CNN网络结构-ResNext
背景
2016年,KaiMing将AlexNet中的group convolution引进了ResNet中,以获得更少的参数,在ImageNet上刷出了排名第二的好成绩。
101-layer的ResNeXt可以达到ResNet的精确度,在complexity却只有后者的一半。
结构
ResNext的group convolution结构如下:
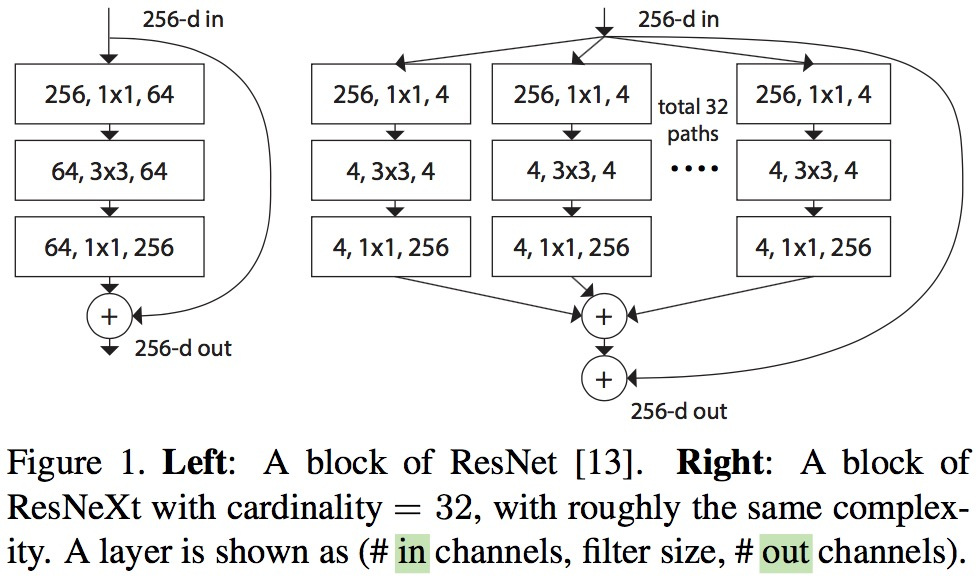
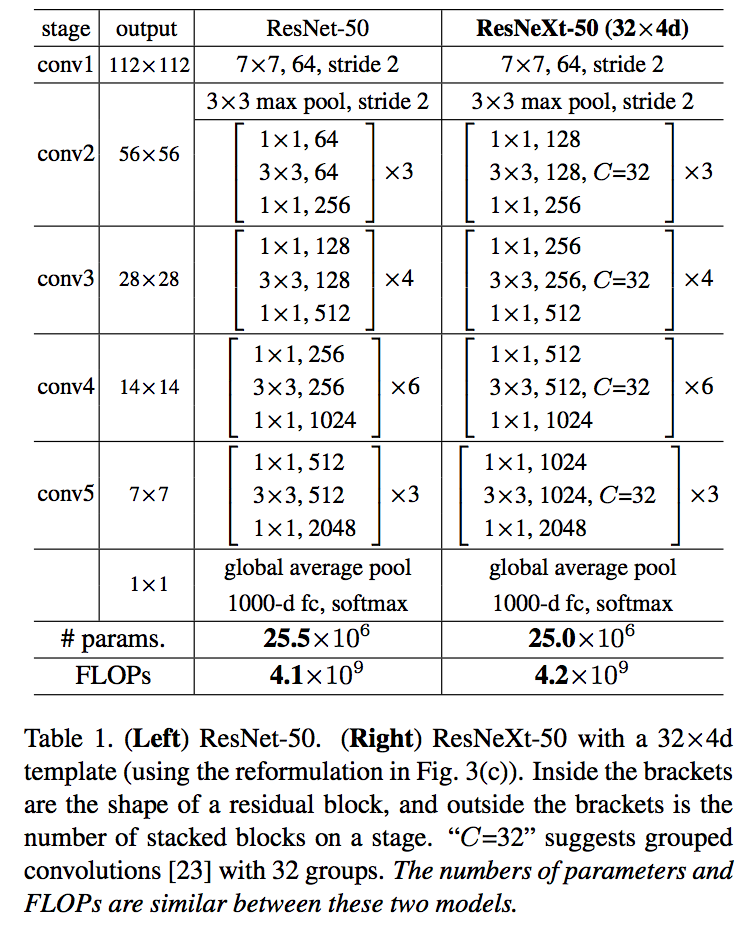
网络参数:
- ResNeXt 与 ResNet 在相同参数个数情况下,训练时前者错误率更低,但下降速度差不多
- 相同参数情况下,增加 cardinality 比增加卷几个数更加有效
- 101 层的 ResNeXt 比 200 层的 ResNet 更好
- 几种 sota 的模型,ResNeXt 准确率最高
实现
以下是Resnext 34的mxnet实现,略修改简化。
相比Resnet最大的改动就是residual_unit中的conv2加上了num_group=32的参数,作用是将输入数据切割成num_group个partitions,然后在每个partition上使用卷积操作,再将卷积的结果连接起来。
''' Adapted from https://github.com/tornadomeet/ResNet/blob/master/symbol_resnet.py Original author Wei Wu Implemented the following paper: Saining Xie, Ross Girshick, Piotr Dollar, Zhuowen Tu, Kaiming He. "Aggregated Residual Transformations for Deep Neural Network" ''' import mxnet as mx def residual_unit(data, num_filter, stride, dim_match, name, bottle_neck=True, num_group=32, bn_mom=0.9, workspace=256, memonger=False): """Return ResNet Unit symbol for building ResNet Parameters ---------- data : str Input data num_filter : int Number of output channels bnf : int Bottle neck channels factor with regard to num_filter stride : tupe Stride used in convolution dim_match : Boolen True means channel number between input and output is the same, otherwise means differ name : str Base name of the operators workspace : int Workspace used in convolution operator """ if bottle_neck: # the same as https://github.com/facebook/fb.resnet.torch#notes, a bit difference with origin paper conv1 = mx.sym.Convolution(data=data, num_filter=int(num_filter*0.5), kernel=(1,1), stride=(1,1), pad=(0,0), no_bias=True, workspace=workspace, name=name + '_conv1') bn1 = mx.sym.BatchNorm(data=conv1, fix_gamma=False, eps=2e-5, momentum=bn_mom, name=name + '_bn1') act1 = mx.sym.Activation(data=bn1, act_type='relu', name=name + '_relu1') conv2 = mx.sym.Convolution(data=act1, num_filter=int(num_filter*0.5), num_group=num_group, kernel=(3,3), stride=stride, pad=(1,1), no_bias=True, workspace=workspace, name=name + '_conv2') bn2 = mx.sym.BatchNorm(data=conv2, fix_gamma=False, eps=2e-5, momentum=bn_mom, name=name + '_bn2') act2 = mx.sym.Activation(data=bn2, act_type='relu', name=name + '_relu2') conv3 = mx.sym.Convolution(data=act2, num_filter=num_filter, kernel=(1,1), stride=(1,1), pad=(0,0), no_bias=True, workspace=workspace, name=name + '_conv3') bn3 = mx.sym.BatchNorm(data=conv3, fix_gamma=False, eps=2e-5, momentum=bn_mom, name=name + '_bn3') if dim_match: shortcut = data else: shortcut_conv = mx.sym.Convolution(data=data, num_filter=num_filter, kernel=(1,1), stride=stride, no_bias=True, workspace=workspace, name=name+'_sc') shortcut = mx.sym.BatchNorm(data=shortcut_conv, fix_gamma=False, eps=2e-5, momentum=bn_mom, name=name + '_sc_bn') if memonger: shortcut._set_attr(mirror_stage='True') eltwise = bn3 + shortcut return mx.sym.Activation(data=eltwise, act_type='relu', name=name + '_relu') else: conv1 = mx.sym.Convolution(data=data, num_filter=num_filter, kernel=(3,3), stride=stride, pad=(1,1), no_bias=True, workspace=workspace, name=name + '_conv1') bn1 = mx.sym.BatchNorm(data=conv1, fix_gamma=False, momentum=bn_mom, eps=2e-5, name=name + '_bn1') act1 = mx.sym.Activation(data=bn1, act_type='relu', name=name + '_relu1') conv2 = mx.sym.Convolution(data=act1, num_filter=num_filter, kernel=(3,3), stride=(1,1), pad=(1,1), no_bias=True, workspace=workspace, name=name + '_conv2') bn2 = mx.sym.BatchNorm(data=conv2, fix_gamma=False, momentum=bn_mom, eps=2e-5, name=name + '_bn2') if dim_match: shortcut = data else: shortcut_conv = mx.sym.Convolution(data=data, num_filter=num_filter, kernel=(1,1), stride=stride, no_bias=True, workspace=workspace, name=name+'_sc') shortcut = mx.sym.BatchNorm(data=shortcut_conv, fix_gamma=False, eps=2e-5, momentum=bn_mom, name=name + '_sc_bn') if memonger: shortcut._set_attr(mirror_stage='True') eltwise = bn2 + shortcut return mx.sym.Activation(data=eltwise, act_type='relu', name=name + '_relu') def resnext(units=[3, 4, 6, 3], num_stages=4, filter_list=[64, 64, 128, 256, 512], num_classes=1000, num_group=32, bottle_neck=False, bn_mom=0.9, workspace=256, memonger=False): """Return ResNeXt symbol of Parameters ---------- units : list Number of units in each stage num_stages : int Number of stage filter_list : list Channel size of each stage num_classes : int Ouput size of symbol num_groupes: int Number of conv groups dataset : str Dataset type, only cifar10 and imagenet supports workspace : int Workspace used in convolution operator """ num_unit = len(units) assert(num_unit == num_stages) data = mx.sym.Variable(name='data') data = mx.sym.BatchNorm(data=data, fix_gamma=True, eps=2e-5, momentum=bn_mom, name='bn_data') body = mx.sym.Convolution(data=data, num_filter=filter_list[0], kernel=(7, 7), stride=(2,2), pad=(3, 3), no_bias=True, name="conv0", workspace=workspace) body = mx.sym.BatchNorm(data=body, fix_gamma=False, eps=2e-5, momentum=bn_mom, name='bn0') body = mx.sym.Activation(data=body, act_type='relu', name='relu0') body = mx.symbol.Pooling(data=body, kernel=(3, 3), stride=(2,2), pad=(1,1), pool_type='max') for i in range(num_stages): body = residual_unit(body, filter_list[i+1], (1 if i==0 else 2, 1 if i==0 else 2), False, name='stage%d_unit%d' % (i + 1, 1), bottle_neck=bottle_neck, num_group=num_group, bn_mom=bn_mom, workspace=workspace, memonger=memonger) for j in range(units[i]-1): body = residual_unit(body, filter_list[i+1], (1,1), True, name='stage%d_unit%d' % (i + 1, j + 2), bottle_neck=bottle_neck, num_group=num_group, bn_mom=bn_mom, workspace=workspace, memonger=memonger) pool1 = mx.symbol.Pooling(data=body, global_pool=True, kernel=(7, 7), pool_type='avg', name='pool1') flat = mx.symbol.Flatten(data=pool1) fc1 = mx.symbol.FullyConnected(data=flat, num_hidden=num_classes, name='fc1') return mx.symbol.SoftmaxOutput(data=fc1, name='softmax')