一、Redis是什么?
Remote Dictionary Server(Redis) 是一个开源的、 C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库(NO-SQL数据库),并提供多种语言的API。它通常被称为数据结构服务器,因为值(value)可以是 字符串(String)、 哈希(Hash)、列表(list)、 集合(sets) 、有序集合(sorted sets)、Bit arrays(位数组)、HyperLogLogs、Streams类型。
二、Redis优点
- 读写性能优异:Redis的数据存在内存 ,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向
- 支持数据的持久化:支持 AOF 和 RDB 两种持久化方式,Redis为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘,重启的时候可以再次加载进行使用。
- 数据类型丰富:Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- 支持主从复制master-slave:主机会自动将数据同步到从机,可以进行读写分离。
- 单线程:避免了频繁的上下文切换。
- 数据自动过期:有了过期机制就能实现很多跟时间相关的功能。
- 发布订阅:发布订阅其作用是为了减少依赖关系,通常也叫观察者模式。主要是把耦合点单独抽离出来作为第三方,隔离易变化的发送方和接收方。发送方:只负责向第三方发送消息(杂志社把读者杂志交给邮局);接收方:被动接收消息(1:向邮局订阅读者杂志,2:去门口接邮过来的杂志);第三方:存储订阅杂志的接收方,并在杂志过来时送给接收方 (邮局)。
- 分布式集群:当业务量、数据量增加时,可以通过任意增加减少服务器数量来解决问题,分布式集群。
- 支持事务:Redis 的所有操作都是原子性的,同时 Redis 还支持对几个操作合并后的原子性执行。所谓的原子性就是对数据的更改要么全部执行,要么全部不执行。
三、Redis的缺点
- 容量受到物理内存的限制,不能用作海量数据的高性能读写,因此 Redis 适合的场景主要局限在较小数据量的高性能操作和运算上。
- 不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的 IP 才能恢复。
- 主机宕机,宕机前有部分数据未能及时同步到从机,切换 IP 后还会引入数据不一致的问题,降低了 系统的可用性。
- 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费。
四、为什么使用Redis
-
高性能
- 传统的关系型数据库如Mysql已经不能适用所有的场景了,比如秒杀的库存扣减,APP首页的访问流量高峰等等,都很容易把数据库打崩,所以引入了缓存中间件,目前市面上比较常用的缓存中间件有Redis 和 Memcached。
- 在日常的 Web 应用对数据库的访问中,读操作的次数远超写操作。当我们使用 SQL 语句去数据库进行读操作时,数据库就会去磁盘把对应的数据取回来,这是一个相对较慢的过程。如果我们把数据放在 Redis 中,也就是直接放在内存之中,让服务端直接去读取内存中的数据,那么这样速度明显就会快上不少 (高性能),
-
高并发
- 让服务端直接去读取内存中的数据会极大减小数据库的压力 (特别是在高并发情况下)。
综合来说使用Redis的主要目的就是为了高性能和高并发。注意:使用内存进行数据存储开销也是比较大的,限于成本的原因,一般我们只是使用 Redis 存储一些 高并发且不经常变动数据的读写,比如用户登录的信息等。一般而言在使用 Redis 进行存储的时候,我们需要从以下几个方面来考虑:
- 业务数据常用吗?命中率如何? 如果命中率很低,就没有必要写入缓存;
- 该业务数据是读操作多,还是写操作多? 如果写操作多,频繁需要写入数据库,也没有必要使用缓存;
- 业务数据大小如何? 如果要存储几百兆字节的文件,会给缓存带来很大的压力,这样也没有必要;
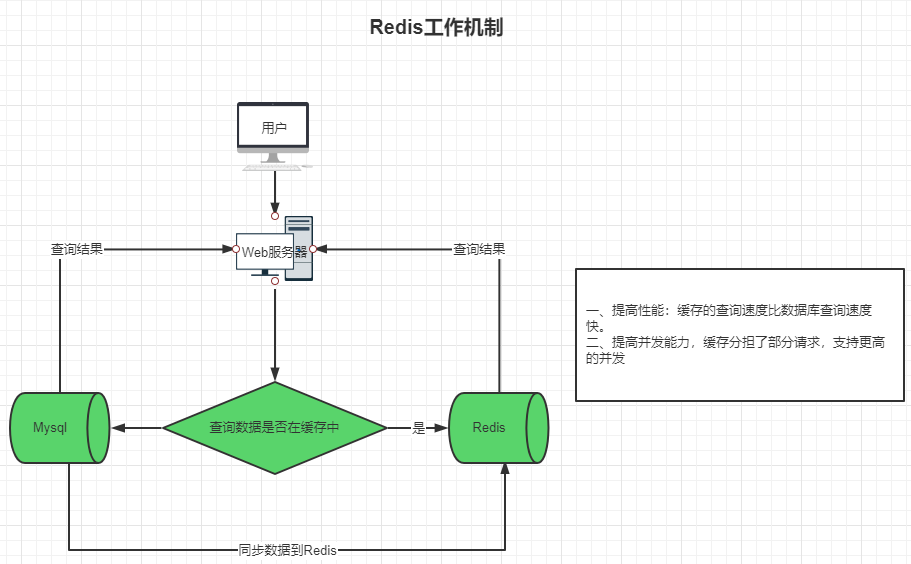
五、使用缓存会出现什么问题?
一般来说有如下几个问题
- 缓存雪崩问题;
- 缓存穿透问题;
- 缓存和数据库双写一致性问题;
1、缓存雪崩问题
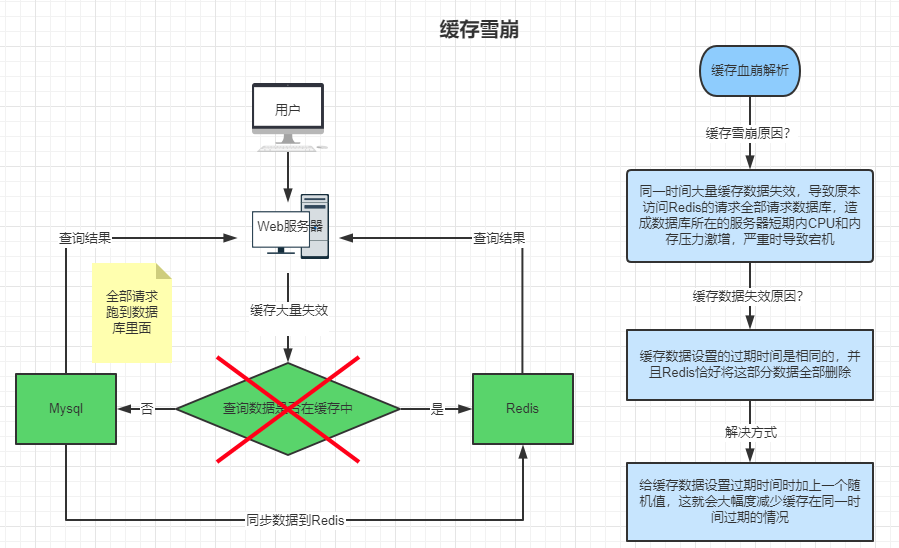
另外对于 "Redis 挂掉了,请求全部走数据库" 这样的情况,我们还可以有如下的思路:
- 事发前:实现 Redis 的高可用(主从架构 + Sentinel 或者 Redis Cluster),尽量避免 Redis 挂掉这种情况发生。
- 事发中:万一 Redis 真的挂了,我们可以设置本地缓存(MemoryCache) + 限流(hystrix),尽量避免我们的数据库被干掉
- 事发后:Redis 持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
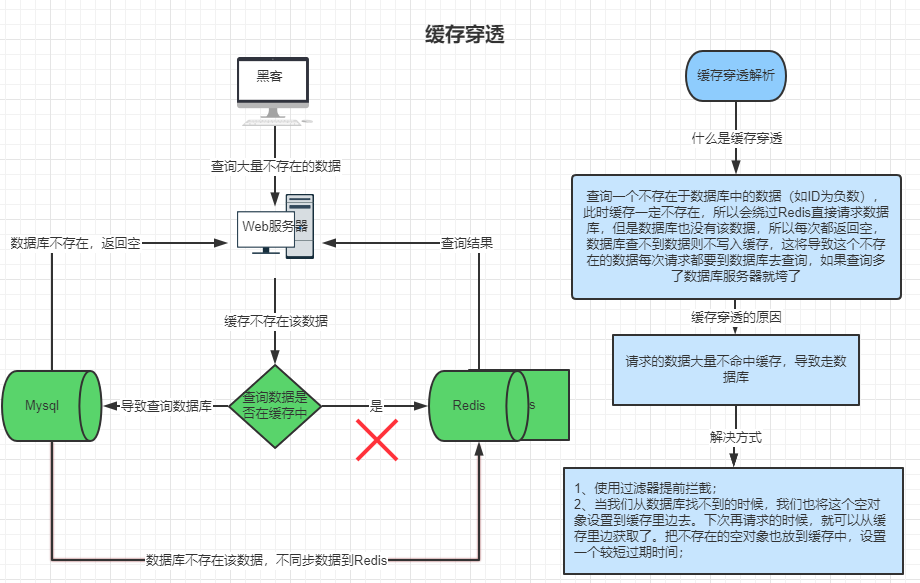
2、缓存穿透问题
3、缓存与数据库双写一致问题
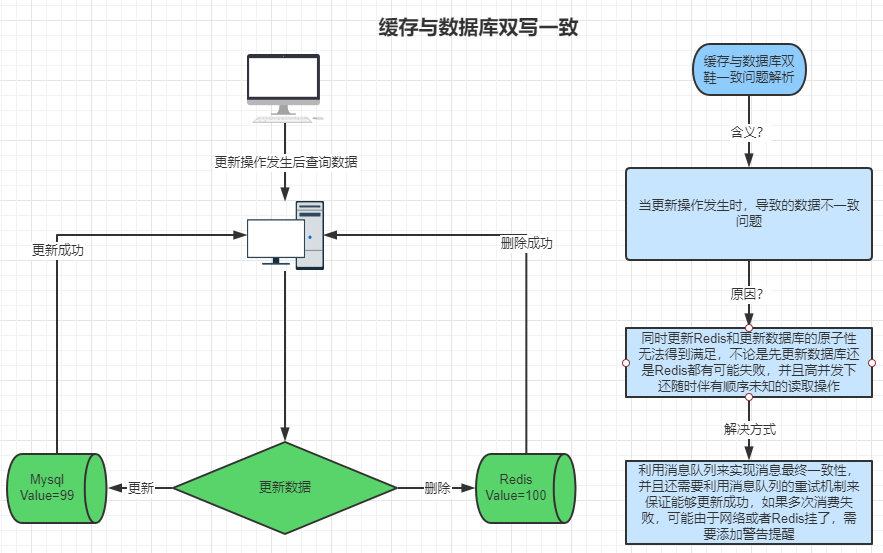
(1)什么是缓存与数据库双写一致问题?
因为一些读写操作导致数据库和缓存的数据不一致的情况

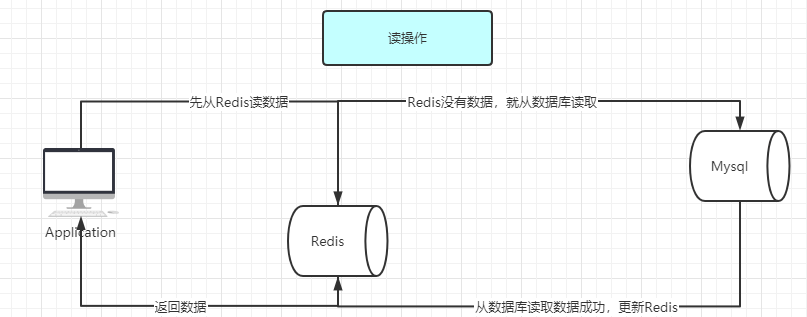
(2)对于读操作,流程是这样的
一般我们对读操作的时候有这么一个固定的套路:
-
如果我们的数据在缓存里边有,那么就直接取缓存的。
-
如果缓存里没有我们想要的数据,我们会先去查询数据库,然后将数据库查出来的数据写到缓存中。
-
最后将数据返回给请求
如果仅仅查询的话,缓存的数据和数据库的数据是没问题的。从理论上说,只要我们设置了键的过期时间,我们就能保证缓存和数据库的数据最终是一致的。因为只要缓存数据过期了,就会被删除。随后读的时候,因为缓存里没有,就可以查数据库的数据,然后将数据库查出来的数据写入到缓存中。但是,当我们要更新时候呢?各种情况很可能就造成数据库和缓存的数据不一致了。
(3)对于更新操作
一般来说,执行更新操作时,我们会有两种选择:
-
先操作数据库,再操作缓存
-
先操作缓存,再操作数据库
首先,要明确的是,无论我们选择哪个,我们都希望这两个操作要么同时成功,要么同时失败。所以,这会演变成一个分布式事务的问题。所以如果原子性被破坏了,可能会有以下的情况:
-
操作数据库成功了,操作缓存失败了。
-
操作缓存成功了,操作数据库失败了。
如果第一步已经失败了,我们直接返回Exception出去就好了,第二步根本不会执行。
下面我们具体来分析一下
A、操作缓存
操作缓存也有两种方案:
-
更新缓存
-
删除缓存
一般我们都是采取删除缓存缓存策略的,原因如下:
-
高并发环境下,无论是先操作数据库还是后操作数据库而言,如果更新缓存,那就更加容易导致数据库与缓存数据不一致问题。
-
如果每次更新了数据库,都要更新缓存【这里指的是频繁更新的场景,这会耗费一定的性能】,倒不如直接删除掉。等再次读取时,缓存里没有,那我到数据库找,在数据库找到再写到缓存里边。基于这两点,对于缓存在更新时,都是建议执行删除操作!
B、先更新数据库,再删除缓存
正常的情况是这样的:
-
先操作数据库,成功;
-
再删除缓存,也成功;

对于上述这种策略,其实是一种设计模式:Cache Aside Pattern(旁路缓存),但是如果原子性被破坏了:
-
第一步成功(操作数据库),第二步失败(删除缓存),会导致数据库里是新数据,而缓存里是旧数据。
-
如果第一步(操作数据库)就失败了,我们可以直接返回错误(Exception),不会出现数据不一致。
如果在高并发的场景下,出现数据库与缓存数据不一致的概率特别低,也不是没有:
-
缓存刚好失效
-
线程A查询数据库,得一个旧值
-
线程B将新值写入数据库
-
线程B删除缓存
-
线程A将查到的旧值写入缓存
要达成上述情况,还是说一句概率特别低:
因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
先修改数据库,再删除缓存,删除缓存失败的解决思路:
-
将需要删除的key发送到消息队列中
-
自己消费消息,获得需要删除的key
-
不断重试删除操作,直到成功
C、先删除缓存,再更新数据库
正常情况是这样的:
-
先删除缓存,成功;
-
再更新数据库,也成功;
如果原子性被破坏了:
-
第一步成功(删除缓存),第二步失败(更新数据库),数据库和缓存的数据还是一致的。
-
如果第一步(删除缓存)就失败了,我们可以直接返回错误(Exception),数据库和缓存的数据还是一致的。
看起来是很美好,但是我们在并发场景下分析一下,就知道还是有问题的了:
-
线程A删除了缓存
-
线程B查询,发现缓存已不存在
-
线程B去数据库查询得到旧值
-
线程B将旧值写入缓存
-
线程A将新值写入数据库
所以也会导致数据库和缓存不一致的问题。
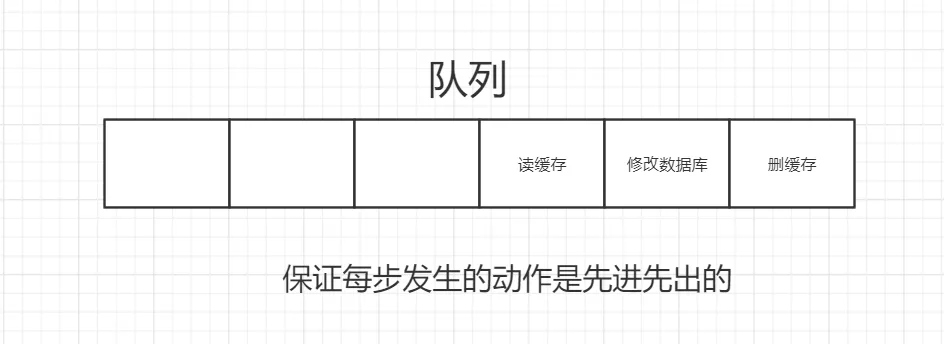
D、并发下解决数据库与缓存不一致的思路:
-
将删除缓存、修改数据库、读取缓存等的操作积压到队列里边,实现串行化。
我们可以发现,两种策略各自有优缺点:
-
先删除缓存,再更新数据库:在高并发下表现不如意,在原子性被破坏时表现优异
-
先更新数据库,再删除缓存(
Cache Aside Pattern设计模式):在高并发下表现优异,在原子性被破坏时表现不如意
六、Redis是单线程还是多线程
这个问题要从多个方面回答,如果仅仅只回答 "单线程" 肯定是说不过去的。Redis 确实是单线程模型,指的是执行 Redis 命令的核心模块是单线程的,而不是整个 Redis 实例就一个线程,Redis 其他模块还有各自模块的线程的。下面这个解释比较好:

Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器。它的组成结构为4部分:多个套接字、IO多路复用程序、文件事件分派器、事件处理器。因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型。一般来说 Redis 的瓶颈并不在 CPU,而在内存和网络。如果要使用 CPU 多核,可以搭建多个 Redis 实例来解决。
1、Reactor设计模式
Reactor 设计模式是一种事件驱动的设计模式,分发器(Dispatcher)使用多路分配器(Demultiplexer)监听多个客户端请求,当请求事件(Events)发生,分发器(Dispatcher)将一个或者多个客户端请求(Events)分发到不同的处理器(Event Handler)上,提升事件处理的效率。下图为Reactor设计模式类图:

2、IO多路复用技术
基于Reactor设计模式实现的IO多路复用
- 首先,IO多路复用程序监听多个套接字(Socket)
- 其次,当套接字进行了读写操作时,IO多路复用程序分发到各个不同的事件处理器上
- 然后,各个事件处理器处理后返回给IO多路复用程序
- 最后,IO多路复用程序返回结果给套接字
IO多路复用技术架构图如下

- 这里的IO多路复用程序即包含监听套接字的模块,也包含分发器模块。
- IO多路复用,IO指的就是网络连接或套接字Socket;多个就是多个网络连接;复用指使用一个IO多路复用程序。
4、Redis6.0之后的多线程
其实,Redis 4.0 开始就有多线程的概念了,比如 Redis 通过多线程方式在后台删除对象、以及通过 Redis 模块实现的阻塞命令等。来源官方的解释:

Redis 6 正式发布了,其中有一个是被说了很久的多线程IO:

这个 Theaded IO 指的是在网络 IO 处理方面上了多线程,如网络数据的读写和协议解析等,需要注意的是,执行命令的核心模块还是单线程的。Redis多线程只用来处理网络数据的读写和协议解析,命令的执行仍旧是单线程。这样的设计改变是为了不想让Redis因为引入多线程变得复杂。而且过去单线程的使用主要考虑CPU不是Redis的瓶颈,不需要多条线程并发执行,所以多线程模型带来的性能提升不能抵消它带来的开发和维护成本。而现在引入多线程模型解决的是网络IO操作的性能瓶颈。对于Redis基于内存的操作,仍然是很快的,而有时IO操作阻塞会影响着之后操作的效率。改为多线程并发进行IO操作,然后交由主线程进行内存操作,这样可以更好的缓解IO操作带来的性能瓶颈。架构如下图:

七、Redis早期为什么使用单线程
前边也说了,随着Redis版本的更新,Redis在网络IO处理方面引入了多线程,但是执行命令的核心模块仍然是单线程的,不要混淆。那么早期Redis为什么使用单线程呢?
- 因为 Redis 是基于内存的操作,CPU 不是 Redis 的瓶颈,Redis 的瓶颈最有可能是 机器内存的大小 或者 网络带宽。既然单线程容易实现,而且 CPU 不会成为瓶颈,那就顺理成章地采用单线程的方案了。
- 使用单线程模型能带来更好的 可维护性,方便开发和调试;
- 使用单线程模型也能 并发 的处理客户端的请求;(I/O 多路复用机制)
- Redis 服务中运行的绝大多数操作的 性能瓶颈都不是 CPU;
八、Redis为什么网络处理要引入多线程
Redis 的瓶颈并不在 CPU,而在内存和网络。内存不够的话,可以加内存或者做数据结构优化和其他优化等,但网络的性能优化才是大头,网络 IO 的读写在 Redis 整个执行期间占用了大部分的 CPU 时间,如果把网络处理这部分做成多线程处理方式,那对整个 Redis 的性能会有很大的提升。Redis 在网络处理方面上了多线程确实会让 Redis 性能上一个新台阶。目前 6.0 版本中,IO 多线程处理模式默认是不开启的,需要去配置文件中开启并配置线程数。
九、Redis为什么这么快
- 纯内存操作:读取不需要进行磁盘 I/O,所以比传统数据库要快上不少;
- 单线程,无锁竞争:这保证了没有线程的上下文切换,不会因为多线程的一些操作而降低性能;
- 多路 I/O 复用模型,非阻塞 I/O:采用多路 I/O 复用技术可以让单个线程高效的处理多个网络连接请求(尽量减少网络 IO 的时间消耗);
- 高效的数据结构,加上底层做了大量优化:Redis 对于底层的数据结构和内存占用做了大量的优化,例如不同长度的字符串使用不同的结构体表示,HyperLogLog 的密集型存储结构等等;