拼接:"+"号(同类型可拼接)
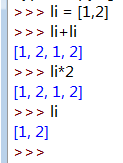
没有减号“-”,只有拼接"+"和重复"*"
一、字符串拼接
(一)."+"号
相同类型可用加号拼接,另外:据说SQL语句中用"+"号会很危险。
(二).%s
%s是占位符,从左到右一一对应。语法:"%s %s %s" % (s1,s2,s3)
(三).join(iterable)
括号中需要一个可迭代类型,有且只有一个参数。元素之间的拼接。
其中," ".join(iterable)遍历到最后一个元素不会加空格了,因为它是元素之间的拼接,同理于split()
(四).format()
大括号"{}"是占位符,是索引。语法:"{}{}".format(s1,s2)。大括号中默认索引是0,1,(索引可以换位置),索引的是format()小括号中的元素。也需要一一对应,要保证占位符能拿到值。
其中,"{}"里可以指定名称,通过后面format()小扩内赋值的方式把值给前面的占位符。
例:
s1 = "i" s2 = "love" s3 = "python" print("{c} {b} {a}".format(a=s1, b=s2, c=s3)) # 运行结果(相当于反向输出了) # python love i
补充:format()非常强大,可以这样玩:
# 语法:{:} print("{:.1f}".format(12.22)) # 12.2 # 同理于"%.1f",只是语法和书写格式不一样。 print("{:.2%}".format(0.2222)) # 22.22% # 格式化百分比 print("{:<10}".format(12)) # '12 ' # 输出占10位。尖尖向左,左对齐 print("{:*^10}".format(10)) # ****10**** # 脱字符"^",居中对齐,并且使用指定的"*"来填充

引用了:http://www.cnblogs.com/zhizhan/p/4883806.html
二、格式化输出
(一)."%s"格式化字符串

默认右对齐,15表示宽度,不足会用空格占位。
减号"-",用作于左对齐:

(二)."%d"格式化整数。

输出的也是个字符串。变成整数了,直接把小数删了。
(三)."%f"格式化小数。(m.n):m是宽度,n为小数,m大于格式化的数值的位数时才会显示。(小数位数默认是6位)

宽度6,小数2位。
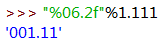
用0来填充。
另外,还有下面这么一个梗:
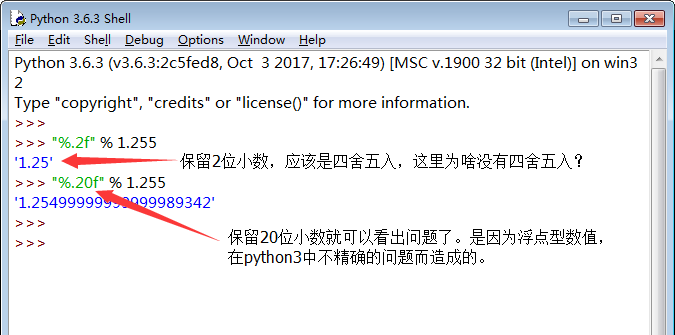
https://bugs.python.org/issue5118
一般实际应用中,小数保留1位来确保精度不丢失。
(四)."%c"格式化ASCII字符

字符转ASCII码的方案:ord()内置函数

(五)."%o"格式化八进制

(六)."%x"格式化十六进制

(七)."%e"科学计数法格式
1千2百亿用科学计数法来表示就很直观了,不加逗号隔开的情况下看这种长串数字就是受罪。
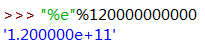
三、深浅复制
针对嵌套了列表才用的,因为列表是可变的。(这个点注意下,不然要陪80个亿)
除了copy.deepcopy()之外,其他的都是浅复制。
copy()和分片都是浅复制,只是复制表面,没法复制嵌套在里面的列表。而深复制是从里到外都复制了。
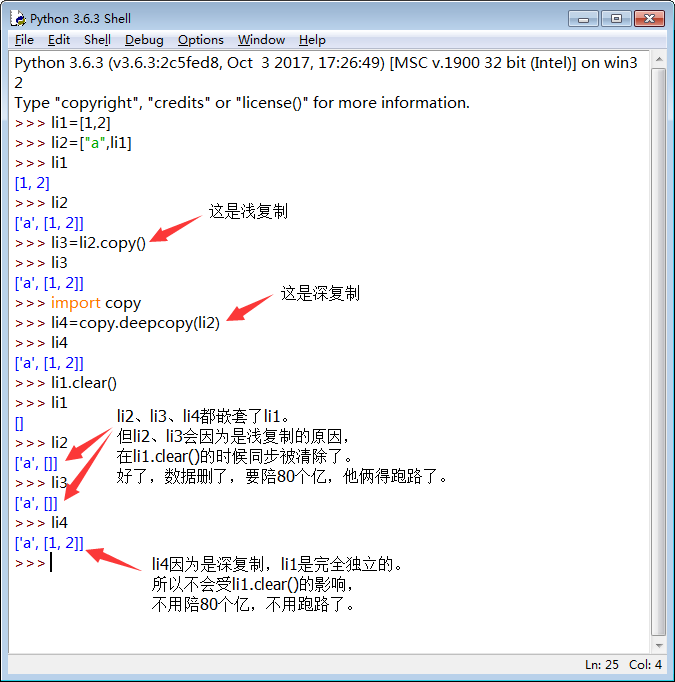
浅复制中列表会跟着变,而深复制不会变。
网上找来一个碾平list的方法,碾完了把这个新的list重新赋值给一个变量。这下再怎么倒腾都没事了。
b = ["o", "g", "s", "f", 1, 2] a = [1, "a", 2, [3, 4], ["c", ["d", "e", "f"]], [[5, 6], [7, 8]], b] # 碾平list flatten = lambda x: [y for l in x for y in flatten(l)] if type(x) is list else [x] a = flatten(a) print(a) # [1, 'a', 2, 3, 4, 'c', 'd', 'e', 'f', 5, 6, 7, 8, 'o', 'g', 's', 'f', 1, 2]
四、f-strings
f字符串,也被称呼为:格式化的字符串文字(formatted string literals),是Python3.6开始引入的一种新的字符串格式化方式,最终会是一个字符串。性能也是目前为止最好的。
(一).最基本的例子
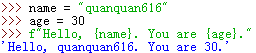
(1).大括号中必须要有合法的表达式!不然就会报语法错误:SyntaxError: f-string: empty expression not allowed(空表达式不被允许)
(2).其中,f大写形式也可以。
(二).任意表达式均可以在f-string中实现
(1).直接进行运算

(2).调用自定义方法


def to_upper_case(case): return case.upper() name = "quanquan616" print(f"{to_upper_case(name)} is funny.") # QUANQUAN616 is funny.
也可以直接调用:
name = "quanquan616" print(f"{name.upper()} is funny.") # QUANQUAN616 is funny.
(3).创建的类对象中带有f-strings
示例如下:
class Comedian: def __init__(self, first_name, last_name, age): self.first_name = first_name self.last_name = last_name self.age = age def __str__(self): return f"{self.first_name} {self.last_name} is {self.age}." def __repr__(self): return f"{self.first_name} {self.last_name} is {self.age}. Surprise!" new_comedian = Comedian("Eric", "Idle", "74") print(f"{new_comedian}") # Eric Idle is 74.
此例中,__str__()和__repr__()方法用来呈现字符串,在类定义中至少包含其中一个方法,请使用__repr__(),因为它可以用来代替__str__()
__str__()返回的是非正式的字符串表示形式,应该具有可读性。__repr__()返回的字符串是官方表示,应该是明确的。调用str()和repr()比直接使用__str__()和__repr__()更好。
默认情况下,f-strings使用__str__()。但如果包含转换标志 !r ,就会使用__repr__()
print(f"{new_comedian!r}") # Eric Idle is 74. Surprise!
(三).多行f-strings
多行字符串前,都需要放置一个"f",如下正确演示:

否则的话,如下错误演示就会出问题:

技巧1
>>> f"{18446744073709551615:,}" '18,446,744,073,709,551,615'
小练习:
# 1.用4种方法,将列表li = ['I','python','like'],里面的单词拼成: I**like**python li = ['I', 'python', 'like'] # 1 print(li[0] + "**" + li[2] + "**" + li[1]) # 2 print("%s**%s**%s" % (li[0], li[2], li[1])) # 3 print("**".join([li[0], li[2], li[1]])) # 4 print("{}**{}**{}".format(li[0], li[2], li[1])) print("{0[0]}**{0[2]}**{0[1]}".format(li)) # 索引方式
# 2. a=1.2,分别用3种格式,输出a: ''' 1.字符串格式, 2.整型格式, 3.浮点型: 输出占10位、保留2位小数 、带加号、靠左端 ''' a = 1.2 # 1 print("%s" % a) # 2 print("%d" % a) # 3 print("%+-10.2f" % a)
# 3. print('aa bb') 如何输出,结果为: aa bb # print('aa bb') print('aa\tbb') print(r'aa bb')