三次作业,三次成长
第一次作业——幂函数求导总结
作业思路和心得
第一次作业的要求只有x的指数这样的幂函数加减组成表达式,对表达式进行求导,而且没有格式错误的检查,所以难度感觉还不是很高。不过由于我寒假的preview作业还有两个task没有做完,所以我感觉自己对语法和字符串处理等方面还不是很熟练。因此,虽然看起来第一次作业难度不高,但是我仍然十分认真地对待它,把它当作巩固自己基础的一次机会(之后的作业就没机会巩固基础了
进入正题,第一次作业由于只有一种幂函数,所以我的思路也比较简单:直接用TreeMap存储x的系数和指数,其中以指数作为Key以便于合并同类项。求导规则也很简单,只需将TreeMap里的每个元素取出来系数乘以指数输出为系数,指数-1作为新指数就完成了求导过程。
第一次作业让我调试了很久的地方是用正则表达式读入输入并进行分割,由于我对正则表达式掌握不熟练,期间查阅了众多资料和助教发的教程,最终在不断的摸索和尝试下,我写出了那个分割输入的正则表达式,写出正则后,后面的处理就显得简单很多了。第一次作业让我对正则的了解更深入一步。
程序结构分析
-
UML分析
第一次作业由于对面向对象思想理解不够,同时作业结构较简单,所以我在第一次作业只有一个Main类,有131行,类图也只有一个类,就不上图了。(以后要是再这么写就要次次重构了呢! -
复杂度分析
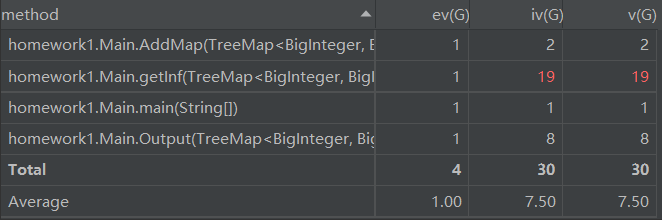
从分析表中可以看出,我的第一次作业中的getInf方法的设计复杂度和圈复杂度都较高,回归代码本人确实发现这个方法中if-else的结构嵌套较多且逻辑较复杂,同时由于它是第一次作业提取因子的主要方法,所以其被其他方法调用的次数也较多,导致其和其他方法的耦合度也较高,设计复杂度过高,导致其扩展性和复用性较差。
hack与被hack
第一次作业给了我惨痛的教训。我在强测中只得了18分,为什么呢?原因就在于我在优化过程中对正数的输出我误以为只会在开头,于是把+省略了(大概脑子一抽,捂脸.jpg),导致了我在强测中大量的输出格式错误,也就导致了我没有机会进入互测,第一次作业中也就没有得到什么hack别人的经验。
第二次作业——幂函数加三角函数求导
作业思路和心得
第二次作业除了幂函数还外加了三角函数,不过好在三角函数内部只能是x,这样所有输入的形式也最终可以化为三种:x^a,sin(x)^b,cos(x)^c。那么这样的话,我依旧可以沿用第一次作业的总体思路,即用TreeMap进行输入因子的存储,只不过这次的Key要新建一个类来存储三个因子各自的指数,求导方法的话也只需分成六类即可(三种因子随意组合——6种)。这次唯一与上一次不同的是多了WF判断。那我的思路是,既然错误那么多,找也找不全,不如构造正确的表达式的正则表达式,输入的能匹配,那就OK,匹配不上那就肯定是WF。这种思路避免了WF的漏判。
但由于这次输入复杂了一些,同时还要构造正确的正则表达式来判断格式,让我在第一次作业中学习到的正则表达式知识又捉襟见肘了。于是我在第二次作业期间,又花了一部分时间去学习更高级的正则表达式用法,最终第二次作业也是用正则表达式的形式来读取输入,判断格式,效果还不错。做完第二次作业,我感觉自己对正则表达式又有了更深一层的理解。第一次作业结束感觉自己正则表达式掌握的不错了,第二次作业结束让我感觉自己对正则表达式还有很多需要学习的地方,因为越是深入越是发现正则表达式的高级用法还有很多我所不知道的。我要在今后的学习中进一步深入了解正则表达式的用法和原理。
程序结构分析
-
UML分析
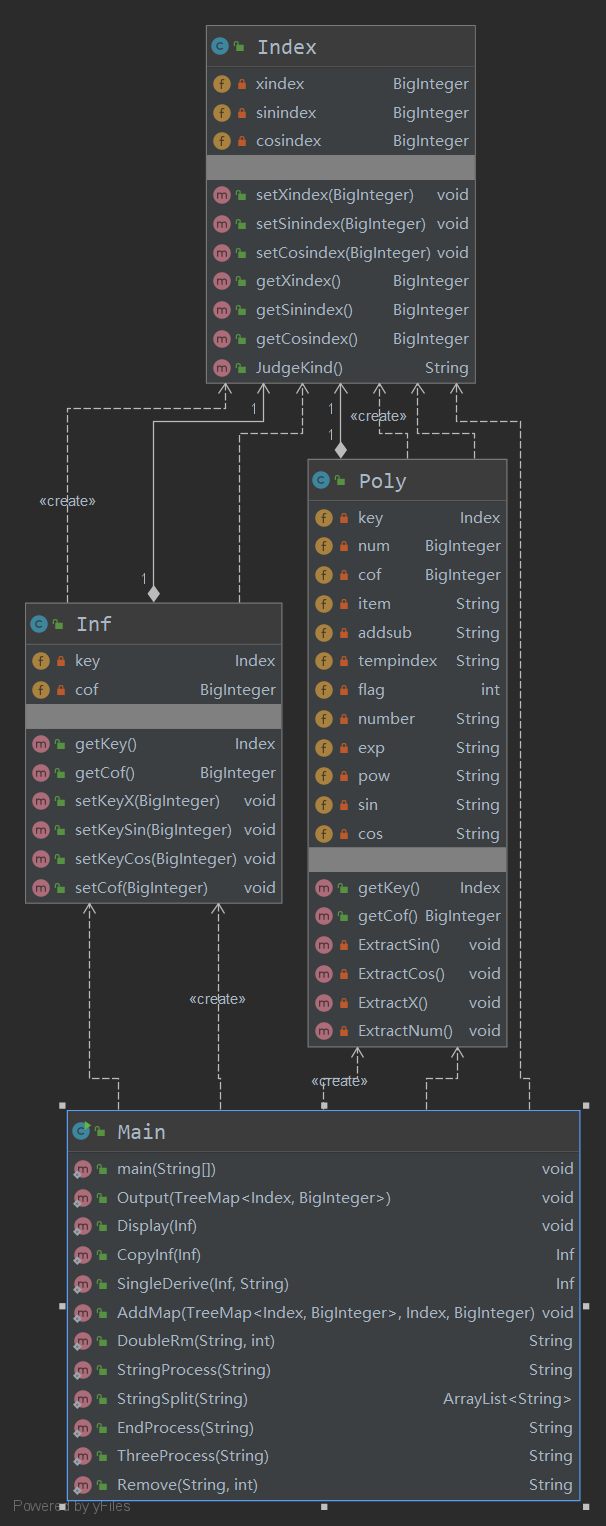
第二次作业中我是在第一次作业的基础上添加了三个类用来存储三个因子作为一个整体信息单位的信息。看起来有了一点OO的意味,但是写完三次作业回头来看,本人第二次作业使用的类并不是为了构建OO的思想架构而是在迫不得已的情况下为了沿袭第一次作业的TreeMap思想,不得已加入几个存储信息的类。那些类的作用实质上仅仅封装了数据,类似于C语言的结构体,实际上并没有什么架构上的改变,这是我需要在今后的设计中进行改进的。类的作用不应仅仅局限于封装数据,而是发挥它们真正强大的功能。 -
复杂度分析
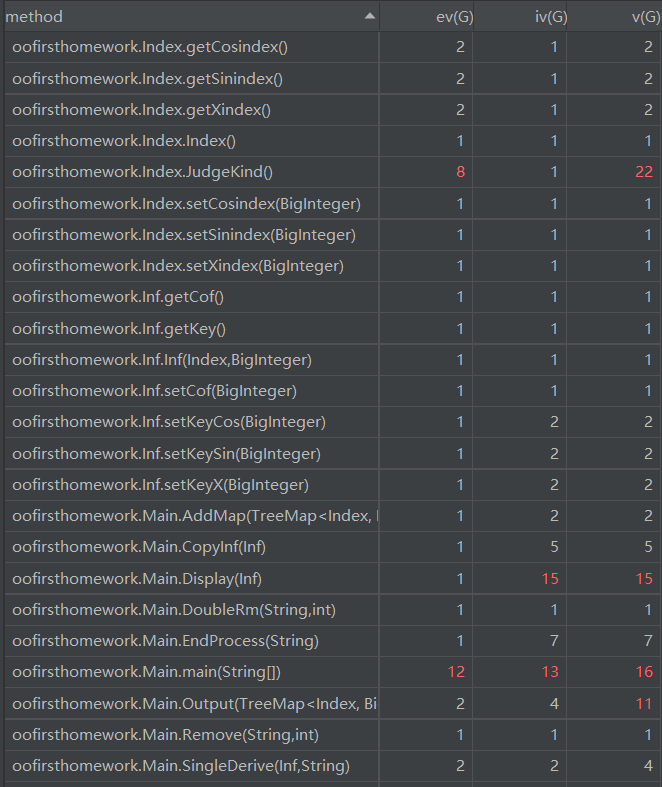
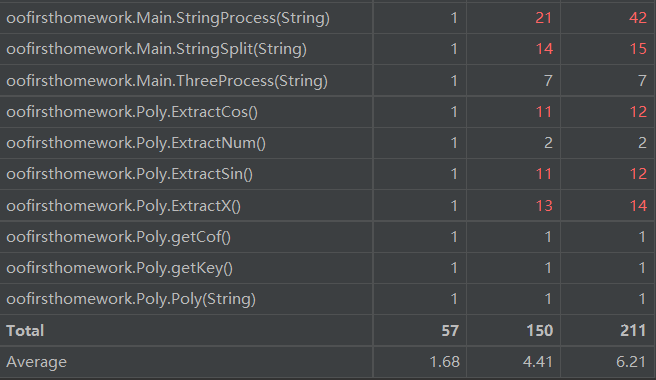
第二次作业的整体结构较第一次作业明显复杂了许多,所以整体复杂度也有所上升。图中所示我的main方法基本复杂度是最高的,其他复杂度也很高,原因在于我给TreeMap的排序接口comparator进行了重写,因为Key是我自己定义的类。这部分重写我需要对自定义类里的三个指数依次进行比较判断,导致if-else结构很多,复杂度提升。之后查资料我发现这个方法重写也可以在自定义类内进行,这样可以大大降低main方法的复杂度,让main方法看起来更简洁。
除了main方法,还有几个方法复杂度较高。Stringprocess、display、judgekind等方法复杂度都较高,这就是我在UML分析里所说的,我在第二次作业中新建的几个类并没有帮助我降低整体结构的复杂度也没有降低耦合度,仅仅是封装了数据,所以复杂度高的方法内部仍然有许多if-else判断和过程式的残留痕迹。这些都需要我在以后的学习中尽力克服,养成良好的习惯和思想。
hack与被hack
我在第二次作业中终于第一次体会了互测的快(刺)乐(激)。我第一次有机会看到别人的代码,我抱着学习的心态,把每一份代码都下载下来看一看。但是我发现除了几份架构清晰、逻辑至少能看明白的代码外,其他的真的很难理解,也不知道他想干什么。所以,我决定不用完全看懂代码,直接上测试数据。
测试方面,我其实不习惯于使用自己搭建的评测机,因为我觉得那样覆盖性不好,而且重复数据较多,效率不高。我更喜欢自己根据指导书,自己手动构造一些特殊易错数据进行自己的测试和互测的用例。实践证明,互测中我使用的都是我自己在写代码的时候自己积累下来测试自己程序的用例,效果还可以,至少每组数据都至少能hack到一个房间内成员。
第二次作业我自己程序的bug又是出在了化简的过程,又是在某一种情况下少输出了一个+(再一再二,不能……。
小提示(给自己以后准备的
JAVA语言中类是引用类型的,所以当类作为参数传递时,对参数的操作也会对外部的类变量产生改变。所以在相对类的部分进行操作并产生新的类时,一定要进行clone或是copy。在本次作业中我就使用了这种方法来进行操作,先来看代码:
```
public static Inf CopyInf(Inf a) {
Inf newInf = new Inf(null, null);
if (a.getKey().getXindex() != null) {
newInf.setKeyX(new BigInteger(a.getKey().getXindex().toString()));
}
if (a.getKey().getSinindex() != null) {
newInf.setKeySin(new BigInteger(a.getKey().getSinindex().toString()));
}
if (a.getKey().getCosindex() != null) {
newInf.setKeyCos(new BigInteger(a.getKey().getCosindex().toString()));
}
if (a.getCof() != null) {
newInf.setCof(a.getCof());
}
return newInf;
}```
这段代码是我在进行乘法求导时,对其中一个因子进行求导,剩余的不变时,要进行这个方法的调用,进行信息的复制。但是之后我查资料发现,JAVA中的基本类型(int,String等)和基本类型包装类(Integer,BigInteger等)这两类变量是不会导致内部信息变化的,所以其实在我这个第二次作业中,不进行信息复制也是可以的。不过我在这里就是想给以后的自己和看到这篇文章的读者们提个醒,在对同一个类进行多次操作且每次操作都要基于原始数据的情况下,不要忘记进行clone或是copy。不然这种隐蔽的错误真就写bug一分钟,debug到两点钟。
第三次作业——嵌套表达式求导
作业思路和心得
第三次作业较之前两次难度再次提升。我感觉难度最大的部分就是输入的读取和WF的判断。由于增加了嵌套表达式,整个输入的结构变得十分灵活而复杂。表达式里会有因子,因子里又会有表达式,这样对输入的处理是极大的困难。
为了提高性能,我采用了WF判断和输入的分析读取合在一起进行。先使用第二次作业中的Stringprocess方法将多余的符号去掉,再从头开始循环读取。读取的时候,判断括号数量是否匹配。其余WF在读取之前先遍历一遍字符串进行判断。
读取好各个因子后,就可以建立表达式树,建好后就按链式求导法则,对整棵树进行求导,求导后输出即可。在此,我要提一下我的第一版方法,就是将求导方法交给每个类内部自己管理,每个类内部也有自己的数据,这样,我最开始的想法是让类自己调用各自的方法,递归求导。但是我实现后发现,这样复杂度和空白数据量都太大了,而且逻辑也不清晰,就放弃了这个方法。最后选择了建树的方法。由于自己的数据结构基础也不够扎实,在学习建立表达式树的期间也费了好一番力气,查阅了大量网站资料。所以,我要告诉自己,基础要打好呀!(相信现在说为时也还不晚
程序结构分析
-
UML分析
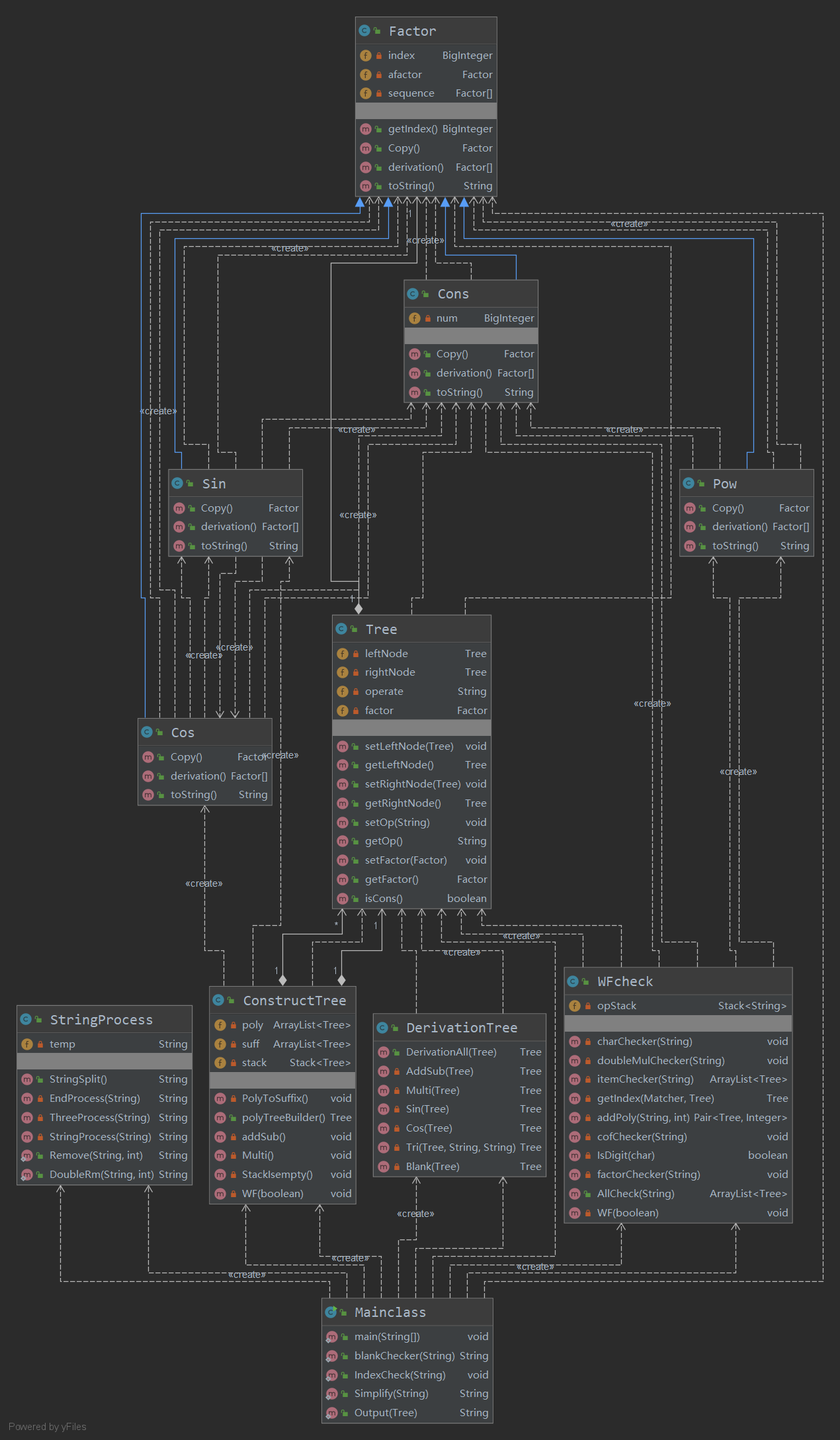
由于这次结构较复杂,所以为了减少代码量,我使用factor作为四种因子的父类,减少重复代码。此外,由于我的StringProcess和WF都是重新遍历了输入,所以与其他模块关联不大,我觉得这让我的这两个模块提高了可移植性和重用性,所以这两个模块是我较为满意的模块。表达式树的那几个模块,由于之前我对树的掌握不牢,导致这部分建树没有什么思路上的创新,按照固有方法和套路进行编写。也导致了之后输出的化简很难操作。 -
复杂度分析
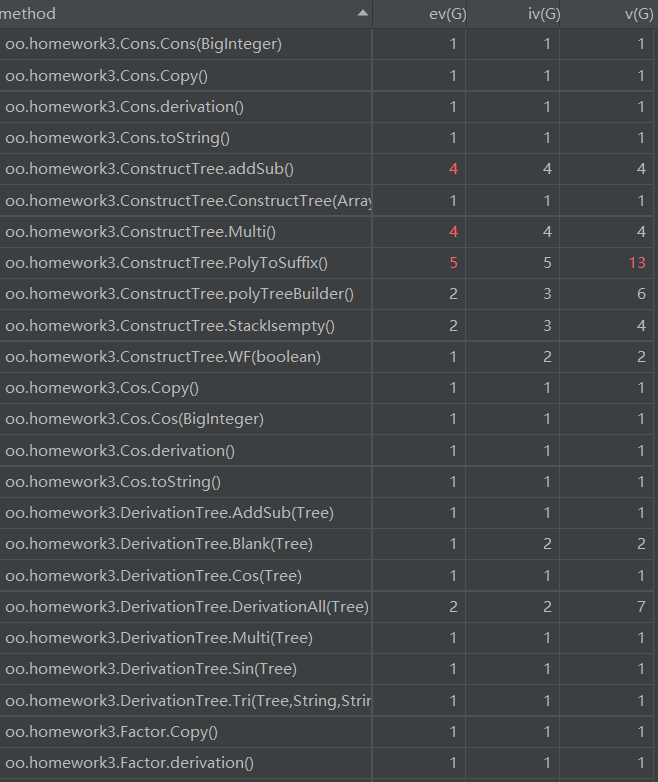

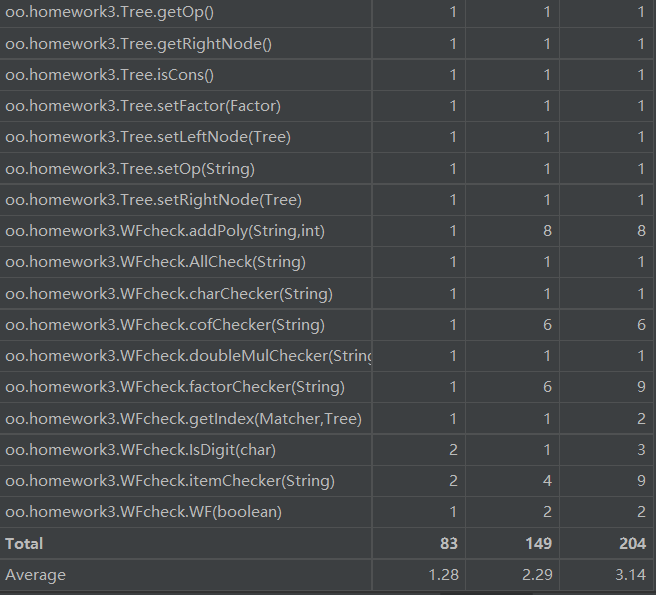
由于程序复杂度的提升,方法的数量也大幅度提升,方法的复杂度倒是没什么巨大的增加。我分析原因在于我进行重构,选择表达式树之后,之前的一些复杂的大方法被我拆解为各个小方法放到类中,自己管理。所以方法的数量增加了,但是复杂度没什么暴增。
hack与被hack
第三次作业我自己的程序的bug主要出在WF判断这部分,我在本地自己测试时,就发现很多不该判WF的判成了WF,该判WF的却输出了结果。我对这些问题对程序打了很多个补丁,但是在强测和互测中还是发现了几个自己没有发现的点,导致了错误。这让我明白了自己构造数据的时候的方法有问题,我会在今后的作业的构造数据的过程中,注意改正,争取得到更好的测试效果。
在第三次互测中,随着程序体积的膨胀,完全阅读懂代码变得更加不现实了,所以我依旧采用第二次作业的方法。在互测中提交自己本地测试出现问题的用例,同时想一想别的常用方法会出现什么问题。效果也还是不错,很少有无效用例,大多都是找到了同组人员的bug的。
整体感悟思考
从寒假的一无所知到preview的有所了解到unit1的稍有理解,可以说这门课程让我一步步地走进了面向对象编程的世界。这一级级台阶也要感谢课程组的老师和助教们。
但是回头看来自己的三次作业,发现面向对象的一些常用的pattern还没有灵活运用,一些常用的思想也还没有深入理解。这些都需要我在今后的课程中努力学习,尽力理解的东西。
我也在第一单元作业的历练中,发现了一个适合自己的写测结合的方式。我喜欢每写完一部分就认认真真、仔仔细细地测试一遍这一部分的功能是否正确。直到在我看来,这部分写完的代码功能上完全没有问题我才会继续写下去。这样我感觉虽然用时较多,但是写起来让我自己感觉更加安心,同时也让debug的难度有所减小。我感觉是适合我自己的编写方法。我会在今后的作业中,继续使用这种方法,希望能够取得良好的效果。