一 介绍
本系列文章主要介绍机器学习中集成学习的相关理论及代表算法,文章主要包括以下几个方面:
1. 集成学习的相关介绍
2. boosting相关算法原理
3. bagging相关算法原理
以下内容主要是对第一部分的集成学习的相关介绍展开描述。
俗话说“三个臭皮匠,赛过诸葛亮”,集成学习运用的正是这种思想。并且近几年来集成学习在很多任务上都取得较高的准确率,更是在各种比赛中被广泛应用,成为了机器学习算法中的佼佼者。要介绍集成学习,首先我们要了解一下弱学习器和强学习器。
弱学习器:一个概念如果存在一个多项式的学习算法能够学习它,并且学习的正确率仅比随机猜测略好(高于50%),那么,这个概念是弱可学习的。
强学习器:一个概念如果存在一个多项式的学习算法能够学习它,并且正确率很高,那么,这个概念是强可学习的。
集成学习可以看成一种优化手段或者是策略,它可以通过结合几个弱学习器,而达到强学习器才能达到的效果。如图1所示:
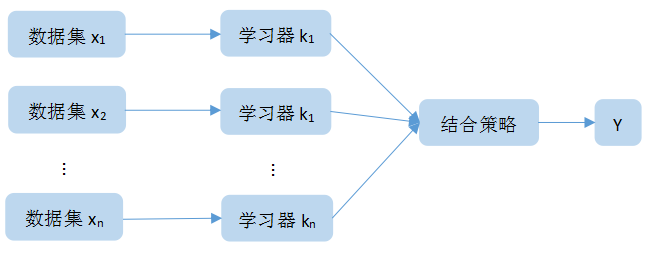
图1:集成学习大致流程
其中,x1,x2...xn表示训练模型所使用的数据集,k1,k2...kn表示所选用的弱学习器,之后通过一定的结合的结合策略对模型训练的结果进行决策,最后得到最终的预测结果。
这里我们要做的主要工作就是根据选择的集成学习类型选择合适的个体学习器和结合方式。
二 集成学习类别
集成学习的类别主要有三种,分别是boosting,bagging,stacking。下面会依次介绍这三种类别。
1.boosting
该方法是一种串行集成方法,每一次迭代时训练集的选择与前面各轮的学习结果有关,而且每次是通过更新各个样本权重的方式来改变数据分布。
boosting每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化.而权值是根据上一轮的分类结果进行调整。在训练过程中,会根据错误率不断调整样例的权值,错误率越大则权重越大,错误则权重越小。最终组合弱分类器通过加法模型将弱分类器进行线性组合,给弱分类器分布不同的权值,错误率较小的分类器给予即增大错误率小的分类器的权值,同时减小错误率较大的分类器的权值。
boosting的算法原理如图2所示:

图2:boosting算法原理图
boosting算法的具体步骤如下:
(1)、首先初始化数据集所有点的权重分布
(2)、根据权重分布,训练第一个弱学习器
(3)、计算弱学习器在训练数据集上的分类误差率
(4)、更新数据集的权重分布,分类误差率大的样本,会增大权重,分类误差率小的样本,会相应的减少权重
(5)、循环,直到最后一个分类器训练完成,最后通过结合策略对弱学习器进行结合
特别指出:分类器之间应该具有差异性、个体分类器的精度必须大于0.5
构建具有差异性的分类器可以从以下几个方面考虑:
(1) 通过处理数据集生成差异性分类器。主要是boosting和bagging对数据集的取样操作。
(2) 通过处理数据集特征生成差异分类器。对训练数据集采用不同的特征进行训练。
(3) 通过对分类器的处理构建差异分类器。通过改变算法的参数或者采用不同的分类器来进行构建。
boosting框架的代表算法:AdaBoost , GBDT , XGBoost等
2. bagging
该方法采用并行学习的方法,可同时训练多个弱学习器,最终通过结合策略进行弱学习器的结合,得出最后结果。
bagging采用的是有放回随机抽样。从原始样本集中抽取训练集,假设原始样本集有n个样本,每轮从原始样本集中抽取m个训练样本,这里n>m,共抽取k轮,则得到k个训练集。因为采用的是有放回抽样,所以存在有些样本可能被抽取到多次,而有些样本从未被抽取到的情况。这里假设抽取到的k个训练集之间是相互独立的。因为采用的是均匀取样,所以每个样本的权重都是相同的。k个训练集采用k个弱学习器得到k个不同的结果。
bagging的算法原理如图3所示:
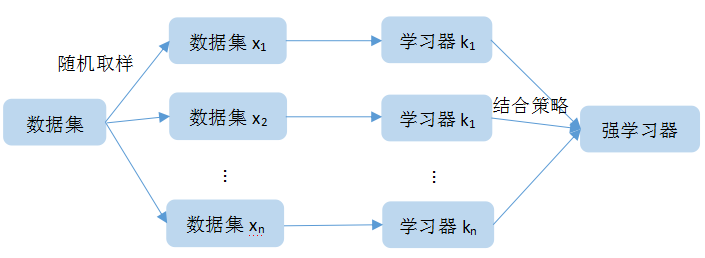
图3:bagging算法原理图
bagging的具体步骤如下:
(1)、通过有放回随机抽样获取k个训练集
(2)、每个训练集对应一个弱学习器进行训练
(3)、最终通过结合策略对多个弱学习器结果进行结合
特别指出:分类器之间应该具有差异性、个体分类器的精度必须大于0.5
bagging框架的代表算法:随机森林等
3. stacking
stacking是一种集成学习的算法,同时它也是一种重要的结合策略。这里把它第一次训练的模型叫做初级学习器,第二次训练的模型叫做次级学习器。stacking是把训练得到的初级学习器作为次级学习器的输入,进一步训练学习,得到最后的预测结果。就是在训练中,要注意为了防止过拟合,不能直接使用初级学习器的训练集产生次级学习器的训练集,而要使用交叉验证法,对初始的训练集进行划分,训练集用来训练初级学习器,验证集用来产生次级训练集。
stacking的算法原理如图4所示:
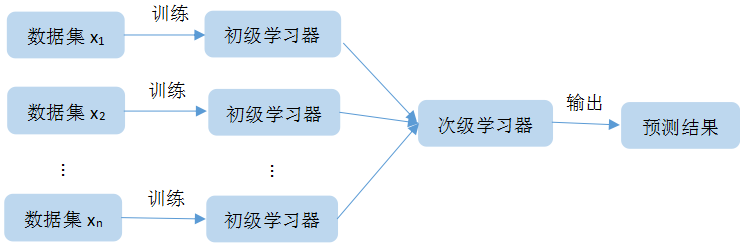
图4:stacking原理图
4.结合策略
结合策略是集成学习中的重要部分之一,通常结合策略分为对回归预测问题的结合策略和对分类预测问题的结合策略。
其中回归预测问题的结合策略主要采用平均法
4.1 平均法
平均法有算术平均法、加权平均法
算术平均法:即是对学习器的结果直接相加取平均。
加权平均法:每个学习器都有一个权重,对权重和结果的积进行求和。最大的值对应的类别为最终类别(学习器各权重之和为1)
4.2 投票法
投票法主要有相对多数投票法、绝对多数投票法和加权投票法
相对多数投票法:少数服从多数原则,如果不止一个最大值,则随机选取一个作为最终结果。
绝对多数投票法:找出的最大票数必须超过总票数 的的一半,结果才能成立。
加权投票法:每个弱学习器的分类票数乘以权重,最终将各个类别票数加权求和,最大的值对应的类别为最终类别。