SAXReader(); 16 try { 17 Document document=reader.read(file); 18 Element root=document.getRootElement(); 19 Element course=root.addElement("course"); 20 course.addElement("course-name").setText("科学"); 21 course.addElement("class-hour").setText("60"); 22 course.addElement("exam-form").setText("考试"); 23 24 Writer writer=new OutputStreamWriter(new FileOutputStream(file),"UTF-8"); 25 document.write(writer); 26 writer.close(); 27 } catch (Exception e) { 28 // TODO Auto-generated catch block 29 e.printStackTrace(); 30 } 31 } 32 public static void main(String[] args) { 33 PlanWriter planWriter=new PlanWriter(); 34 planWriter.writexml(); 35 } 36 }
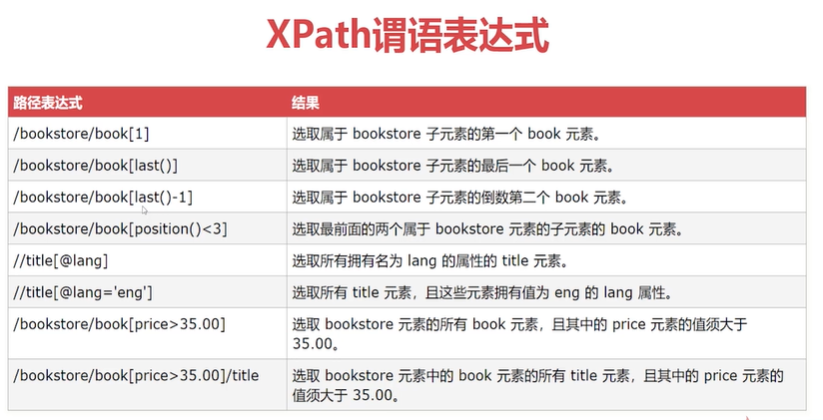
XPath路径表达式

XPath基本表达式+谓语表达式


XPath实验室
利用Dom4j开发"XPath实验室",一起见证XPath神器之处
Jaxen介绍

tip:
我们在访问jaxen.codehaus.org时,由于服务器在国外,我们无法访问,
解决办法是访问阿里云提供的平台:aliyun.com,进行下载
最后练习:
利用XPath对存储课程信息的plan.xml文档进行查询并将结果输出,要求如下:
-
获取所有课程信息
-
查询课时小于50的课程信息
-
查询课程名为高等数学的课程信息
-
查询属性id为001的课程信息
-
查询前两条课程信息
package com.imooc.dom4j; import java.util.List; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.Node; import org.dom4j.io.SAXReader; public class XPlan { public void xplan(String xpathExp) { String file ="f:/workspace/xml/src/plan.xml"; //SAXReader类是读取XML文件的核心类,用于将XML解析后以“树”的形式保存在内存中 SAXReader reader=new SAXReader(); try { Document document=reader.read(file); List<Node> nodes=document.selectNodes(xpathExp); for(Node node:nodes) { Element course=(Element)node; System.out.println(course.attributeValue("id")); System.out.println(course.elementText("course-name")); System.out.println(course.elementText("class-hour")); System.out.println(course.elementText("exam-form")); System.out.println("=============="); } } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } public static void main(String[] args) { XPlan testor=new XPlan(); testor.xplan("//course"); testor.xplan("//course[class-hour<50]"); testor.xplan("//course[course-name='高等数学']"); testor.xplan("//course[@id='001']"); testor.xplan("//course[position()<3]"); } }
