本次要采集的是蚂蜂窝法国游记下面的全部3000篇游记http://www.mafengwo.cn/travel-scenic-spot/mafengwo/10171.html
首先从需要采集的网页来看,URL并不是有规律的,这时候需要得到一个URL目录就使用Fiddle抓包进行分析,
 在切换页面的时候可以看到获取当前页码的所有游记(一页十条)的列表如下所示:
在切换页面的时候可以看到获取当前页码的所有游记(一页十条)的列表如下所示:
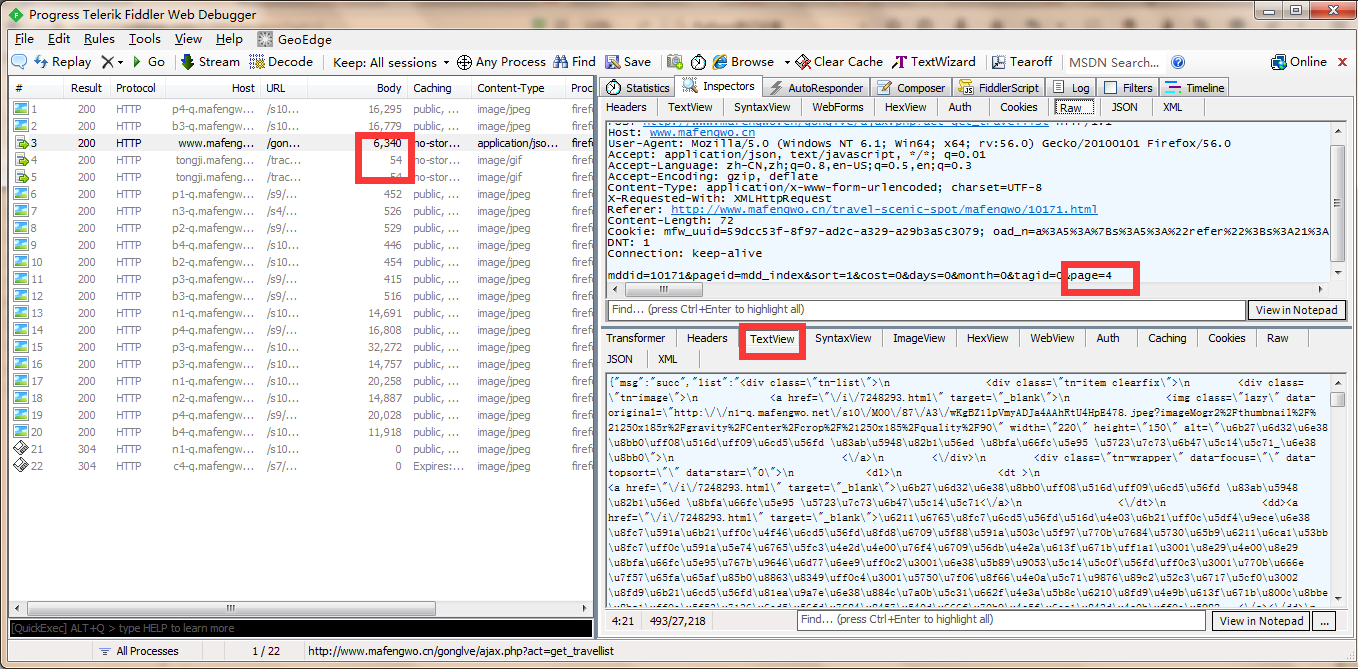
通过遍历data里面的page参数发送POST请求,就可以得到所有的目录页面,然后通过正则提取出待爬取的URL。
最后遍历待爬取的URL列表就可以获取游记的内容了。