本文参考:
Python中文转拼音代码(支持全拼和首字母缩写)
中文中不可以有“()”
# -*- coding: utf-8 -*- __version__ = '0.9' __all__ = ["PinYin"] import os.path class PinYin(object): def __init__(self): self.word_dict = {} def load_word(self, dict_file): self.dict_file = dict_file if not os.path.exists(self.dict_file): raise IOError("NotFoundFile") with file(self.dict_file) as f_obj: for f_line in f_obj.readlines(): try: line = f_line.split(' ') self.word_dict[line[0]] = line[1] except: line = f_line.split(' ') self.word_dict[line[0]] = line[1] def hanzi2pinyin(self, string="", firstcode=False): result = [] if not isinstance(string, unicode): string = string.decode("utf-8") for char in string: key = '%X' % ord(char) value = self.word_dict.get(key, char) # print("===================")+value # print ("str(value).split()===") # for i in str(value).split(): # print i if value is not None and len(value)>0: s1=str(value).split() # print(type(s1)) # print(str(len(s1))) if s1 is not None and len(s1)>0: outpinyin = str(value).split()[0][:-1].lower() if not outpinyin: outpinyin = char if firstcode: result.append(outpinyin[0]) else: result.append(outpinyin) return result def hanzi2pinyin_split(self, string="", split="", firstcode=False): """提取中文的拼音 @param string:要提取的中文 @param split:分隔符 @param firstcode: 提取的是全拼还是首字母?如果为true表示提取首字母,默认为False提取全拼 """ result = self.hanzi2pinyin(string=string, firstcode=firstcode) return split.join(result) if __name__ == "__main__": test = PinYin() test.load_word('word.data') string = "Java程序性能优化-让你的Java程序更快更稳定" print "in: %s" % string print "out: %s" % str(test.hanzi2pinyin(string=string)) print "out: %s" % test.hanzi2pinyin_split(string=string, split="", firstcode=True) print "out: %s" % test.hanzi2pinyin_split(string=string, split="", firstcode=False)
使用:
import app.model.explore.util.pinyin as pinyin
pyCvtor = pinyin.PinYin()
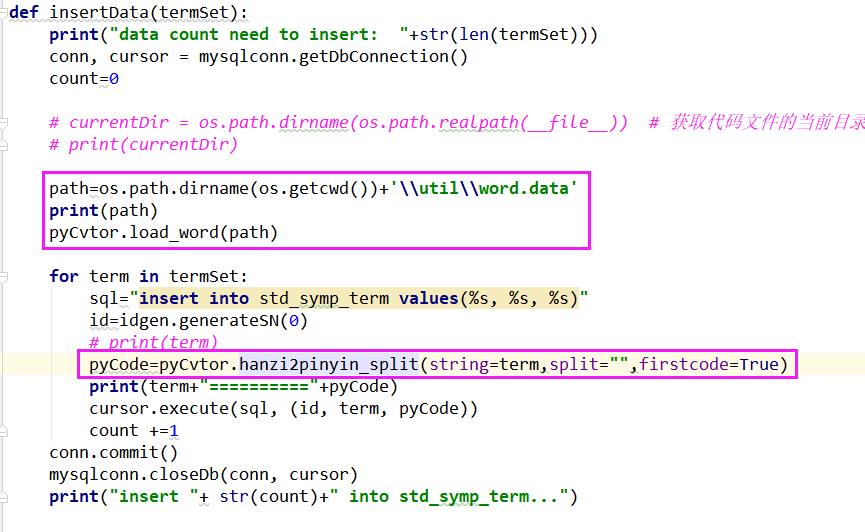
path=os.path.dirname(os.getcwd())+'\util\word.data' print(path) pyCvtor.load_word(path)
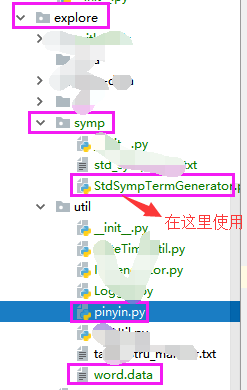
目录结构
具体使用:
转换效果:
肉眼及镜下血尿==========ryjjxxn 尿毒症 ==========ndz 智力发育迟缓==========zlfych 氮质血症 ==========dzxz 空腹血糖及糖耐量试验均正常==========kfxtjtnlsyjzc 血尿==========xn 大量蛋白尿==========dldbn 多尿==========dn 少尿==========sn 贫血氮质血症==========pxdzxz