简介
tornado没有像Django那样提供了内建的ORM,需要使用第三方的SQLAlchemy来实现。
ORM全称:Object Relational Mapping 对象关系映射
好处:通过ORM可以不用关心后台是使用的哪种数据库,只需要按照ORM所提供的语法规则去书写相应的代码,ORM就会自动转换成对应的数据库SQL语句。
SQLAlchemy不仅仅只是用于tornado开发,它可以用于任何ORM场合。
补充:
ORM叫对象关系映射,mysql是关系型数据库。而redis、mongodb它们是非关系数据库,以键值对形式表示数据,根本没有关系可言,所以没有ORM这一说法。
一、准备工作
1.安装好mysql
2.安装好所需的依赖:pymysql、sqlalchemy
二、SQLAlchemy连接数据库
(一).导包
from sqlalchemy import create_engine
(二).设置连接的参数
HOSTNAME = '127.0.0.1'
PORT = '3306'
DATABASE = 'mydb'
USERNAME = 'admin'
PASSWORD = 'Root110qwe'
(三).定义连接数据库的URL
db_url = 'mysql+pymysql://{}:{}@{}/{}?charset=utf8'.format(USERNAME,PASSWORD,HOSTNAME,DATABASE)
注意:顺序绝对不要弄错了,也不要有任何空格!解析是通过字符串分割的,有一个不对就报错。
(四).连接数据库
engine = create_engine(db_url)
(五).测试连接
connection = engine.connect()
result = connection.execute('select 1')
print(result.fetchone())
如有打印出了结果:"(1,)",那么就可以了。
(六).完整代码


# connect.py from sqlalchemy import create_engine HOSTNAME = '127.0.0.1' PORT = '3306' DATABASE = 'mydb' USERNAME = 'admin' PASSWORD = 'Root110qwe' db_url = 'mysql+pymysql://{}:{}@{}/{}?charset=utf8'.format(USERNAME,PASSWORD,HOSTNAME,DATABASE) engine = create_engine(db_url) connection = engine.connect() result = connection.execute('select 1') print(result.fetchone())
三、在数据库里面新建表
(一).创建Module的Base类
接上面connect.py中的代码,加入下面两行代码:
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base(engine)
对象关系型映射,数据库中的表与python中的类相对应,创建的类必须继承自sqlalchemy中的基类。
使用declarative方法定义的映射类依据一个基类,这个基类是维系类和数据表关系的目录。
应用通常只需要有一个Base的实例,declarative_base()功能创建一个基类。
(二).创建Module
from datetime import datetime from sqlalchemy import Column, Integer, String, DateTime from connect import Base class User(Base): __tablename__ = 'user' id = Column(Integer, primary_key=True, autoincrement=True) username = Column(String(20), nullable=False) password = Column(String(50)) creatime = Column(DateTime, default=datetime.now)
用类来表示数据库中的表,这些表的类都继承于我们的Base基类,在类里面我们定义一些属性,这个属性通过映射,就对应表里面的字段。
__tablename__ 是固定写法,表示要映射到数据库中的表名。绝对不能把这个单词写错了!
(三).映射到数据库中
Base.metadata.create_all()
执行此代码,就会把创建好的Module映射到数据库中
四、单表的增删改查
(一).创建会话
from sqlalchemy.orm import sessionmaker Session = sessionmaker(engine) session = Session()
对数据库的表进行增删改查之前,先需要建立会话,建立会话之后才能进行操作,就类似于文件要打开之后才能对文件内容操作
(二).add(增)
(1).添加一条数据
person = User(username='buodng', password='qwe123') session.add(person) session.commit()
(2).添加多条数据
session.add_all([User(username='tuple', password=2), User(username='which', password=3)])
(三).delete(删)
rows = session.query(User).filter(User.username=='budong')[0] print(rows) session.delete(rows) session.commit()
(四).update(改)
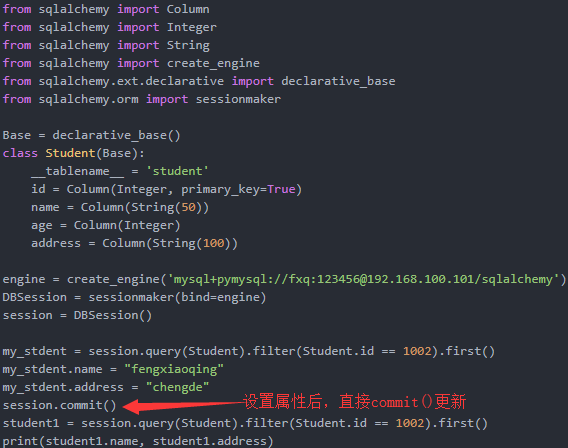
rows = session.query(User).filter(User.username=='budong').update({User.password:1}) session.commit()
(1).小技巧1
更新数据可以使用commit()方法,直接更新
(五).query(查)
rows = session.query(User).all()
rows = session.query(User).first()
query就是查询的意思,在SQLAlchemy中用来查询数据。
all()查询所有
first()查询第一条数据
(六).总结
除查询之外,其他的增删改都必须要手动调用session.commit()才能让数据生效!
五、查询深入篇-基本查询
(一).导库、导模块
from connect import session
from user_modules import User
(二).查询结果
(1).查询出来的是一个query对象
rs = session.query(User).filter(User.username == 'budong') print(rs, type(rs)) # 打印出了一条SQL语句
rs是一个query对象
使用SQLAlchemy时,如果想要查看最终在数据库中执行的sql,可以通过上述方式来查看
(2).all()
session.query(User).filter(User.username=='budong').all() 返回所有符合条件的数据
session.query(User.username).filter(User.username=='budong').all() 查询对象中的某个属性的值(对应为查询表中某个字段的值),返回的结果是一个列表
(3).first()
session.query(User).filter(User.username=='budong').first() 返回所有符合条件数据的第一条数据
session.query(User.username).filter(User.username=='budong').first() 返回的结果是一个元组
(4).[0]
session.query(User).filter(User.username=='budong')[0]
[0]和first()类似,但如果没有符合条件的数据则会报错
(5).取值方式
rs = session.query(User).filter(User.username=='budong').all()
有两种方式可以取到具体的数据值:
getattr(rs[0], 'username')
rs[0].username
(6).查询结果的总结
如果是整表查询则返回Module的一个实例;如果是查询某个属性,返回的则是具体的数据。
如果是Module实例,需要通过属性访问的方式取值。
六、查询深入篇-条件查询
(一).filter()
filter()是一个过滤函数,过滤条件都可以书写在此函数中,不同的条件之间用"逗号"分隔
session.query(User).filter(User.username=='budong').all()
(二).filter_by()
session.query(User).filter_by(username='budong').all()
(三).filter()和filter_by()之间的区别
(1).filter()中是双等号"==";而filter_by()中是单个等号"="
(2).filter()中需要添加"类对象",filter_by()不需要
(3).filter_by()中只能添加等于的条件,不能添加不等于、大于小于等条件,filter()没有这个限制
(四).like()和notlike()
like()是模糊查询,和数据库中的like用法一样,notlike和like作用相反
session.query(User.id).filter(User.username.like('budong%')).all()
session.query(User.id).filter(User.username.notlike('budong%')).all()
(五).in_和notin_
in_和notin_是范围查找
session.query(User.id).filter(User.username.in_(['budong', 'tuple'])).all()
session.query(User.id).filter(User.username.notin_(['budong', 'tuple'])).all()
(六).is_和isnot
is_和isnot是精确查找
session.query(User.id).filter(User.username.is_(None)).all()
session.query(User.id).filter(User.username.isnot(None)).all()
判断为空还可以使用:
session.query(User.id).filter(User.username==None).all()
(七).limit()
session.query(User.username).filter(User.username!='budong').limit(2).all() # 这里是查看前两条数据
(八).offset()
session.query(User.username).filter(User.username!='budong').offset(1).all() # 这里是偏移一条记录
(九).slice()
slice()对查询出来的数据进行切片取值
session.query(User.username).filter(User.username!='budong').slice(1,3).all()
(十).one()
one()查询一条数据,如果存在多条则报错
session.query(User.username).filter(User.username=='tuple').one()
(十一).order_by()
order_by()对查询出来的结果进行排序,默认是顺序
session.query(User.username).filter(User.username!='budong').order_by(User.id).all()
(十二).desc()
desc()是倒序排序
from sqlalchemy import desc # 使用desc()必须导入这个包
session.query(User.username).filter(User.username!='budong').order_by(desc(User.username)).all()
(十三).order_by()和limit()一起使用
session.query(User.username).filter(User.username!='budong').order_by(User.username).limit(3).all()
(十四).or_
或的意思,和数据库中的or一样
(1).导包
from sqlalchemy import or_
(2).session.query(User.username).filter(or_(User.username.isnot(None), User.password=='qwe123')).all()
七、查询深入篇-函数的使用
(一).导包
from sqlalchemy import func,extract
(二).func.count()和group_by()一起配合使用
session.query(User.password,func.count(User.id)).group_by(User.password).all()
group_by()和order_by()不需要导入,可以直接使用
(三).func.count()+group_by()+having()一起配合使用
session.query(User.password, func.count(User.id)).group_by(User.password).having(func.count(User.id)>1).all()
having()可以直接使用
(四).func.sum() 求和
session.query(User.password, func.sum(User.id)).group_by(User.password).all()
(五).func.max() 求最大值
session.query(User.password, func.max(User.id)).group_by(User.password).all()
(六).func.min() 求最小值
session.query(User.password, func.min(User.id)).group_by(User.password).all()
(七).extract()
(1).session.query(extract('minute',User.creatime).label('minute'), func.count(User.id)).group_by('minute').all()
extract()提取对象中的数据,这里提取分钟,并把提取出来的结果用label命名别名,之后就可以使用group_by()来分组
(2).session.query(extract('day',User.creatime).label('day'), func.count('*')).group_by('day').all()
count()里面同样可以使用星号"*"
八、多表查询
(一).新建一个Module
from sqlalchemy import ForeignKey class UserDetails(Base): __tablename__ = 'user_details' id = Column(Integer, primary_key=True, autoincrement=True) id_card = Column(Integer, nullable=True, unique=True) lost_login = Column(DateTime) login_num = Column(Integer, default=0) user_id = Column(Integer, ForeignKey('user.id')) def __repr__(self): return '<UserDetails(id=%s,id_card=%s,last_login=%s,login_num=%s,user_id=%s)>' % ( self.id, self.id_card, self.lost_login, self.login_num, self.user_id )
(二).cross join
session.query(UserDetails, User).filter(UserDetails.id==User.id).all()
(三).inner join
session.query(User.username,UserDetails.lost_login).join(UserDetails,UserDetails.id==User.id).all()
(四).left join
session.query(User.username,UserDetails.lost_login).outerjoin(UserDetails,UserDetails.id==User.id).all()
(五).union
union是联合查询,有自动去重的功能,对应的还有union_all
q1 = session.query(User.id) q2 = session.query(UserDetails.id) q1.union(q2).all()
(六).声明子表和使用
sql_0 = session.query(UserDetails.lost_login).subquery()
使用子表:
session.query(User, sql_0.c.lost_login).all()
九、原生SQL查询
(一).写好SQL语句
sql_1='''select * from `user`'''
(二).执行查询
row = session.execute(sql_1)
(三).取值
row.fetchone()
row.fetchmany()
row.fetchall()
(四).循环取值
for i in row:print(i)
十、表关系
(一).一对一表关系
(1).导入方法
from sqlalchemy.orm import relationship
(2).引入之前使用的两个模型:User和UserDetails
(3).在UserDetails中添加如下代码
userdetail = relationship('User',backref='details',uselist=False,cascade='all')
uselist=False 这里表示一对一的关系(默认值为True表示一对多)
(4).使用
rows = session.query(User).get(1)
rows.details
(5).对上述操作的分析
自动添加属性:
User本来是没有details这个属性的,但是在UserDetails里面添加relationship之后,User实例会自动加上details属性。
relationship:
在MySQL中没有直接说明表关系的东西,外键约束是一个表现形式,它只是一种表之间的约束。是为了自己好理解,才把外键认为了是“表关系”。
在SQLAlchemy中,这个relationship默认代表的是一对多的关系,relationship是和外键一起使用的。可以通过参数设置去改变表关系,它默认是一对多的关系。而这个关系是SQLAlchemy里的,跟MySQL数据库没有关系。
(6).relationship参数分解
relationship('User', backref='details', uselist=False, cascade='all')
User:关联的Module
backref:在对应的Module中添加属性
uselist:上面的例子中表示“一对一”关系。如果是一对多关系,则不需要重新赋值。如果是一对一关系,则需要赋值为False
cascade:自动关系处理,就和MySQL中的 ON DELETE 类似
(7).cascade所有可选的值
all:所有操作都会自动处理到关联对象上
save-update:关联对象自动添加到会话
delete:关联对象自动从会话中删除
delete-orphan:属性中去掉关联对象,则会话中会自动删除关联对象
merge:session.merge()时会处理关联对象
refresh-expire:session.expire()时会处理关联对象
expunge:session.expunge()时会处理关联对象
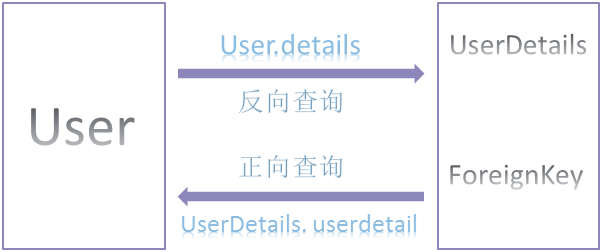
(8).正方向查询
分辨正向查询和反向查询,主要看ForeginKey在哪个Module中
(二).多对多表关系
(1).先创建一个新的Model
class Article(Base): __tablename__ = 'article' id = Column(Integer, primary_key=True, autoincrement=True) content = Column(String(500), nullable=True) create_time = Column(DateTime, default=datetime.now) article_user = relationship('User', backref='article', secondary=user_article) def __repr__(self): return 'Article(id=%s, content=%s, creat_time=%s)' % ( self.id, self.content, self.create_time )
(2).导入方法
from sqlalchemy import Table
(3).使用中间表来关联两张表之间的多对多关系
user_article = Table( 'user_article', Base.metadata, Column('user_id', Integer, ForeignKey('user.id'), primary_key=True), Column('article_id', Integer, ForeignKey('article.id'), primary_key=True) )