python图形分类问题(cifar10数据)
数据来源天池。
1.导入数据,查看数据
import pickle #用pickle来读取文件
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy import ndimage #用ndimage来处理图像
from tensorflow.keras import layers #layers用来定义层
#定义打开文件的函数,得到一个字典
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
#定义从文件读取(不标准化x,不One-Hot编码y)数据的函数,得到x,y
def load_rawdata(file):
dic = unpickle(file)
data = pd.DataFrame.from_dict(dic,orient = 'index')
#第一行为标签数据,第二行为图片数据(1000x3027)
x = data.iloc[2][0].reshape(10000,32,32,3,order ='F')
#数据里每张照片为一维数据需要reshape处理得到真实的照片数据
y = data.iloc[1][0] #也可以直接用字典的key读,这里只是为了熟悉pandas操作
#得到标签数据, (0~9),如果是文本标签还需要转成数字
return x, y
#定义从文件读取并预处理数据的函数,得到一组xdata,ydata数据(均预处理过)
def load_data(file):
xdata,ydata = load_rawdata(file)
xdata = xdata.astype('float32')/255 #标准化
ydata = tf.keras.utils.to_categorical(label_data) #One-Hot编码
return xdata,ydata
#查看标签列表,在batches.meta文件中
names = unpickle('batches.meta')
species = names[b'label_names']
def tostr(species):
for i in range(len(species)):
species[i] = species[i].decode()
将每个二进制编码的标签转为utf8编码的标签
tostr(species)
print(species)
#定义查看图片的函数,最多可以查看25个
def plot_images_labels_prediction(images,labels,prediction,idx,num=10):
fig=plt.gcf()
fig.set_size_inches(10,10)
if num>25: num=25
for i in range(num):
ax = plt.subplot(5,5,i+1)
img = ndimage.rotate(images[idx],-90)
ax.imshow(img,cmap='binary')
title= str(idx)+' '+species[labels[idx]] #显示数字对应的类别
if len(prediction)>0:
title+= '=>'+ species[prediction[idx]] #显示数字对应的类别
ax.set_title(title,fontsize=10)
ax.set_xticks([])
ax.set_yticks([])
idx+=1
plt.show()
#我们可以先试着打开第一个文件,并读取前十张图片并展示 images,labels = load_rawdata('data_batch_1') plot_images_labels_prediction(images,labels,[],0,10)

2.读取全部数据(data_batch_i),加在一起作为训练数据def get_all_data():
for i in range(5):
file = 'data_batch_'+str(i+1)
if i==0:
x,y = load_data(file)
else:
t = load_data(file)
x = np.concatenate((x,t[0]))
y = np.concatenate((y,t[1]))
return x,y
x_train,y_train = get_all_data()
print(x_train.shape,y_train.shape) #因为文件有五个data_batch所以需要加在一起形成一个大的数据集,然后在进行训练
3.搭建模型
model = tf.keras.models.Sequential()
model.add(layers.Conv2D(filters=32,kernel_size=(3,3),padding='same',input_shape=(32,32,3),activation='relu'))
model.add(layers.Dropout(0.1))
model.add(layers.Conv2D(filters=32,kernel_size=(3,3),padding='same',activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Conv2D(filters=64,kernel_size=(3,3),activation='relu',padding='same'))
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(filters=64,kernel_size=(3,3),padding='same',activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Conv2D(filters=128,kernel_size=(3,3),activation='relu',padding='same'))
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(filters=128,kernel_size=(3,3),padding='same',activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2,2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.3))
model.add(layers.Dense(2000,activation='relu'))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(1000,activation='relu'))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(10,activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
模型较长,这是部分截图,可以看出参数量特别大,所以尽量用Maxpooling减少计算量,不然后面会等好久才会出结果。
刚刚开始训练时候可以把参数调很多(增大filter数目,增加层数),过拟合也不要紧,主要是看训练集上能否达到要求,如果过拟合都达不到要求,那么可能是模型选择的问题。
3.开始训练,得到训练结果
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
train_history=model.fit(x_train,y_train,validation_split=0.2,epochs=10,batch_size=128,verbose=1)
def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.xlabel('epoch')
plt.ylabel(train)
plt.legend(['train','validation'],loc='upper left')
plt.xticks([x for x in range(len(history[train])+ 1)if x % 2 == 0]) # x标记step设置为2
show_train_history(train_history,'accuracy','val_accuracy')
show_train_history(train_history,'loss','val_loss')
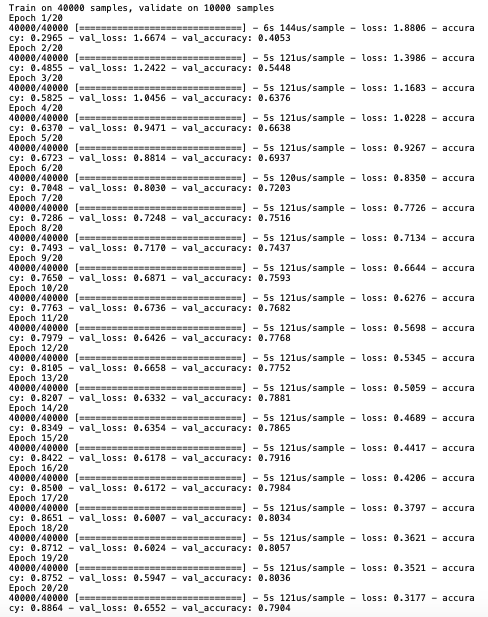
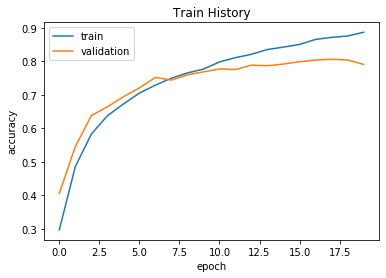
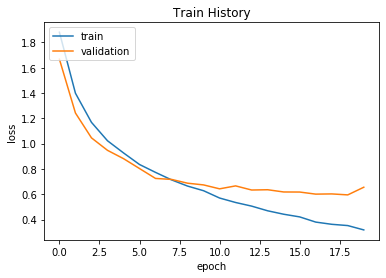
从图中可以看出训练集上正确率上升明显,但是测试集上正确率随着迭代次数增加而趋于平缓,在后面训练集上的测试结果明显优于测试集说明了此时已经过拟合了,
在迭代8次左右的时候已经接近过拟合,之后模型在测试集上训练结果不会变好甚至可能会变差。
4.测试集上测试,对比训练集上的结果
x_test,y_test = load_data('test_batch')
print(x_test.shape,y_test.shape)
loss, acc = model.evaluate(x_test, y_test,verbose=2)
prediction = model.predict_classes(x_test)
print(prediction.shape) #prediction是np.ndarray类型
x_testimg,y_testlabel = load_rawdata('test_batch')
table = pd.crosstab(np.array(y_testlabel),prediction,rownames=['label'],colnames=['predict']) #而y_testlabel为list类型所以要强转一下
table
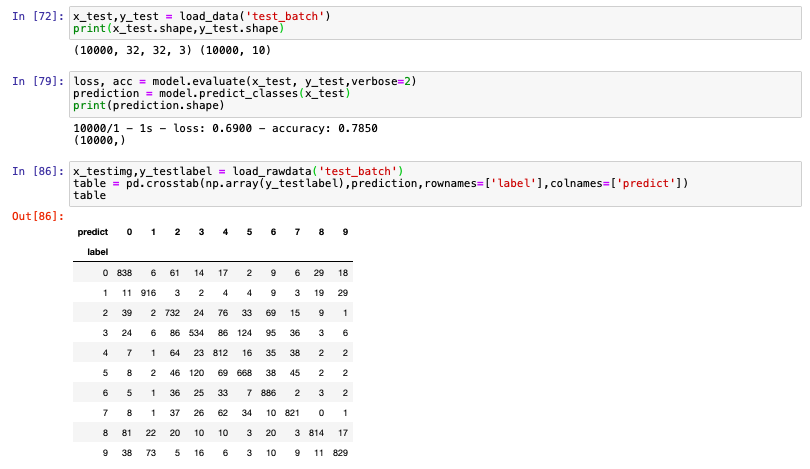
从这个表我们可以看出来哪些label容易被认错,在测试集上我们的正确率只有0.785,损失值为0.69,
相比训练集,正确率差了将近百分之10。(过拟合导致的还是模型设计不足导致的呢?)
5.结果评估+进一步改进+验证猜想
如果想知道是否是模型的原因导致正确率上不去,我们需要重新构建新的模型,然后重新训练,浪费大量的时间和精力。
我们姑且先相信自己的模型,然后
1.方案一:迭代次数过多导致的过拟合:我们人为的进行early_stop,就是epochs设为7,8,9时候看模型在测试集上的结果对比0.785
2.方案二:数据不足导致的过拟合:我们将50000张训练集上的图片进行旋转翻折操作,旋转角度设为30,60,90,45的操作得到4*50000张新的数据,
上下翻折,左右翻折得到2*50000张新数据,这样我们多了6*50000张的新数据。
5.1 迭代次数过多导致的过拟合
我们现在使用early_stopping的策略来减少模型的过拟合。
# early stoppping from tensorflow.keras.callbacks import EarlyStopping early_stopping = EarlyStopping(monitor='val_loss', patience=5, verbose=1) # 训练 model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy']) history = model.fit(x_train, y_train, epochs=50, batch_size=100, validation_split = 0.2, verbose=1, shuffle=True, callbacks=[early_stopping]) #train_history2=model.fit(x,y,validation_split=0.2,epochs=20,batch_size=1000,verbose=1)
我们使用下面增加dropout并且减少模型参数后的模型,用小数据50000个数据来训练我们的model,得到结果:
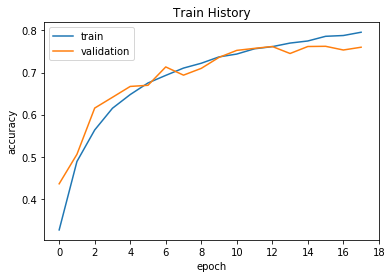

可以看出来模型在第18次迭代后停止,因为模型测得第19次的val_loss会上升从右图可以看出来;
测试集上正确率为75.71%比之前反而少了3个百分点,说明导致过拟合的原因并不是正确的模型训练过度,
而是因为模型本身参数错误(导致很容易在没有达到最优点前就过拟合)(模型误差)以及数据量过小(系统误差,可以人为增强数据来解决)的问题;
下面一个方案可以较好地解决这一问题。

5.2 数据不足导致的过拟合
model = tf.keras.models.Sequential() model.add(layers.Conv2D(filters=32,kernel_size=(3,3),padding='same',input_shape=(32,32,3),activation='relu')) model.add(layers.Dropout(0.4)) model.add(layers.Conv2D(filters=32,kernel_size=(3,3),padding='same',activation='relu')) model.add(layers.MaxPooling2D(pool_size=(2,2))) model.add(layers.Conv2D(filters=64,kernel_size=(3,3),activation='relu',padding='same')) model.add(layers.Dropout(0.3)) model.add(layers.Conv2D(filters=64,kernel_size=(3,3),padding='same',activation='relu')) model.add(layers.MaxPooling2D(pool_size=(2,2))) model.add(layers.Conv2D(filters=64,kernel_size=(3,3),activation='relu',padding='same')) model.add(layers.Dropout(0.3)) model.add(layers.Conv2D(filters=64,kernel_size=(3,3),padding='same',activation='relu')) model.add(layers.MaxPooling2D(pool_size=(2,2))) model.add(layers.Flatten()) model.add(layers.Dropout(0.3)) model.add(layers.Dense(2000,activation='relu')) model.add(layers.Dropout(0.3)) model.add(layers.Dense(1000,activation='relu')) model.add(layers.Dropout(0.3)) model.add(layers.Dense(10,activation='softmax'))
因为前面分析我们知道了先前的模型存在过拟合的问题,所以我们增加了Dropout的值,并且减少了第三层的filter数目,从128减小至64,减少模型参数也有利于防止过拟合。
#对图片进行旋转操作,得到新图片加在原来图片数据集中得到更大的训练集(之后人为还需要做个预处理)
def rotate(images,angle):
temp = images.copy()
for i in range(len(images)):
temp[i] = ndimage.rotate(temp[i],angle,reshape = False,mode = 'nearest')
return temp
def rotall(xdata,ydata,angles):
tempx = xdata.copy()
tempy = ydata.copy()
for i in range(len(angles)):
tempx = np.concatenate((tempx,rotate(xdata,angles[i])),axis = 0)
tempy.extend(ydata)
return tempx,tempy
def flipall(xdata,ydata):#返回原来数据上下,左右翻折后的数据,之后与前面得到的旋转数据集合并
tempx = np.concatenate((xdata,xdata),axis = 0)
tempy = ydata+ydata
l = len(xdata)
for i in range(l):
tempx[i] = np.flip(xdata[i],axis = 0)
tempx[i+l] = np.flip(xdata[i],axis = 1)
return tempx,tempy
#定义get_all_rawdata函数获得所有初始图片信息
def get_all_rawdata():
for i in range(5):
file = 'data_batch_'+str(i+1)
if i==0:
x,y = load_rawdata(file)
else:
t = load_rawdata(file)
x = np.concatenate((x,t[0]))
y.extend(t[1])
return x,y
xdata,ydata = get_all_rawdata()
xdata_new, ydata_new = rotall(xdata,ydata,[30,60,90,45])
tx,ty = flipall(xdata,ydata)
xdata_new = np.concatenate((xdata_new,tx))
ydata_new.extend(ty)
#保存新的数据,因为数据量很大,丢了又得弄好久。
output = open('new_data','wb')
pickle.dump((xdata_new,ydata_new),output)
output.close()
#合并后还需要shuffle一下才能保证新加入的数据与原来数据混合均匀,进而减小混合不均匀带来的误差
r = np.arange(len(ydata_new))
np.random.shuffle(r)
x = xdata_new[r,:]
y = np.array(ydata_new)[r]
x = x.astype('float32')/255 #标准化
y = tf.keras.utils.to_categorical(y)
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
train_history2=model.fit(x,y,validation_split=0.2,epochs=50,batch_size=1000,verbose=1)

很明显现在的测试数据上的正确率从0.79提高到了0.85,增强数据的方法对数据过少而导致的过拟合很管用。
并且从图表可以看出依然没有到达过拟合点,还可以继续训练,此时测试集上的正确率有0.8015.
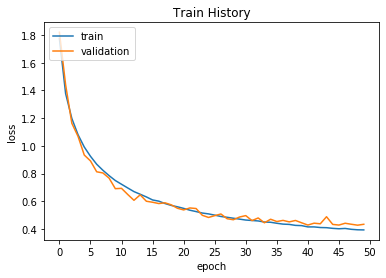
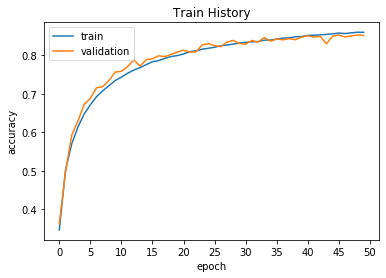

因此我在这个基础上对模型再继续训练20次后观察结果:


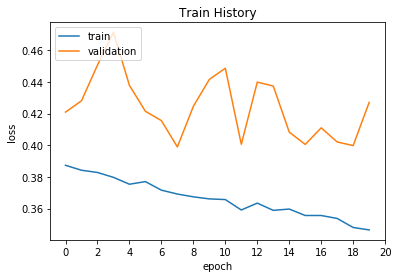
可以很明显的看出过拟合了,测试数据上的正确率和loss均在上下波动,不平滑,但是其中也会有比较好的点,
例如最好的一次正确率达到了86.28%比之前的85.14%高了许多,
最后我们还得测试一下这个模型现在在测试集上的结果,得到:80.25%的正确率,比之前多了0.1个百分点。
可见对数据进行预处理并且增强数据可以达到事半功倍的效果。
机器学习问题可以大致分为回归问题(预测一个值),分类问题,聚类问题,决策问题,数据分析相关问题。
机器学习的是规律、关系,学不出方法的,学习的方法来源于数学,可以说上述问题都可以转化为数学建模问题。
未来更新
隐马尔可夫模型(Hidden Markov Model, HMM)、马尔可夫随机场(Markov Random Field, MRF)和马尔可夫决策(Markov decision process, MDP)等马氏理论相关的总结。