YOLOv3网络是一种单阶段的目标检测方法,目标检测方法旨在给定的图片中找出目标物体的坐标位置和所属类别。我们在这里来梳理一下训练的大致流程谨供参考,我参考的算法实现为:https://github.com/eriklindernoren/PyTorch-YOLOv3
1.特征提取
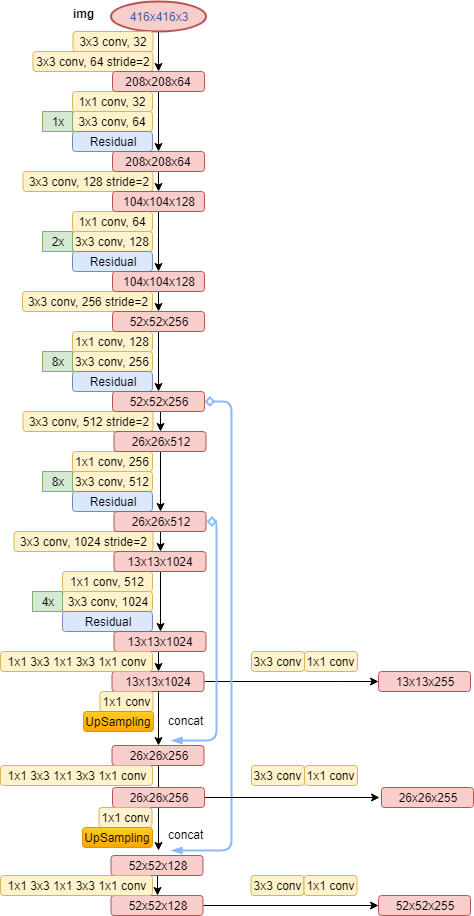
YOLOv3的输入一般是 416x416x3的原始图片矩阵、n个坐标标签和n个分类标签,其中n代表每幅图中目标物体的个数。在经过特征提取网络后,会得到三种不同尺寸的特征图:13x13x255、26x26x255、52x52x255,具体网络结构如下图所示(其中Residual代表残差连接):
2.YOLO层
YOLO层负责对得到的特征图进行预测或训练处理,训练时分别计算坐标损失和分类损失,以网络得到的尺寸为255x13x13的特征图为例:
1.首先将特征图reshape和交换维度为 3x13x13x85,85项的前4列分别为center-x、center-y、w、h的shift预测,第5列为置信度confidence的预测,后面为80个类别的预测
2.对center-x、center-y、confidence、80个类别预测作sigmoid激活操作
3.假设其有n个真实标签框gt_bbox,只根据宽高计算gt_bbox与3种anchor之间可能的最大IOU值得到(3,n)的IOU表,根据最大IOU值为每个gt_bbox选择一个anchor,则此anchor下gt_bbox的坐标处为一个正样本,其余的设为负样本。
4.将IOU>阈值的预测点取消设为负样本
5.通过计算得到正样本标签
6.根据样本的预测值和标签值计算坐标损失、置信度损失和分类损失,其中坐标损失和分类损失只用正样本的计算