背景
2015年,残差网络在ImageNet测试集上的错误率仅为 3.57%。
在ImageNet检测、ImageNet定位、COCO检测以及COCO分割上均获得了第一名的成绩。
结构
深度在神经网络中有及其重要的作用,但越深的网络越难训练。
随着深度的增加,从训练一开始,梯度消失或梯度爆炸就会阻止收敛,标准初始化和中间归一化能够一定程度解决这个问题,但依旧会出现退化问题——随着深度的增加,准确率会达到饱和,再持续增加深度则会导致准确率下降。
这个问题不是由于过拟合造成的,因为训练误差也会随着深度增加而增大。
深度残差网络则能解决这个问题。
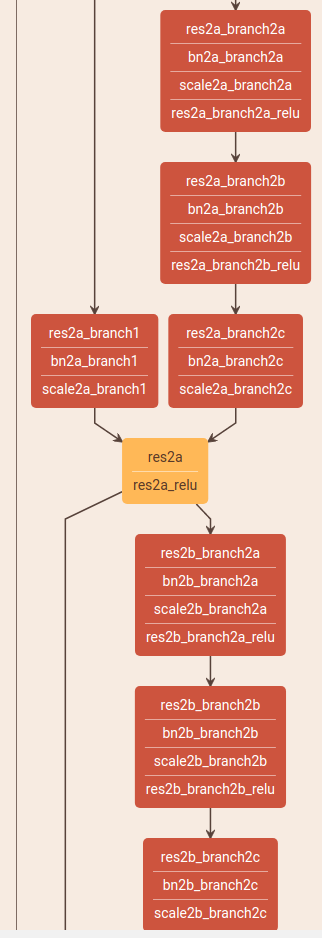
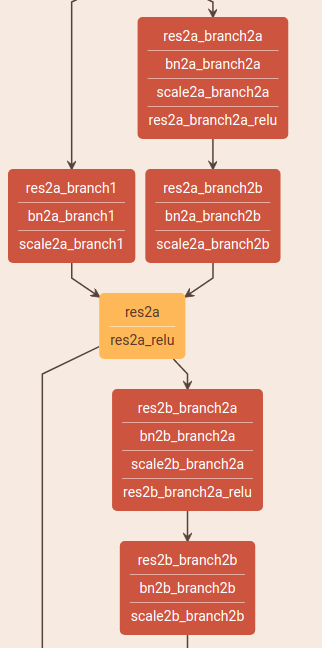
残差网络基本结构如下:

实现
以Imagenet为例,实现Resnet 34,简化部分mxnet源码。
units=[3, 4, 6, 3]和上面结构图的颜色块一致。[64, 64, 128, 256, 512]是每块的输出大小(dim=1)。
其中每次调用residual_unit,当bottle_neck = True (超过50层时),会创建4个卷积层,当 bottle_neck = False时,创建3个卷积层,对比如下。
详细网络可以使用ProtoFiles结合http://ethereon.github.io/netscope/#/editor理解。
def residual_unit(data, num_filter, stride, dim_match, name, bottle_neck=True, bn_mom=0.9, workspace=256, memonger=False): """Return ResNet Unit symbol for building ResNet Parameters ---------- data : str Input data num_filter : int Number of output channels bnf : int Bottle neck channels factor with regard to num_filter stride : tupe Stride used in convolution dim_match : Boolen True means channel number between input and output is the same, otherwise means differ name : str Base name of the operators workspace : int Workspace used in convolution operator """ if bottle_neck: # the same as https://github.com/facebook/fb.resnet.torch#notes, a bit difference with origin paper bn1 = mx.sym.BatchNorm(data=data, fix_gamma=False, eps=2e-5, momentum=bn_mom, name=name + '_bn1') act1 = mx.sym.Activation(data=bn1, act_type='relu', name=name + '_relu1') conv1 = mx.sym.Convolution(data=act1, num_filter=int(num_filter*0.25), kernel=(1,1), stride=(1,1), pad=(0,0), no_bias=True, workspace=workspace, name=name + '_conv1') bn2 = mx.sym.BatchNorm(data=conv1, fix_gamma=False, eps=2e-5, momentum=bn_mom, name=name + '_bn2') act2 = mx.sym.Activation(data=bn2, act_type='relu', name=name + '_relu2') conv2 = mx.sym.Convolution(data=act2, num_filter=int(num_filter*0.25), kernel=(3,3), stride=stride, pad=(1,1), no_bias=True, workspace=workspace, name=name + '_conv2') bn3 = mx.sym.BatchNorm(data=conv2, fix_gamma=False, eps=2e-5, momentum=bn_mom, name=name + '_bn3') act3 = mx.sym.Activation(data=bn3, act_type='relu', name=name + '_relu3') conv3 = mx.sym.Convolution(data=act3, num_filter=num_filter, kernel=(1,1), stride=(1,1), pad=(0,0), no_bias=True, workspace=workspace, name=name + '_conv3') if dim_match: shortcut = data else: shortcut = mx.sym.Convolution(data=act1, num_filter=num_filter, kernel=(1,1), stride=stride, no_bias=True, workspace=workspace, name=name+'_sc') if memonger: shortcut._set_attr(mirror_stage='True') return conv3 + shortcut else: bn1 = mx.sym.BatchNorm(data=data, fix_gamma=False, momentum=bn_mom, eps=2e-5, name=name + '_bn1') act1 = mx.sym.Activation(data=bn1, act_type='relu', name=name + '_relu1') conv1 = mx.sym.Convolution(data=act1, num_filter=num_filter, kernel=(3,3), stride=stride, pad=(1,1), no_bias=True, workspace=workspace, name=name + '_conv1') bn2 = mx.sym.BatchNorm(data=conv1, fix_gamma=False, momentum=bn_mom, eps=2e-5, name=name + '_bn2') act2 = mx.sym.Activation(data=bn2, act_type='relu', name=name + '_relu2') conv2 = mx.sym.Convolution(data=act2, num_filter=num_filter, kernel=(3,3), stride=(1,1), pad=(1,1), no_bias=True, workspace=workspace, name=name + '_conv2') if dim_match: shortcut = data else: shortcut = mx.sym.Convolution(data=act1, num_filter=num_filter, kernel=(1,1), stride=stride, no_bias=True, workspace=workspace, name=name+'_sc') if memonger: shortcut._set_attr(mirror_stage='True') return conv2 + shortcut def resnet(units=[3, 4, 6, 3], num_stages=4, filter_list=[64, 64, 128, 256, 512], num_classes=1000, bottle_neck=False, bn_mom=0.9, workspace=256, memonger=False): """Return ResNet symbol of Parameters ---------- units : list Number of units in each stage num_stages : int Number of stage filter_list : list Channel size of each stage num_classes : int Ouput size of symbol dataset : str Dataset type, only cifar10 and imagenet supports workspace : int Workspace used in convolution operator """ num_unit = len(units) assert(num_unit == num_stages) data = mx.sym.Variable(name='data') data = mx.sym.identity(data=data, name='id') data = mx.sym.BatchNorm(data=data, fix_gamma=True, eps=2e-5, momentum=bn_mom, name='bn_data') body = mx.sym.Convolution(data=data, num_filter=filter_list[0], kernel=(7, 7), stride=(2,2), pad=(3, 3), no_bias=True, name="conv0", workspace=workspace) body = mx.sym.BatchNorm(data=body, fix_gamma=False, eps=2e-5, momentum=bn_mom, name='bn0') body = mx.sym.Activation(data=body, act_type='relu', name='relu0') body = mx.symbol.Pooling(data=body, kernel=(3, 3), stride=(2,2), pad=(1,1), pool_type='max') for i in range(num_stages): body = residual_unit(body, filter_list[i+1], (1 if i==0 else 2, 1 if i==0 else 2), False, name='stage%d_unit%d' % (i + 1, 1),
, workspace=workspace, memonger=memonger) for j in range(units[i]-1): body = residual_unit(body, filter_list[i+1], (1,1), True, name='stage%d_unit%d' % (i + 1, j + 2), bottle_neck=bottle_neck, workspace=workspace, memonger=memonger) bn1 = mx.sym.BatchNorm(data=body, fix_gamma=False, eps=2e-5, momentum=bn_mom, name='bn1') relu1 = mx.sym.Activation(data=bn1, act_type='relu', name='relu1') # Although kernel is not used here when global_pool=True, we should put one pool1 = mx.symbol.Pooling(data=relu1, global_pool=True, kernel=(7, 7), pool_type='avg', name='pool1') flat = mx.symbol.Flatten(data=pool1) fc1 = mx.symbol.FullyConnected(data=flat, num_hidden=num_classes, name='fc1') return mx.symbol.SoftmaxOutput(data=fc1, name='softmax')