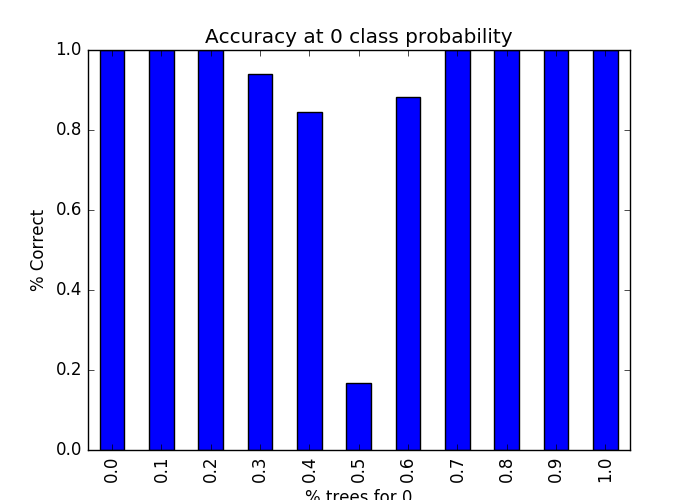
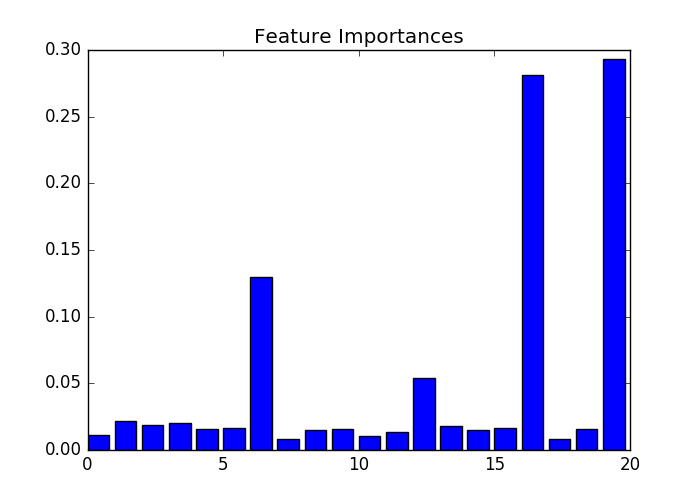
#In the next recipe, we'll look at how to tune the random forest classifier. #Let's start by importing datasets: from sklearn import datasets X, y = datasets.make_classification(1000) # X(1000,20) #y(1000) 取值范围【0,1】 from sklearn.ensemble import RandomForestClassifier rf = RandomForestClassifier() rf.n_jobs=-1 rf.fit(X, y) print ("Accuracy: ", (y == rf.predict(X)).mean()) print ("Total Correct: ", (y == rf.predict(X)).sum()) #每个例子属于哪个类的概率 probs = rf.predict_proba(X) import pandas as pd probs_df = pd.DataFrame(probs, columns=['0', '1']) probs_df['was_correct'] = rf.predict(X) == y import matplotlib.pyplot as plt f, ax = plt.subplots(figsize=(7, 5)) probs_df.groupby('0').was_correct.mean().plot(kind='bar', ax=ax) ax.set_title("Accuracy at 0 class probability") ax.set_ylabel("% Correct") ax.set_xlabel("% trees for 0") f.show() #检测重要特征 rf = RandomForestClassifier() rf.fit(X, y) f, ax = plt.subplots(figsize=(7, 5)) ax.bar(range(len(rf.feature_importances_)),rf.feature_importances_) ax.set_title("Feature Importances") f.show()