写在最最前边:
其实只需要把Matplotlib当成一种工具来使用,不必深究,只要能够会调用画出自己想要的效果图来显示一下就perfect了。嗯哼
Matplotlib概述:
Matplotlib 是一个Python的2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。
写在前边:
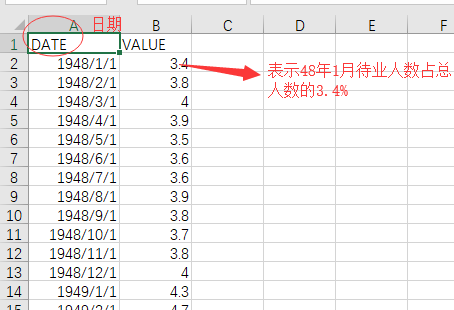
数据"UNRATE.csv"是统计的美国从1948年开始每个月中 待业人数占总人数的百分之几。
1.折线图的绘制
.plot()是用来❀折线图的。
要求:用折线图绘制出1948年的12个月中待业人数的情况。
用.to_datetime()标准化日期的格式:
在开始✿画折线图之前,我们观察了一下数据,发现"UNRATE.csv"数据中的"DATE"的显示格式是1948/1/1,用斜杠分割日期看起来不怎么样,还是转换一下好了,那用什么进行转换呢?
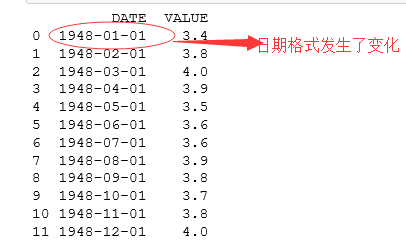
在Pandas有一个函数pd.to_datetime()可以把日期转化成为标准的1948-01-01的格式。
import pandas as pd
unrate = pd.read_csv("unrate.csv") #读取数据文件并赋值给变量unrate
unrate["DATE"] = pd.to_datetime(unrate["DATE"]) #将数据中1948/1/1这样的日期格式转化成标准的日期格式
print(unrate.head(12)) #打印数据的前12行
运行结果:
1.1 初始化plot()
使用不同的pyplot函数,我们可以创建、定制和显示一个plot
import matplotlib.pyplot as plt #引进绘图的matplotlib库,并别名为plt
#使用不同的pyplot函数,我们可以创建、定制和显示一个plot。
plt.plot() #先不给.plot()添加参数,看一下效果
plt.show() #显示
运行结果:
1.2 给plot(A,B)添加参数
先通过切片的方式取出数据集中的前12条数据,即1948年12个月的待业率数据。
在接下来会给plot()添加两个参数,第一个参数作为折线图的x轴数据,第二个参数作为折线图的y轴参数。
first_twelve = unrate[0:12] #通过切片[0:12]取出DataFrame类型的变量unrate的前12行数据
#fiest_twelve数据是由12行的“DATE”和“VALUE”组成的
#添加.plot()的参数,第一个参数作为x轴数据(日期),第二个参数作为y轴数据(待业率),
plt.plot(first_twelve["DATE"],first_twelve["VALUE"])
plt.show() #显示
运行结果:
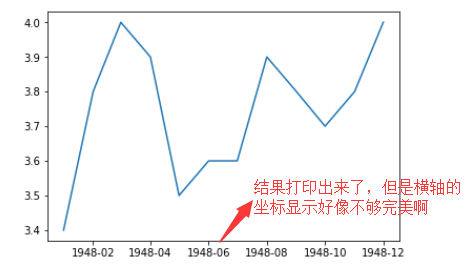
1.3 用.xticks()调整x坐标的显示方式
plt.xticks(rotation = 45) #把x轴的坐标显示成45度角的样子
其中rotation = ?, 等于多少就倾斜多少度
plt.plot(first_twelve["DATE"],first_twelve["VALUE"])
plt.xticks(rotation = 45) #把x轴的坐标显示成45度角的样子
plt.yticks(rotation = 45) #同样y轴也有这样的操作
plt.show()
运行结果:
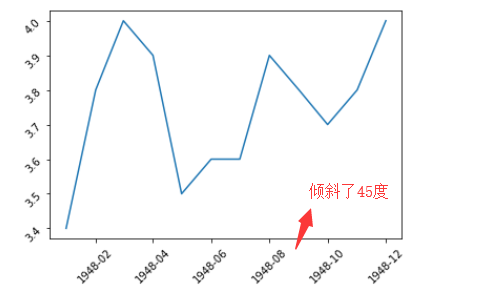
1.4 用.xlabel()给x轴加标签,.ylabel()给y轴加标签,.title()给图加标题
plt.plot(first_twelve["DATE"],first_twelve["VALUE"])
plt.xticks(rotation = 45) #把x轴的坐标显示成45度角的样子
plt.xlabel("Month") #给x轴加标签
plt.ylabel("Unemployment Rate") #给y轴加标签
plt.title("Monthly Unemployment Trends,1948") #给图加标题
plt.show()
运行结果:
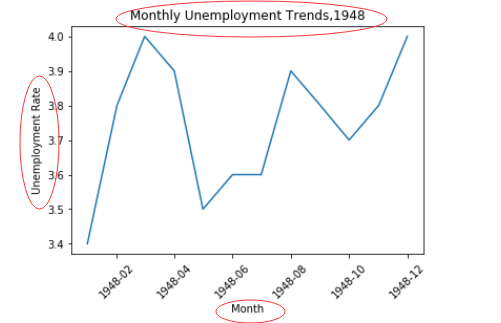
2 子图的绘制
有时候我们需要在一个区域里画多个图,相当于子图的形状。做常用于论文。
在一个区域里想统计很多的指标,而这很多个指标没办法放在一个图中,所以需要画多个子图,如下边这样子的罗列。
那么添加子图需要用的函数是:
add_subplot(a,b,c) 参数a:区域中子图的行数为a
参数b:区域中子图的列数为b (则本区域中子图的总个数是a×b个)
参数c:要添加的单个子图在区域中的第几个 (排列编号为从左到右,从上到下)

2.1 初始化般的子图
plt.figure() 函数作用:要画子图,就要指定画图的区域,此函数就是用来指定画图的区域的,当其没有参数的时候,表示指定默认画图区域。
import matplotlib.pyplot as plt #引进绘图的matplotlib库,并别名为plt
#画子图
fig = plt.figure() #.figure()没有参数,指定默认画图的区间,理解为定义画图区域
#通过add_subplot()的参数可以看出,子图是两行两列的,第一个参数表示行,第二个参数表示列
#第三个参数表示图中的一个子图在整个图中的位置(希望我说的清楚)
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,4)
plt.show()
运行结果:
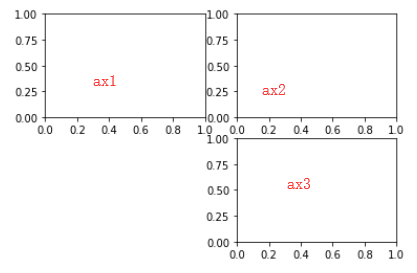
2.2 随机在子图是画些什么吧
在2.1 中只是初始化了画图区域和其中的子图的框架,但并没有画任何东西,自然是要画一些什么的,那就用随机画法随便来点什么吧
plt.figure(figsize = (a,b))
figure(参数) 有参数的时候就不再是指定一个默认的画图区域了
参数figsize是为了指定画图区域的大小,
第一个参数a指画图区域的长度为a个单位,第二个参数b是指画图区域的宽度为b个单位
import numpy as np
#fig = plt.figure()
fig = plt.figure(figsize = (6,3)) #.figure(参数)有参数的时候就不再是指定一个默认的画图区域了
#参数figsize是为了指定画图区域的大小,第一个参数指画图区域的长度,第二个参数是指画图区域的宽度
#在画图区域添加子图
ax1 = fig.add_subplot(2,1,1)
ax2 = fig.add_subplot(2,1,2)
ax1.plot(np.random.randint(1,5,5),np.arange(5)) #随机的画点东西
ax2.plot(np.arange(10)*3,np.arange(10))
plt.show()
运行结果:
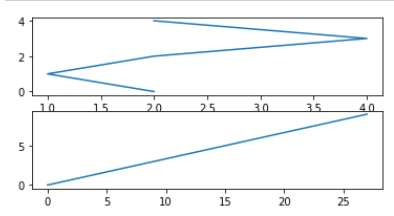
2.3 在一个图中画两条折线
在上边的小的程序段中,.plot() 一下就在在一张图上画了一条折线,但也只有一条。如果想在一张图上画上两条折线应该怎么做呢:当然是.plot()两下啦
还用上边美国待业率的数据集 .unrate.csv
注意: unrate["DATE"].dt.month #把所有数据集中的数据每12个数据进行了新的编码,用来区分每一年的12个月
我们知道DataFrame类型的变量unrate是.read_csv("unrate.csv")之后被赋值的,变量unrate的就是数据集中的数据。而unrate["DATE"]则是取数据中的“DATE”日期这一列的数据,用.dt.month对数据集中的每12个数据进行新的编码。运行效果图如下所示:

plt.plot(a,b,c)表示画折线: 参数a:表示把a作为x轴,
参数b:表示把b作为y轴
参数c:表示折线的颜色
针对数据集,对每一年的数据做一个折线统计会看出这一年的待业率的变化情况,现在是想在一个图中显示两条折线,那么我们就选取两年的数据为好,每一年的数据一共12行,unrate[0:12]用来取1948年的数据。unrate[0:12]["MONTH"]是把月份作为x轴,同理unrate[0:12]["VALUE"]是把待业率作为y轴
#在一个图中画两条线。——plot两次(还可指定不同的颜色)
unrate["MONTH"] = unrate["DATE"].dt.month #把所有数据集中的数据每12个数据进行了新的编码,用来区分每一年的12个月
#print(unrate["MONTH"])
fig = plt.figure(figsize = (6,3)) #指定画图区域大小,长6宽3
plt.plot(unrate[0:12]["MONTH"],unrate[0:12]["VALUE"],C = "red") #取重新编了码的数据的前12行,即一个年份的数据进行了绘制
#plot(a,b,c) 参数a:表示把a作为x轴,参数b:表示把b作为y轴,参数c:表示折线的颜色
plt.plot(unrate[12:24]["MONTH"],unrate[12:24]["VALUE"],C = "blue")
plt.show()
运行结果:
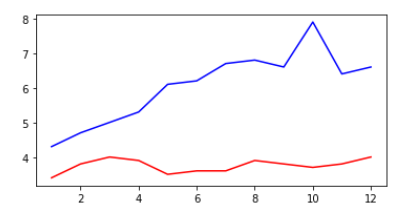
2.4 在一个图中画多条折线
如上边所示,在一个图上不但能够显示两条折线,当然也可以更多啦,那就是多plot()几次,但是作为一个计算机人,在多次重复同一操作的时候自然用到的应该是循环啊。
先定义一个关于颜色的list,以便于标注不同颜色的线。
colors = ["red","blue","green","orange","black"]
然后用for循环,循环的取不同年份的数据。
#用5种颜色画出5年的待业率数据,用循环
fig = plt.figure(figsize = (10,6))
colors = ["red","blue","green","orange","black"]
for i in range(5): #range----[0,1,2,3,4]
start_index = i*12 #当i = 0,数据子集subset去数据的[0:12]行 即1948年的数据
#当i = 1,数据子集subset去数据的[12:24]行 即1949年的数据
#........
##当i = 4,数据子集subset去数据的[48:60]行 即1952年的数据
end_index = (i+1)*12
subset = unrate[start_index:end_index]
plt.plot(subset["MONTH"],subset["VALUE"],c = colors[i]) #以”MONTH“为x轴。以"VALUE"为y轴,颜色也是循环list
plt.show()
运行结果:
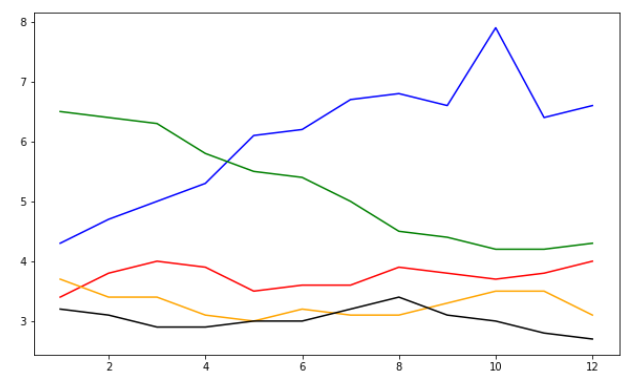
2.5 逐渐趋近完美的五线图
上边的五线图看着挺好看是吧,但是你能够分清那条颜色的线代表的哪一个年份的数据吗?很困难吧,除非你是一个一个在于颜色比对,那是不是能够让表示年份的信息与不同的颜色对比起来的信息放在图中啊?
就像下边这样。

这个东西啊,其实是由函数plt.legend(loc = "best")得到的。
plt.legend(loc = "best") 其中legengd的参数loc可以等于很多不同的值,利用print(help(plt.legend))来查阅一下帮助文档,发现:表示这个说明性的方块放在图中的位置。默认为best

当然了不但要显示,还要有显示的内容与什么有关,本例中显示的内容与年份有关,所以定义了label = (1948+i)
#用5种颜色画出5年的待业率数据,用循环
fig = plt.figure(figsize = (10,6))
colors = ["red","blue","green","orange","black"]
for i in range(5): #range----[0,1,2,3,4]
start_index = i*12 #当i = 0,数据子集subset去数据的[0:12]行 即1948年的数据
#当i = 1,数据子集subset去数据的[12:24]行 即1949年的数据
#........
##当i = 4,数据子集subset去数据的[48:60]行 即1952年的数据
end_index = (i+1)*12
subset = unrate[start_index:end_index]
label = str(1948 + i)
plt.plot(subset["MONTH"],subset["VALUE"],c = colors[i],label = label) #以”MONTH“为x轴。以"VALUE"为y轴,颜色也是循环list
plt.legend(loc = "best")
#print(help(plt.legend))
plt.show()
运行结果:
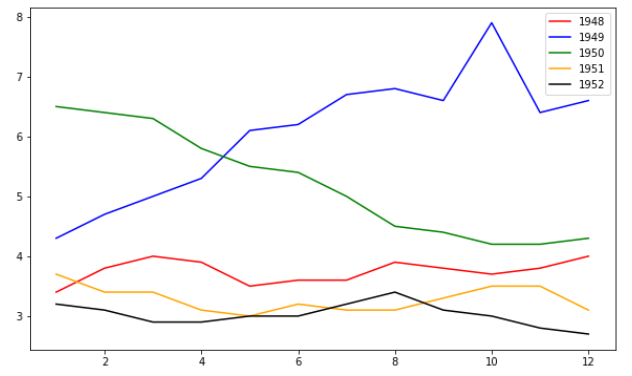
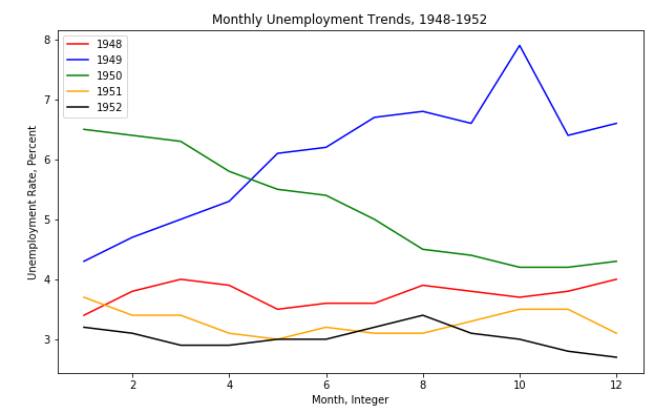
2.6 完美的五线图
如果你问我有比上边更完美的五线图吗?我一定会肯定的告诉你,有!!!!
那就是添加上一些说明信息,比如图的标题,还有横纵坐标的说明等。
#用5种颜色画出5年的待业率数据,用循环
fig = plt.figure(figsize = (10,6))
colors = ["red","blue","green","orange","black"]
for i in range(5): #range----[0,1,2,3,4]
start_index = i*12 #当i = 0,数据子集subset去数据的[0:12]行 即1948年的数据
#当i = 1,数据子集subset去数据的[12:24]行 即1949年的数据
#........
##当i = 4,数据子集subset去数据的[48:60]行 即1952年的数据
end_index = (i+1)*12
subset = unrate[start_index:end_index]
label = str(1948 + i)
plt.plot(subset["MONTH"],subset["VALUE"],c = colors[i],label = label) #以”MONTH“为x轴。以"VALUE"为y轴,颜色也是循环list
plt.legend(loc = "upper left")
plt.xlabel("Month, Integer")
plt.ylabel("Unemployment Rate, Percent")
plt.title("Monthly Unemployment Trends, 1948-1952")
plt.show()
运行结果: