一、python3 requests 登陆51job后下载简历照片
1、打开谷歌浏览器,按F12,手动登陆一下,获取登陆地址和表单数据及要下载的图片地址
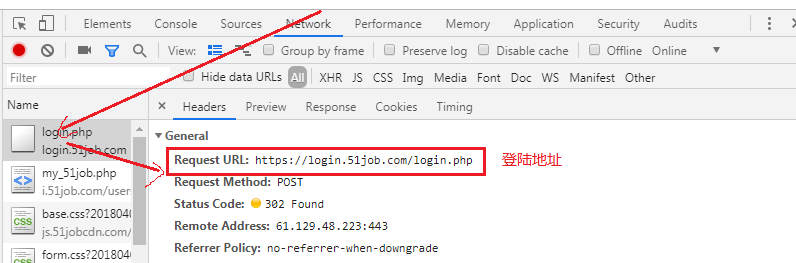
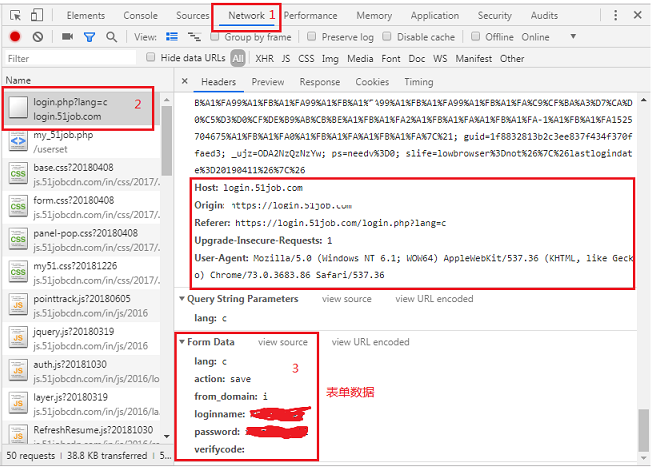
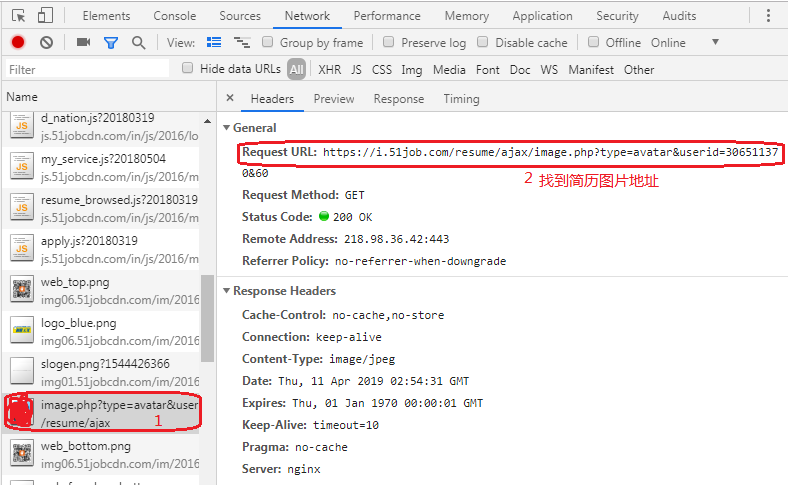
2、实现代码
#!/usr/bin/env python
#_*_ coding:utf-8 _*_
#encoding=utf-8
#function:
#created by shangshanyang
#date: 2019
import requests
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
#from bs4 import BeautifulSoup
LOGIN_URL = 'https://login.51job.com' #请求的登陆URL地址
DATA = {"lang": "c",
"action": "save",
"from_domain": "i",
"loginname": "shangshanyang",
"password":"123456",
"verifycode": ""} #Form Data 表单数据,登录系统的账号密码等
HEADER = { #"Host":"login.51job.com",
#"Referer": "https://login.51job.com/login.php?lang=c",
"User-Agent" : "User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" ,
}
def Get_Session(URL,DATA,HEADERS):
'''保存登录参数'''
ROOM_SESSION = requests.session()
ROOM_SESSION.post(URL,data =DATA,headers=HEADERS,verify=False)
return ROOM_SESSION
SESSION =Get_Session(LOGIN_URL,DATA,HEADER)
urlimage="http://i.51job.com/resume/ajax/image.php?type=avatar&userid=306511370"#图片地址
RES2 = SESSION.get(urlimage)
print(RES2.status_code)
if RES2.status_code == 200:
if RES2.text:
print(RES2.text)
with open('image2.jpg', 'wb') as f:#保存图片
for chunk in RES2:
f.write(chunk)
else:
print('图片不存在')
else:
print('地址错误')
SESSION.close()
二、urllib 实现下载网页及显示下载进度
#!/usr/bin/env python
#_*_ coding:utf-8 _*_
#encoding=utf-8
#function:
#created by shangshanyang
#date: 2019
import sys
import urllib
"""########################################
def callback(blocknum, blocksize, totalsize):
'''
下载进度
:param blocknum: 到目前为止一共传递的数据快数
:param blocksize:为一个数据快的大小,单位是byte
:param totalsize:远程文件的大小,可能为-1
:return:
'''
download_peocess=100.0*blocknum*blocksize/totalsize
if download_peocess >100:
download_peocess=100
if download_peocess<100:
print ">"*blocknum,
else:print "%.2f%%"%download_peocess
url="http://www.163.com/"
urllib.urlretrieve(url,'163.html',callback)#下载url,并保存为163.html,callback为回调函数,打印下载进度
"""##########################################
#"""#字符集检测
import chardet#字符检测模块,pip安装
def charset_detect(url):
'''字符集检测'''
html=urllib.urlopen(url)
content=html.read()
html.close()
charset=chardet.detect(content)['encoding']
return charset
#print charset_detect(url)
url="http://www.163.com/"
html=urllib.urlopen(url)
char_set=charset_detect(url)
print (char_set)
if 'utf' in char_set.lower():
print(html.read())
elif 'gb' in char_set.lower():
print(html.read().decode('gbk').encode("utf-8"))
else:
try:
print(html.read().decode(char_set).encode("utf-8"))
except Exception as e:
print(html.read().encode("utf-8"))
html.close()
#"""
#############################
# url="http://www.163.com/"
# html=urllib.urlopen(url)
# print(html.getcode())
# print(html.geturl())
# print(html.info().getparam("charset"))
# print(html.read().decode('gbk').encode("utf-8"))
# html.close()
三、urllib2 模拟用户浏览行为,下载禁止爬虫的网页
#!/usr/bin/env python
#_*_ coding:utf-8 _*_
#encoding=utf-8
#function:
#created by shangshanyang
#date: 2019
import urllib2
import random
user_agent=['Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'User-Agent:Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)',
'MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1',
]
def get_content(url,user_agent):
'''
获取403的页面(模拟用户请求获取禁止爬虫的页面)
:param url:访问的地址
:param user_agent:模拟的用户User-Agent列表
:return:
'''
HEADERS={"Host":"login.51job.com",
"GET":url,
"Referer":"https://www.51job.com/",#要访问的url来自于Referer页面上的链接
"User-Agent":random.choice(user_agent)
}
req=urllib2.Request(url,headers=HEADERS)
html=urllib2.urlopen(req)
content=html.read()
return content
url="https://login.51job.com/login.php"
for i in range(100):
html=get_content(url,user_agent)
print html.decode('gbk').encode('utf-8')
'''
req.add_header("Host","login.51job.com")
req.add_header("GET","https://login.51job.com/login.php")
req.add_header("Referer", "https://www.51job.com/")
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36")
'''
四、urllib 爬取百度贴吧照片
#!/usr/bin/env python
#_*_ coding:utf-8 _*_
#encoding=utf-8
#function:
#created by shangshanyang
#date: 2019
import re
import urllib
def get_html_content(url):
'''d获网页内容取'''
html=urllib.urlopen(url)
content=html.read()
html.close()
return content
def down_images(html_content):
'''
<img class="BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=269396684d4a20a4311e3ccfa0539847/0aa95edf8db1cb132cd1f269df54564e92584b15.jpg" pic_ext="jpeg" width="510" height="765">
:param html_content:
:return:
'''
regx=r'class="BDE_Image" src="(.+?.jpg)"'#(.+?.jpg)为匹配到的内容
compile_regx=re.compile(regx)
images_url_list=re.findall(compile_regx,html_content)
for image_url in images_url_list:
print image_url
image_name=image_url.split('/')[-1]
urllib.urlretrieve(image_url,r'C:UsersAdministratorDesktopyunphotos\%s'%image_name)#下载,保存
url='https://tieba.baidu.com/p/2772656630'
html_content=get_html_content(url)
down_images(html_content)
#print (get_content(url))
五、BeautifulSoup爬取百度贴吧照片
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
#!/usr/bin/env python
#_*_ coding:utf-8 _*_
#encoding=utf-8
#function:
#created by shangshanyang
#date: 2019
from bs4 import BeautifulSoup
import urllib
def get_html_content(url):
'''d获网页内容取'''
html=urllib.urlopen(url)
content=html.read()
html.close()
return content
def down_images(html_content):
'''
<img class="BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=269396684d4a20a4311e3ccfa0539847/0aa95edf8db1cb132cd1f269df54564e92584b15.jpg" pic_ext="jpeg" width="510" height="765">
:param html_content:
:return:
'''
soup=BeautifulSoup(html_content,'html.parser')
images_url_list=soup.find_all('img',class_="BDE_Image")
for image_url in images_url_list:
url_image=image_url['src']
print(url_image)
image_name = url_image.split('/')[-1]
urllib.urlretrieve(url_image, r'C:UsersAdministratorDesktopyunphotos\%s' % image_name) # 下载,保存
url='https://tieba.baidu.com/p/2772656630'
html_content=get_html_content(url)
down_images(html_content)