上一篇讲了ArrayList,它有一个"孪生兄弟"--LinkedList,这两个集合类总是经常会被拿来比较,今天就分析一下LinkedList,然后总结一下这俩集合类的不同
首先看看其成员变量
transient int size = 0;//所含元素数量 transient Node<E> first;//链表的首项 transient Node<E> last;//链表的尾项
ArrayList是基于数组的,而LinkedList是用链表来实现的,链表不需要考虑容量问题,所以LinkedList的没有容量相关的成员变量,链表图例:

LinkedList中的节点是以Node类的实例存在的:
private static class Node<E> { E item;//具体保存的元素 Node<E> next;//下一个节点 Node<E> prev;//上一个节点 Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
构造函数,很简单
/** * 空集合 */ public LinkedList() { } /** * 传入一个集合对象 */ public LinkedList(Collection<? extends E> c) { this(); addAll(c); }
接下来看看具体对集合的操作方法,先看看add(E e)
public boolean add(E e) { linkLast(e); return true; } /** * 新添加的元素直接链接到链表中的最后一个 */ void linkLast(E e) { final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);//创建一个新节点,下一个节点指向旧的链表尾节点 last = newNode;//新节点作为链表的尾节点 if (l == null)//如果旧链表尾项为空即这是第一个添加的节点 first = newNode;//新节点也作为首节点 else l.next = newNode;//新节点作为旧链表尾节点的下一个节点 size++; modCount++; }
非常简单,没有什么复杂的操作,就是涉及到几个引用的重新指向而已,常数时间复杂度(与具体的集合规模大小无关);这里想想上一篇写的ArrayList的add方法,需要考虑扩容问题,各种判断,然后在需要扩容的情况下,进行数组拷贝,线性时间复杂度(与集合所含元素成线性关系)。
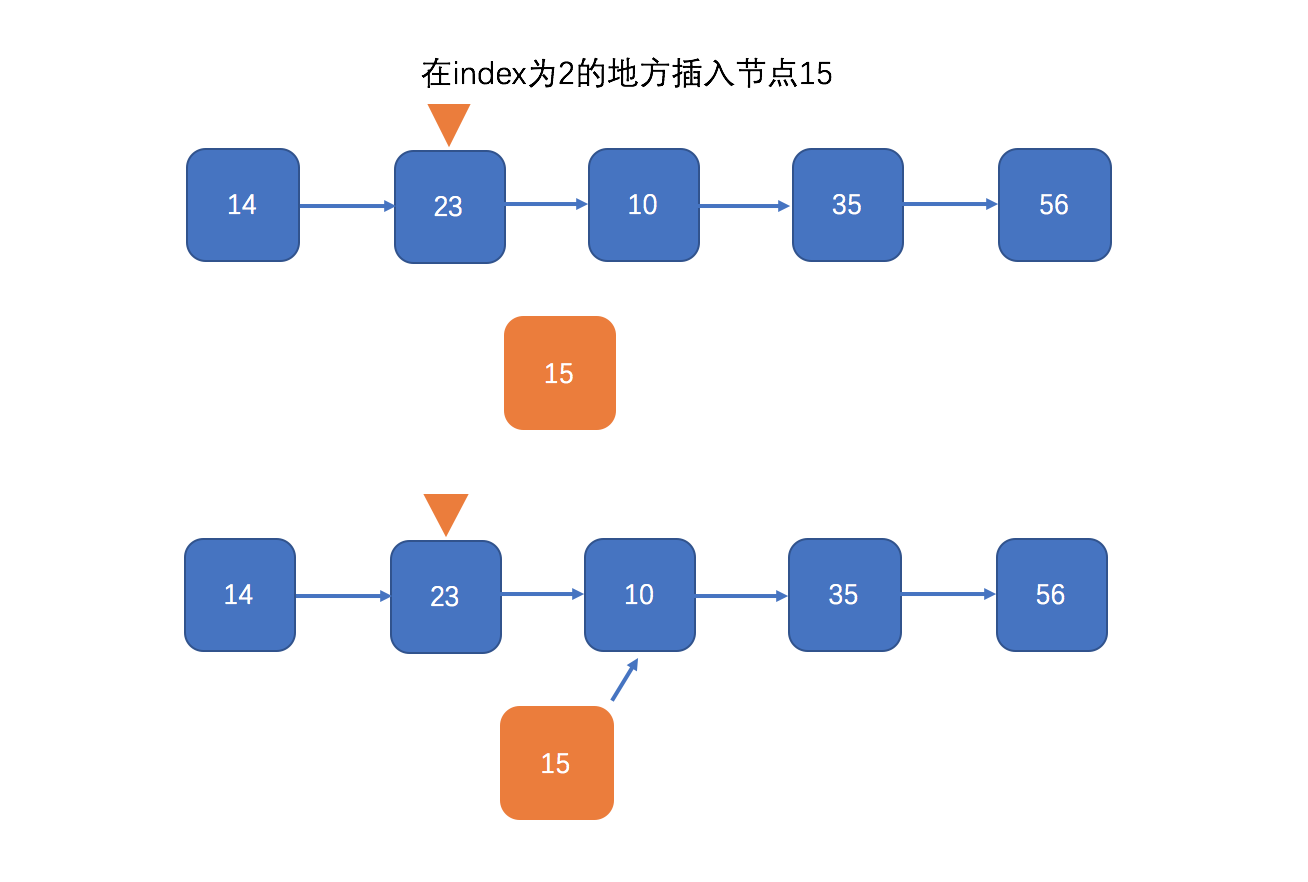
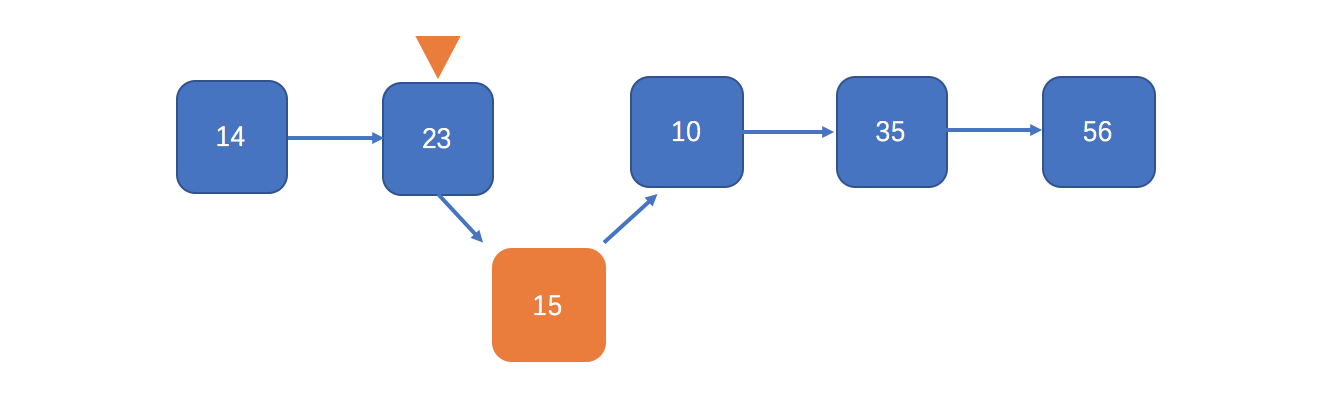
再看看add(int index, E element)指定一个位置插入元素:
public void add(int index, E element) { checkPositionIndex(index);//index是否在合理范围内 if (index == size)//如果插入位置刚好在链表的尾部 linkLast(element);//直接链接到尾节点 else linkBefore(element, node(index));//插入到指定位置上 } //获取到指定位置的节点对象 Node<E> node(int index) { //这里有个小技巧,如果位置在前半段,那就从首节点开始遍历,否则从尾节点开始倒叙遍历 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } } //插入到某个节点之前,主要还是引用的重新指向操作 void linkBefore(E e, Node<E> succ) { final Node<E> pred = succ.prev; final Node<E> newNode = new Node<>(pred, e, succ);//该位置旧节点的前驱作为新节点的前驱,旧节点本身作为新节点的后继 succ.prev = newNode;//新节点作为旧节点的前驱 if (pred == null) first = newNode; else pred.next = newNode;//新节点作为旧节点的后继的前驱 size++; modCount++; }
用图来表示这个具体的插入过程:
这时候想想ArraryList和LinkedList的插入方法,到底谁高呢?我们之前都知道LinkedList的动态操作效率应该是比ArraryList的要高的,这里我写了个测试方法:
List<String> arrayList = new ArrayList<>(); List<String> linkedList = new LinkedList<>(); for (int i = 0; i < 50000; i++) { arrayList.add(i+""); linkedList.add(i+""); } long millis01 = System.currentTimeMillis(); for (int i = 0; i < 50000; i++) { arrayList.add(i,"test"); } long millis02 = System.currentTimeMillis(); System.out.println("ArrayList用时:"+(millis02-millis01)+"ms"); for (int i = 0; i < 50000; i++) { linkedList.add(i,"test"); } long millis03 = System.currentTimeMillis(); System.out.println("linkedList用时:"+(millis03-millis02)+"ms");
结果
ArrayList用时:540ms
linkedList用时:2161ms
结论:ArrayList效率高很多,主要是因为linkedList的add(int index, E element)在执行插入操作之前需要遍历查找对应位置的节点,当然具体的插入操作是基本不影响效率的。
linkedList的移除操作的主要核心方法E unlink(Node<E> x):
E unlink(Node<E> x) { final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) { first = next; } else { prev.next = next;//后继作为前驱的后继 x.prev = null;//设为null,等待gc } if (next == null) { last = prev; } else { next.prev = prev;//前驱作为后继的前驱 x.next = null;//设为null 等待gc } x.item = null;//设为null,等待gc size--; modCount++; return element; }
还是那句话,链表的具体动态操作只是涉及到常数操作的引用重新指向,但是如果在具体动态操作之前有需要进行遍历查找的话,就很影响效率了。
接下来看看linkedList的查找操作:
public E get(int index) { checkElementIndex(index); return node(index).item; }
就是调用node(index),我们上面分析过,就是遍历,效率自然是比较低的,没什么好说的。
最后对比一下LinkedList和ArrayList遍历的效率:
List<String> linkedList = new LinkedList<>(); List<String> arrayList= new ArrayList<>(1000000); for (int i = 0; i < 1000000; i++) { linkedList.add(i+""); arrayList.add(i+""); } long millis1 = System.currentTimeMillis(); for (String s : linkedList) { System.out.print(s); } System.out.println(); long millis2 = System.currentTimeMillis(); System.out.println("linkedList耗时-----"+(millis1-millis2)); for (String s : arrayList) { System.out.print(s); } System.out.println(); long millis3 = System.currentTimeMillis(); System.out.println("arrayList耗时-----"+(millis3-millis2));
结果:linkedList耗时------1702
arrayList耗时-----1664
根据多次运行结果上来说,两者的效率相当,没有明显的差别,首先我们知道增强的for循环是java中的语法糖,本质上是使用的是迭代器遍历,首先可以知道ArrayList使用迭代器和对数组时候用普遍的for本质上是没有差别,都是通过索引值递增实现;我们主要看一下LinkedList中迭代器的实现:
private class ListItr implements ListIterator<E> { private Node<E> lastReturned;//最后一次读取的节点 private Node<E> next;//下一个读取的节点 private int nextIndex;//序号,记录读到哪个位置 private int expectedModCount = modCount; ListItr(int index) { next = (index == size) ? null : node(index); nextIndex = index; } //是否还有下一个元素 public boolean hasNext() { return nextIndex < size; } //获取下一个元素 public E next() { checkForComodification(); if (!hasNext()) throw new NoSuchElementException(); lastReturned = next;//记录本次使用的节点 next = next.next;//记录下次遍历的节点 nextIndex++; return lastReturned.item; } }
可以看到,链表的遍历主要是通过前一个元素保存的下一个对象的引用来实现的,时间复杂度都线性的,所以在使用迭代器遍历上,LinkedList和ArrayList没有明显的差别;
这里提一下ListIterator和Iterator,ListIterator是List类型的集合特有的,因为List是有序的,我们可以通过索引指定迭代器遍历集合的区间,所以可以实现ListIterator接口。
总结:1.对于随机(根据索引)访问,ArrayList绝对地优于LinkedList,因为LinkedList要进行遍历查找
2.对于新增和删除操作,LinkedList不一定会效率比ArrayList高,因为在根据索引值进行新增和删除的方法中,需要首先通过索引值进行查找然后在进行具体的动态操作,LinkedList的效率实际上也是不如ArrayList的,这一点网上很多说法都不是很准确