本文来自Rancher Labs
作者介绍
王海龙,Rancher中国社区技术经理,负责Rancher中国技术社区的维护和运营。拥有6年的云计算领域经验,经历了OpenStack到Kubernetes的技术变革,无论底层操作系统Linux,还是虚拟化KVM或是Docker容器技术都有丰富的运维和实践经验。
在实际使用Rancher过程中,偶尔会因为误操作删除了System Workload、节点或集群, 导致集群状态异常而无法访问。如果用户不了解恢复方法,通常会重新添加节或重新搭建集群。
本文将根据以下几个场景来介绍如何恢复由于误操作引起的Rancher集群故障:
-
如何恢复System Project Workload
-
如何恢复从Rancher UI或kubectl误删的节点
-
如何恢复执行过清理节点脚本的节点
-
如何恢复被删除的
custom集群
重要说明
-
本文档基于Rancher 2.4.x测试,其他版本操作可能会略有不同
-
本文介绍的场景均是针对
custom集群 -
如果您在此过程中遇到问题,则应该熟悉Rancher架构/故障排除
-
您应该熟悉单节点安装和高可用安装之间的体系结构差异
如何恢复System Project Workload
System Project中包含了一些保证该集群能够正常运行的一些workload,如果删除某些workload可能会对该集功能群造成影响。
通常情况下,通过RKE创建的custom集群应包括以下workload:
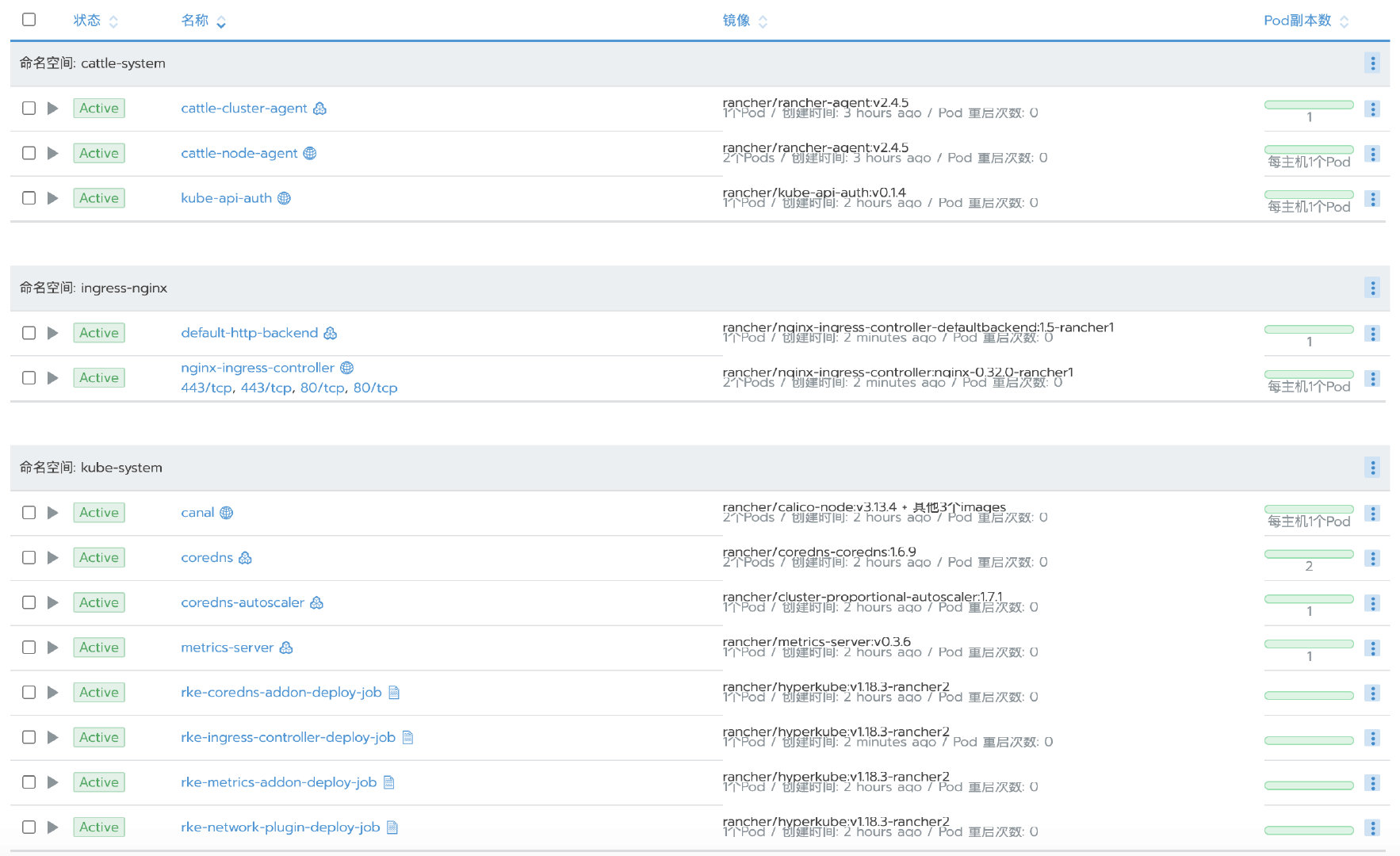
下面我们来分别介绍如果误删了这些workload之后应如何恢复。
恢复cattle-cluster-agent和cattle-node-agent
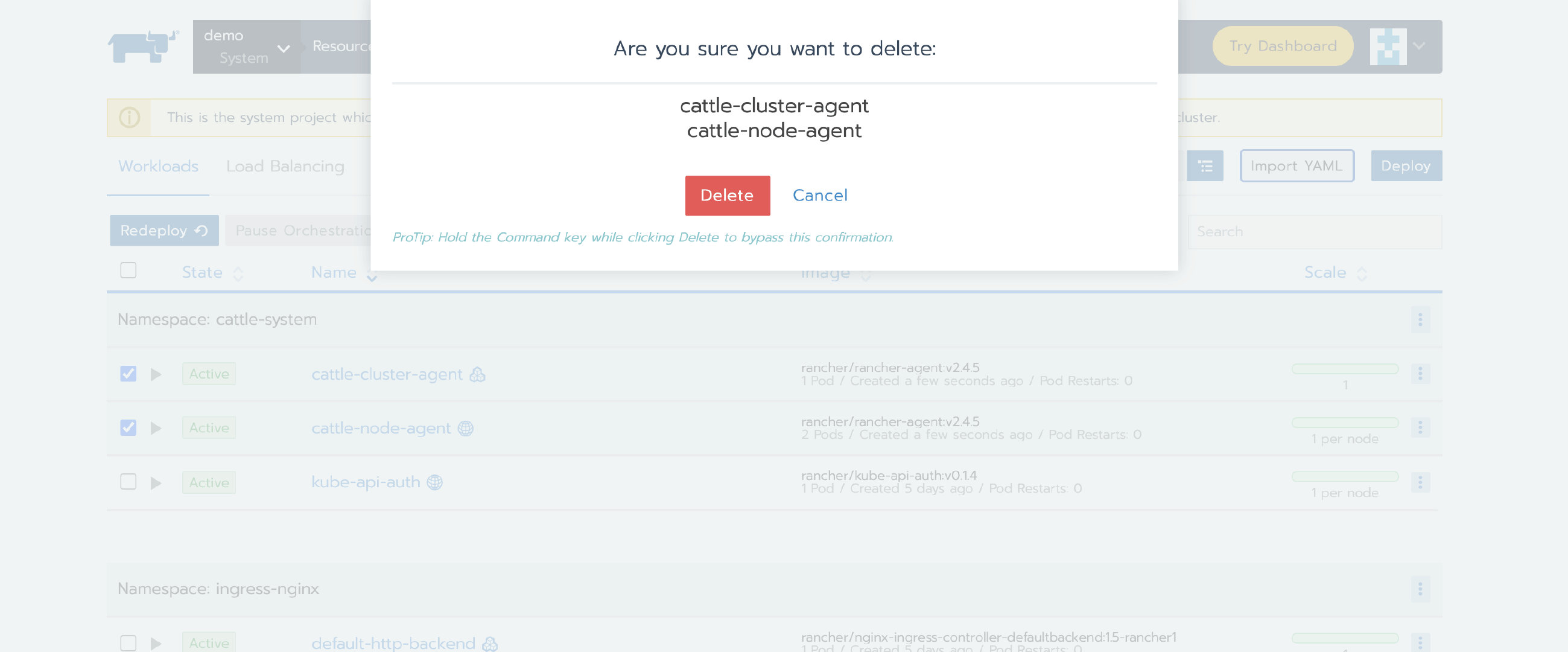
模拟故障
从System Project下删除 cattle-cluster-agent和cattle-node-agent
生成Kubeconfig和集群yaml
1.在Rancher UI上创建API token(用户-> API & Keys)并保存Bearer Token

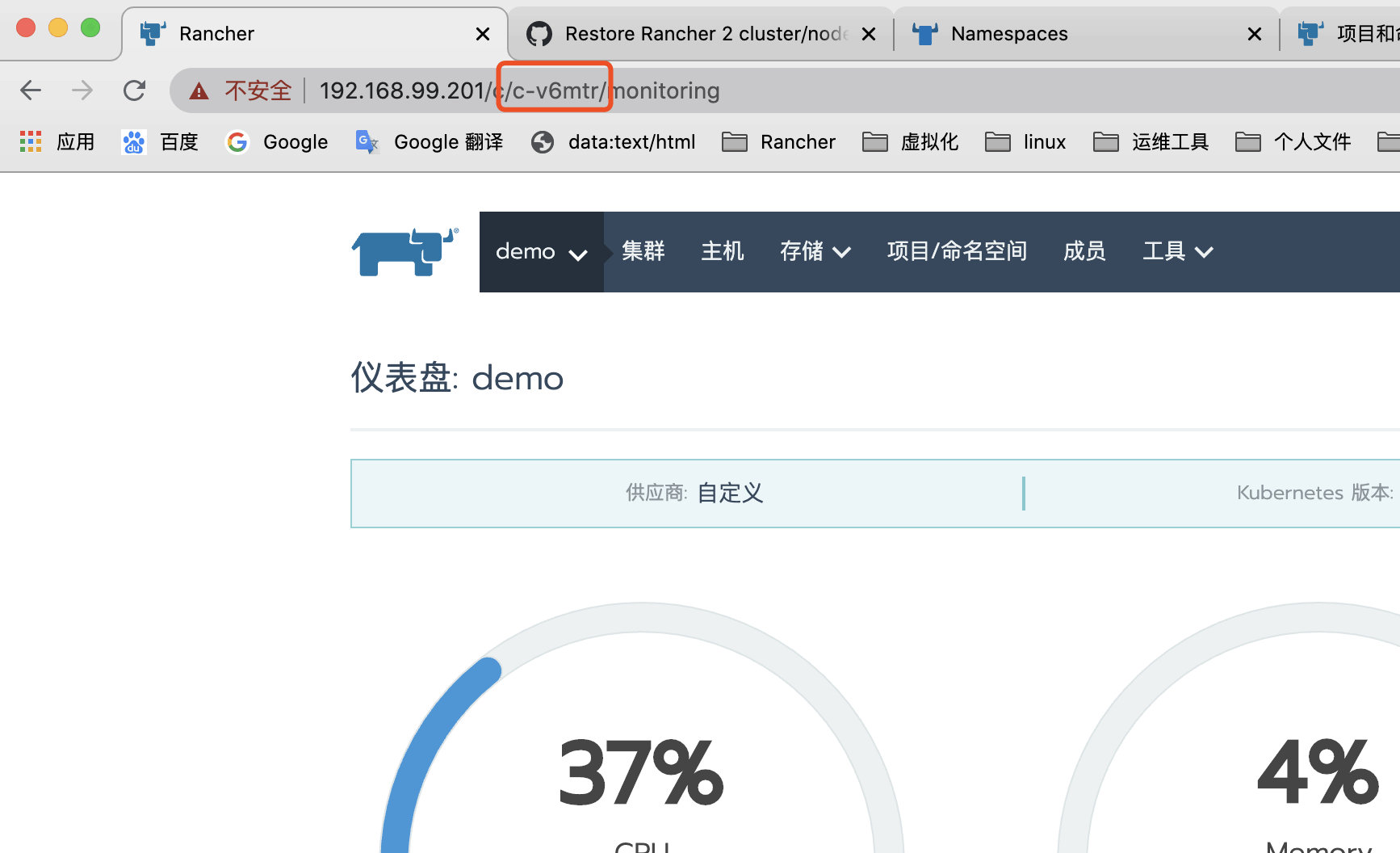
2.选择集群后,在Rancher UI(格式为c-xxxxx)中找到其clusterid,并在地址栏中找到它。
3.根据步骤1-2获取的变量替换:RANCHERURL、CLUSTERID、TOKEN(主机需要安装curl和jq)
# Rancher URL
RANCHERURL="https://192.168.99.201"
# Cluster ID
CLUSTERID="c-v6mtr"
# Token
TOKEN="token-klt5n:2smg6n5cb5vstn7qm797l9fbc7s9gljxjw528r7c5c4mwf2g7kr6nm"
# Valid certificates
curl -s -H "Authorization: Bearer ${TOKEN}" "${RANCHERURL}/v3/clusterregistrationtokens?clusterId=${CLUSTERID}" | jq -r '.data[] | select(.name != "system") | .command'
# Self signed certificates
curl -s -k -H "Authorization: Bearer ${TOKEN}" "${RANCHERURL}/v3/clusterregistrationtokens?clusterId=${CLUSTERID}" | jq -r '.data[] | select(.name != "system") | .insecureCommand'
以上命令执行成功后,将返回导入集群的命令,请做好备份,命令如下:
curl --insecure -sfL https://192.168.99.201/v3/import/2mgnx6f4tvgk5skfzgs6qlcrvn5nnwqh9kchqbf5lhlnswfcfrqwpr.yaml | kubectl apply -f -
恢复cattle-cluster-agent和cattle-node-agent
1、在具有controlplane角色的节点上生成kubeconfig
docker run --rm --net=host -v $(docker inspect kubelet --format '{{ range .Mounts }}{{ if eq .Destination "/etc/kubernetes" }}{{ .Source }}{{ end }}{{ end }}')/ssl:/etc/kubernetes/ssl:ro --entrypoint bash $(docker inspect $(docker images -q --filter=label=io.cattle.agent=true) --format='{{index .RepoTags 0}}' | tail -1) -c 'kubectl --kubeconfig /etc/kubernetes/ssl/kubecfg-kube-node.yaml get configmap -n kube-system full-cluster-state -o json | jq -r .data."full-cluster-state" | jq -r .currentState.certificatesBundle."kube-admin".config | sed -e "/^[[:space:]]*server:/ s_:.*_: "https://127.0.0.1:6443"_"' > kubeconfig_admin.yaml
2、应用更新
将
https://xxx/v3/import/dl75kfmmbp9vj876cfsrlvsb9x9grqhqjd44zvnfd9qbh6r7ks97sr.yaml替换为生成Kubeconfig和集群yaml步骤中生成的yaml连接,本例为https://192.168.99.201/v3/import/2mgnx6f4tvgk5skfzgs6qlcrvn5nnwqh9kchqbf5lhlnswfcfrqwpr.yaml
docker run --rm --net=host -v $PWD/kubeconfig_admin.yaml:/root/.kube/config --entrypoint bash $(docker inspect $(docker images -q --filter=label=io.cattle.agent=true) --format='{{index .RepoTags 0}}' | tail -1) -c 'curl --insecure -sfL https://xxx/v3/import/dl75kfmmbp9vj876cfsrlvsb9x9grqhqjd44zvnfd9qbh6r7ks97sr.yaml | kubectl apply -f -'

验证
接下来通过Rancher UI或kubectl可以看到 cattle-cluster-agent和cattle-node-agent 已经恢复。


恢复kube-api-auth
默认情况下,RKE 集群会默认启用授权集群端点。这个端点允许您使用 kubectl CLI 和 kubeconfig 文件访问下游的 Kubernetes 集群,RKE 集群默认启用了该端点。
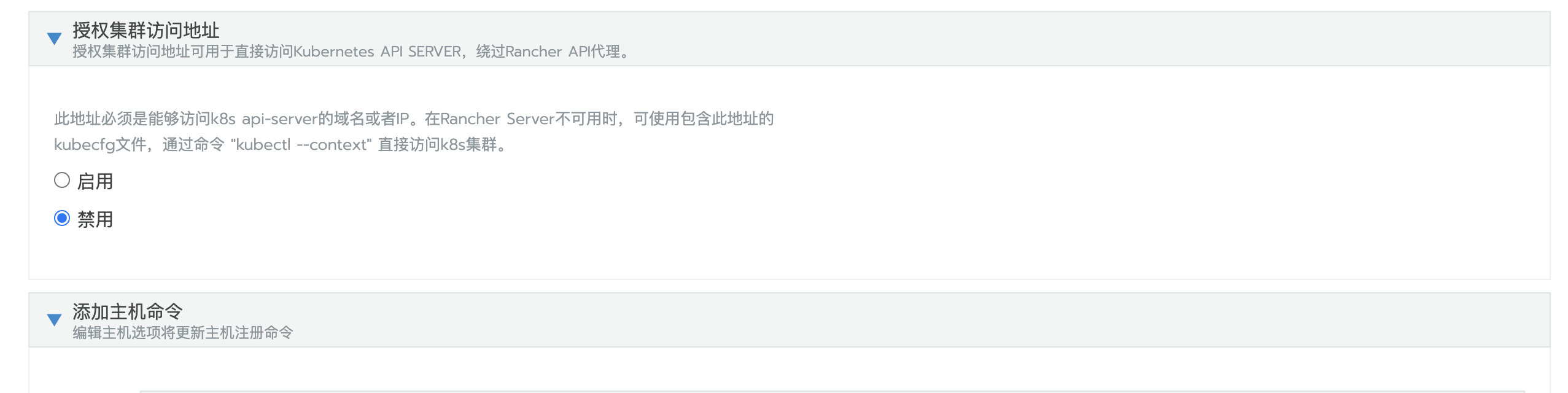
如果误删kube-api-auth,恢复的方法也很简单,只需要编辑集群,将“授权集群访问地址”修改成禁用,保存集群。然后再用相同的方法启用 “授权集群访问地址”即可。
1、编辑集群
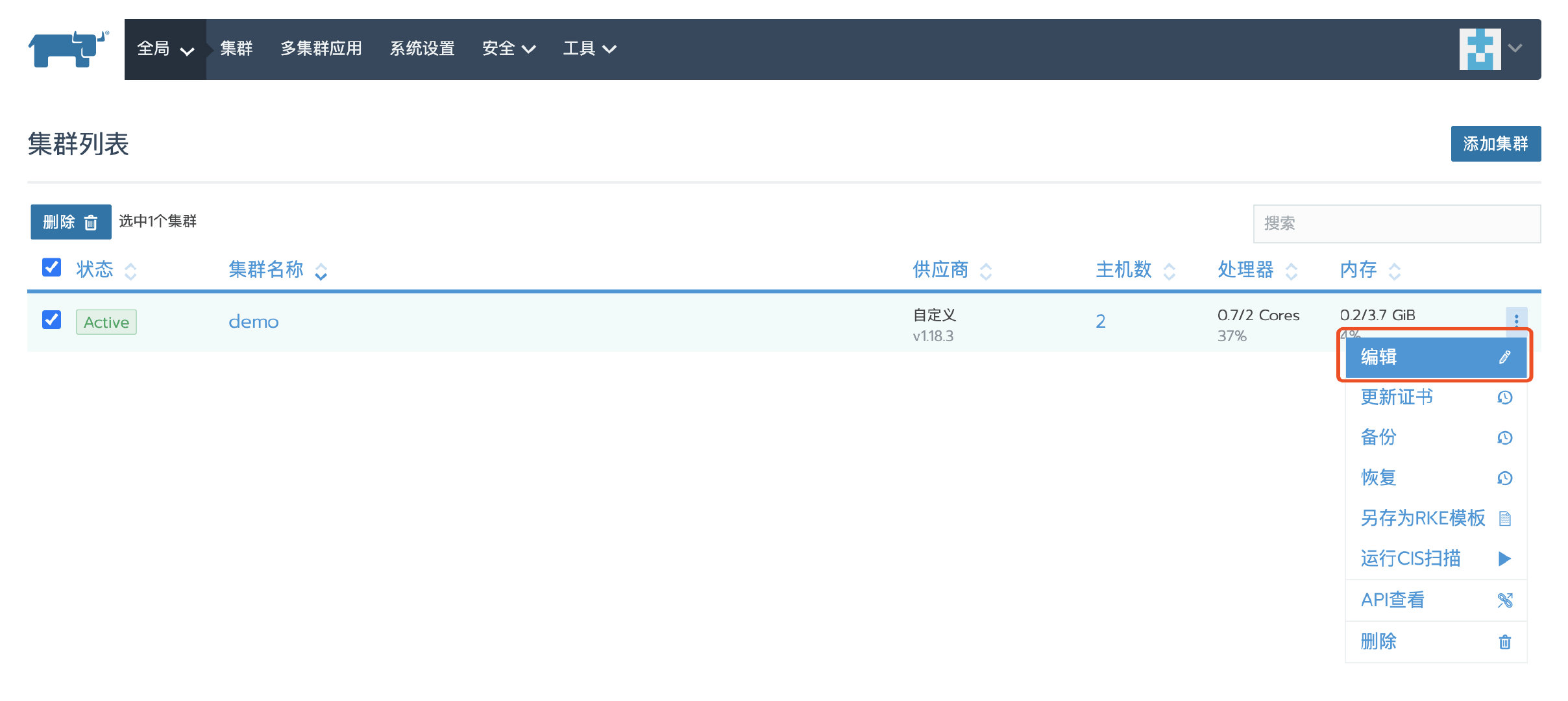
2、禁用授权集群访问地址,保存
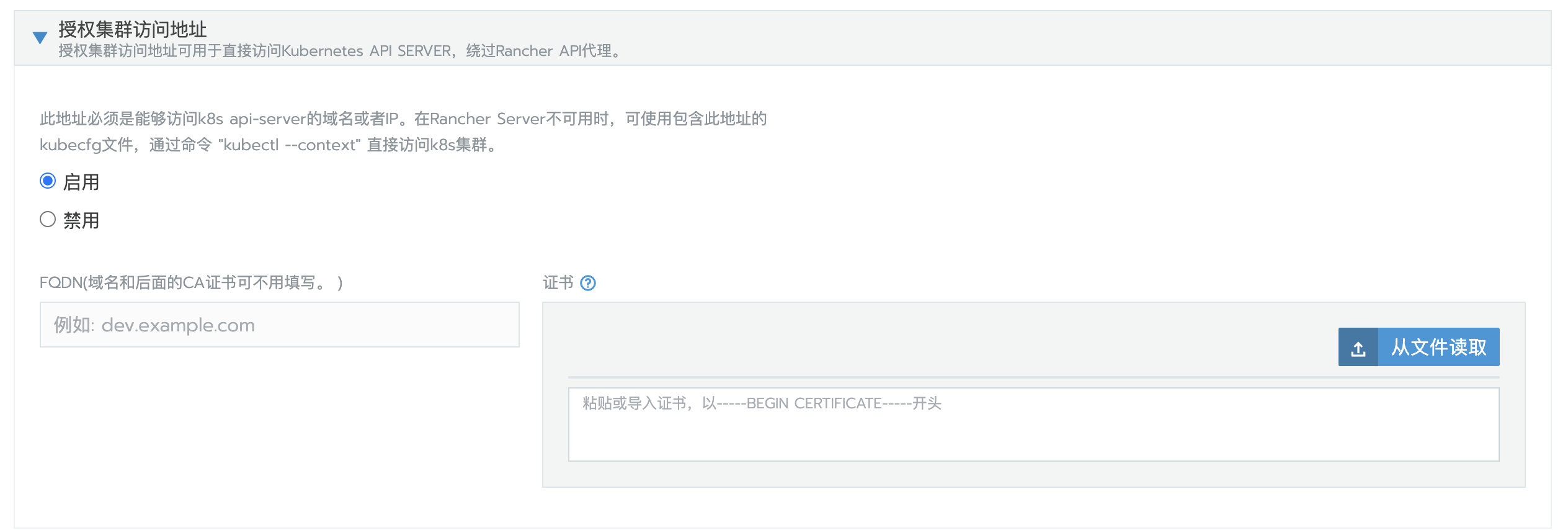
3、再次编辑集群,启用授权集群访问地址,保存
恢复nginx-ingress-controller、canal、coredns、metrics-server组件
nginx-ingress-controller、canal、coredns、metrics-server 这些workload都是通过kube-system命名空间下的各种job来创建的,所以如果要重建这些workload只需要重新执行对应的job即可。
本例使用nginx-ingress-controller做演示,其他workload的恢复步骤可以参考此恢复方案。
模拟故障
从System Project下删除 kube-system 下的default-http-backend和nginx-ingress-controller

执行恢复
-
从
kube-system命名空间下删除rke-ingress-controller-deploy-job(如果不删除对应的job,更新集群后,不会重新触发job重新执行) -
为了触发集群更新,可以编辑集群,修改NodePort范围,然后保存。
验证
集群更新成功后,回到System Project下确认default-http-backend和nginx-ingress-controller已经重新创建。

如何恢复从Rancher UI或kubectl误删的节点
当节点处于“活动”状态,从集群中删除节点将触发一个进程来清理节点。如果没有重启服务器,并不会完成所有的清除所有非持久化数据。
如果无意中将节点删除,只需要使用相同的参数再次添加节点即可恢复集群。
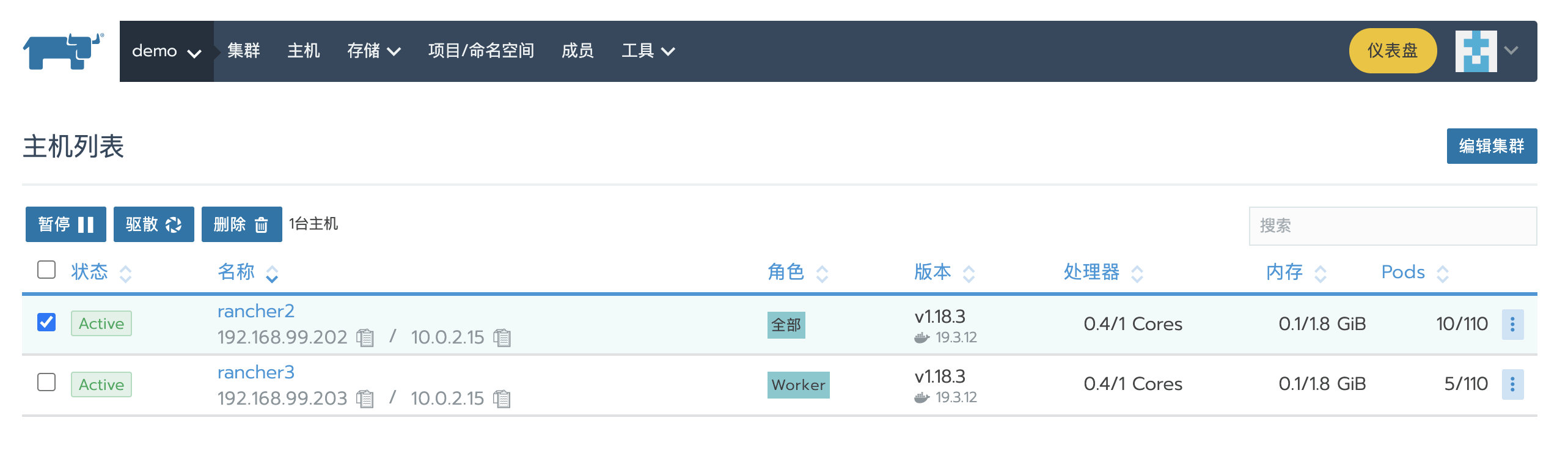
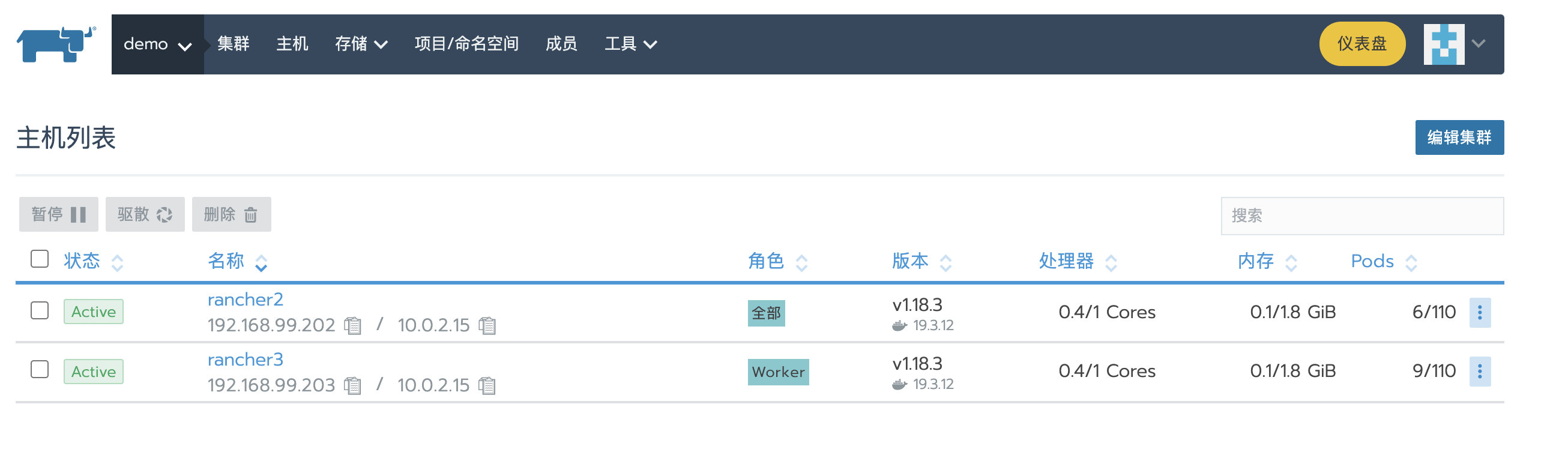
比如我的环境有两个节点,分别具有全部和Worker角色
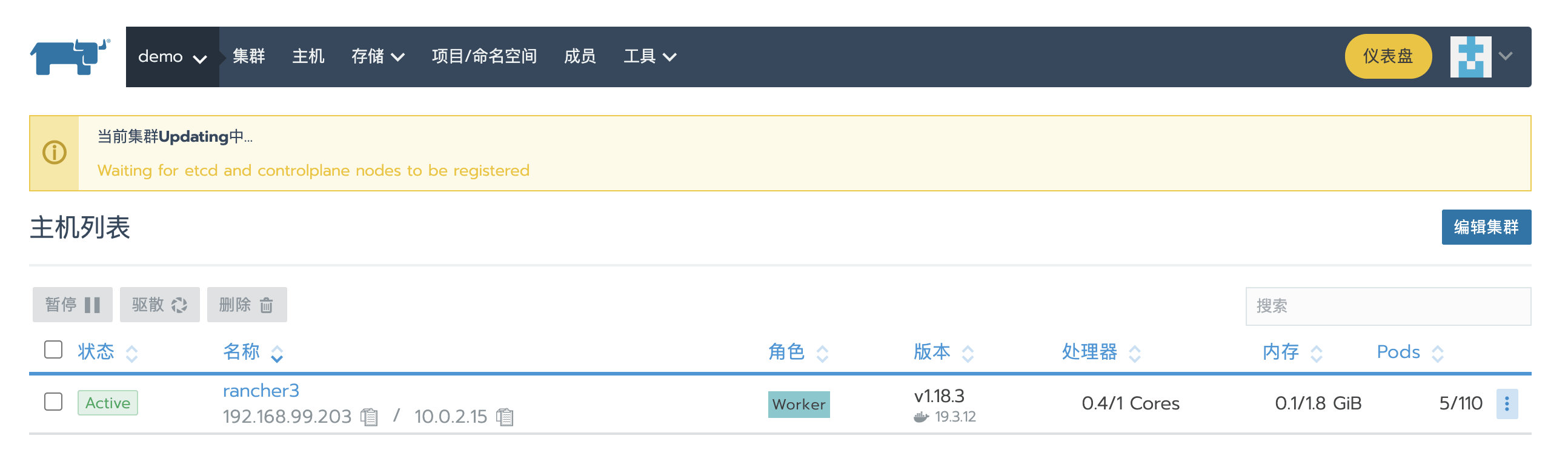
从Rancher UI或kubectl将节点rancher2删除,此时集群中只剩下一个rancher3节点,由于集群中缺少Etcd和Control角色,所以集群提示:Waiting for etcd and controlplane nodes to be registered
接下来,编辑集群,并且设置相同的节点参数,这地方要注意,一定要设置和之前添加节点时相同的节点参数。
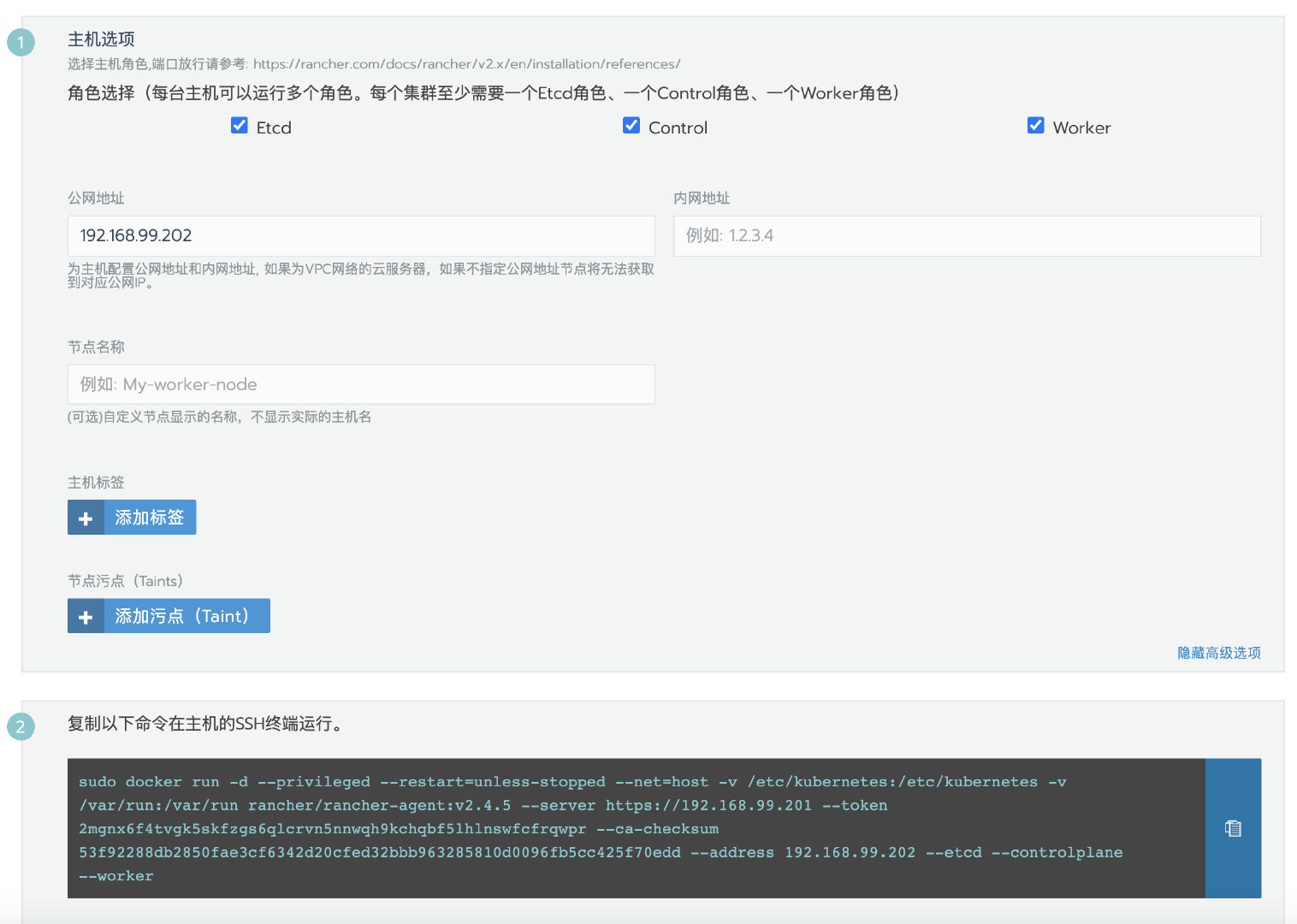
复制添加节点命令在rancher2的SSH终端运行。

过一会,再回到集群集群主机列表页面,可以看到rancher2节点已经恢复
如何恢复执行过清理节点脚本的节点
中文官网提供了一个清理节点的脚本,这个脚本会清理节点上的容器、卷、rancher/kubernetes目录、网络、进程、iptables等。
如果由于误操作,在正确的节点上执行了清理脚本。针对这种场景,只有在rancher中创建过备份的集群才可以恢复。
创建集群备份参考中文官网:
https://rancher2.docs.rancher.cn/docs/cluster-admin/backing-up-etcd/_index
在我的环境中,demo集群有rancher2和rancher3两个节点。
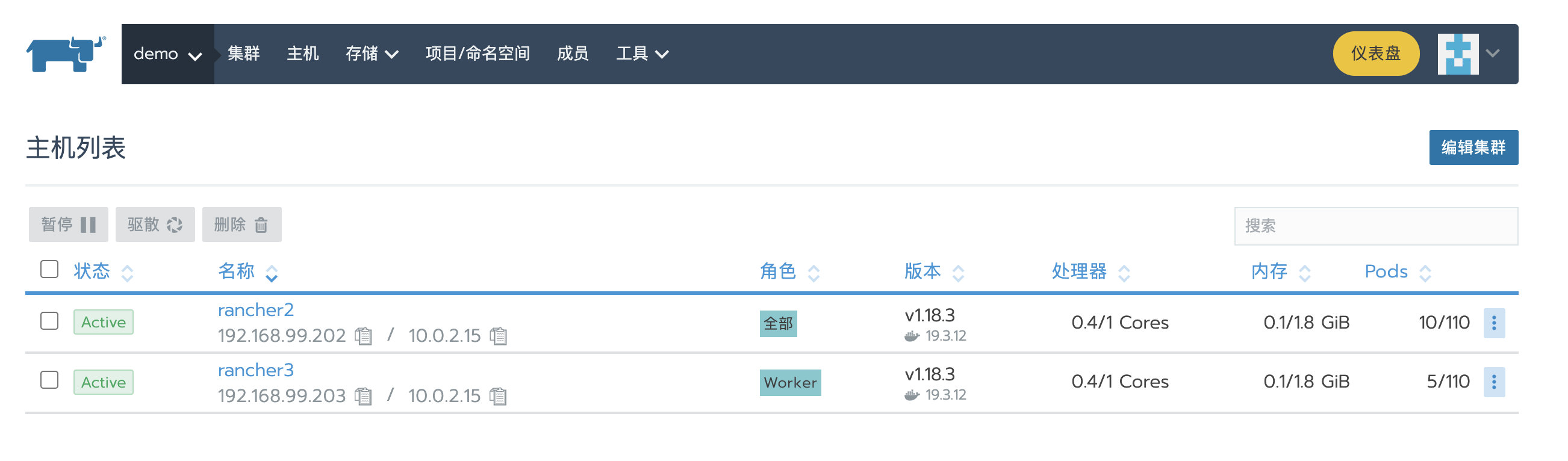
创建备份
在Rancher UI上创建集群快照,稍后恢复集群的时候会用的到。
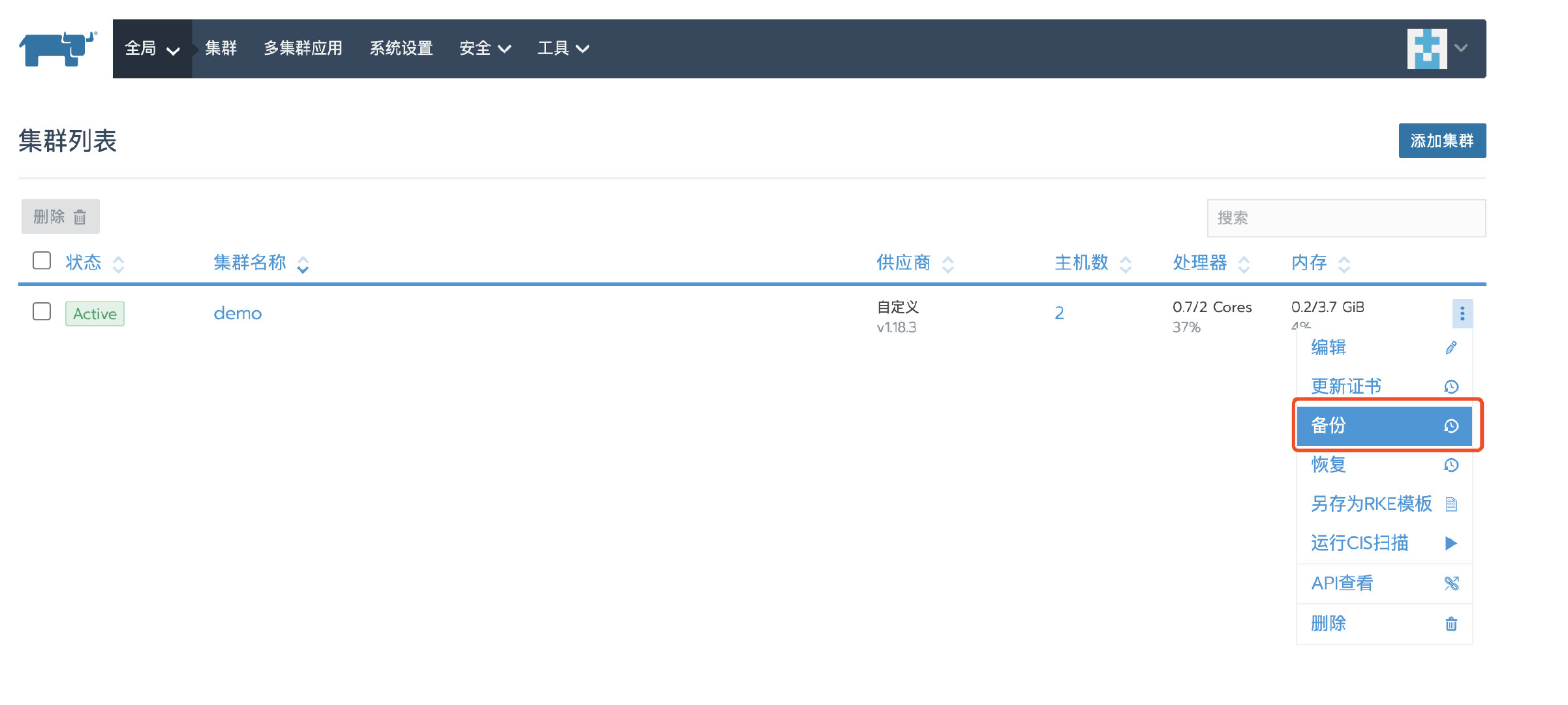
然后导航到全局->demo->工具->备份查看已经创建的ETCD备份,从备份创建时间可以看出,刚才创建的备份名称为c-v6mtr-ml-klt5n。
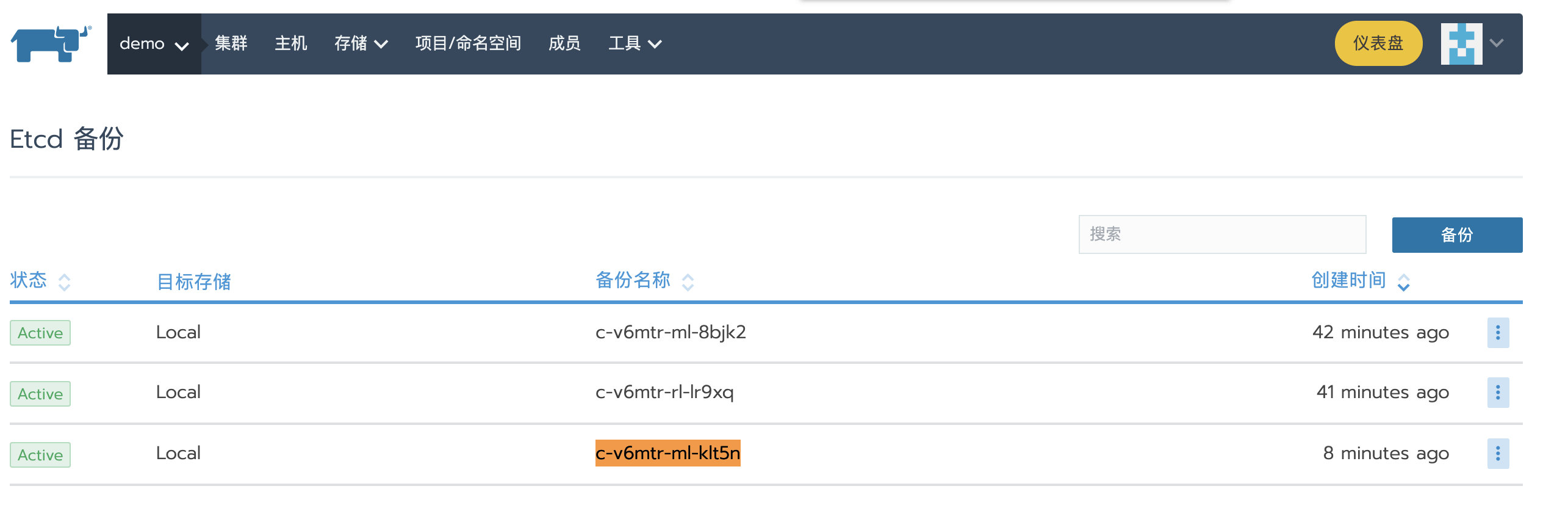
备份文件存到了etcd(rancher2)节点对应的/opt/rke/etcd-snapshots目录下。

清理节点
在rancher2节点执行中文官网节点清理脚本,清理理完之后,不出所料,集群崩了。
恢复集群
节点清理脚本并不会将/opt/rke目录删除,只是使用mv /opt/rke /opt/rke-bak-$(date +"%Y%m%d%H%M")做了个备份。接下来可以将快照备份恢复到默认的/opt/rke目录下。
mv /opt/rke-bak-202007060903 /opt/rke
接下来,编辑集群重新添加节点。这地方要注意,一定要设置和之前添加节点时相同的节点参数。
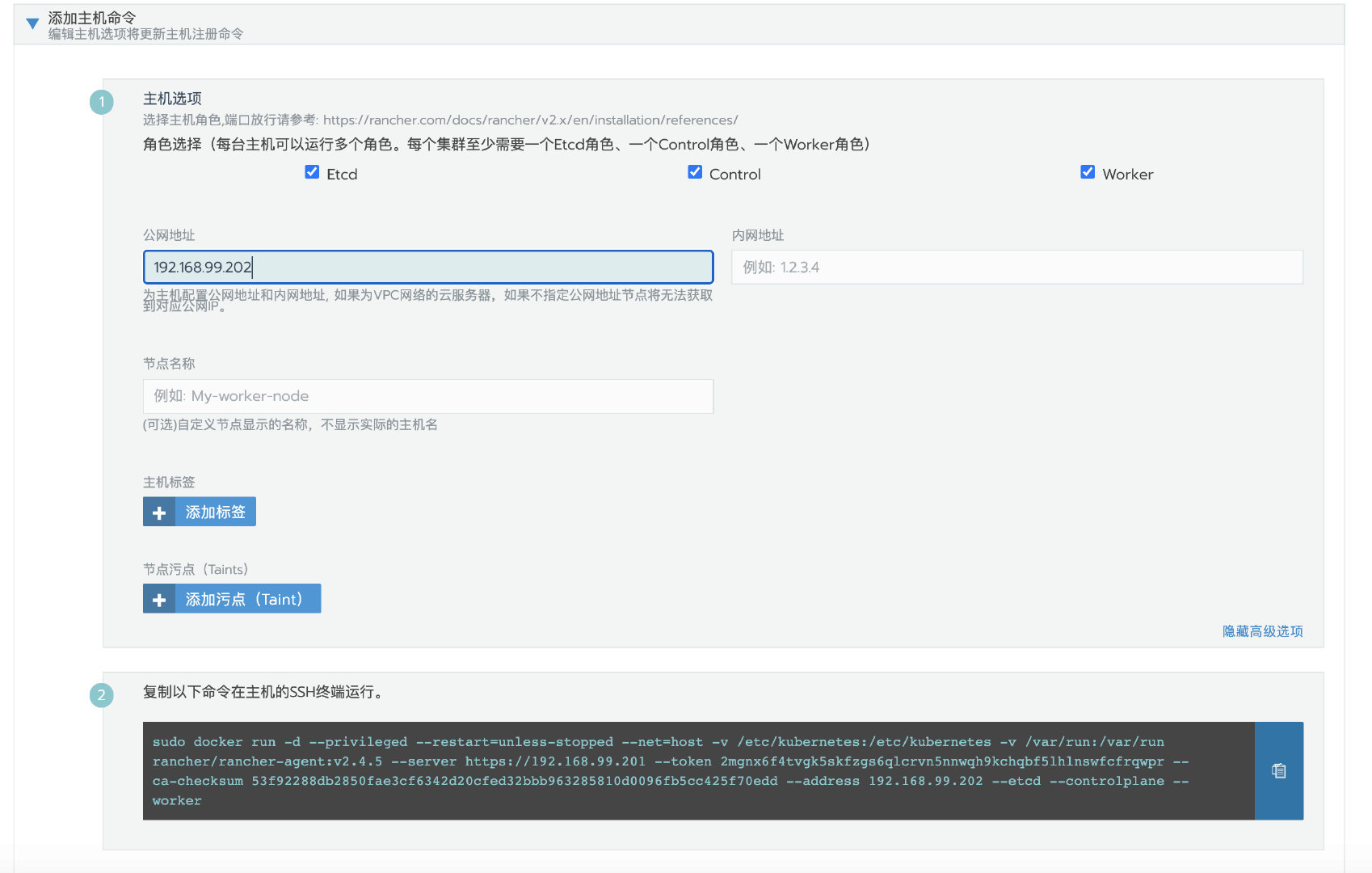
运⾏完命令之后,可以看到rancher agent已经正常工作起来了。

接下来,选择之前的备份记录,保存,开始恢复集群。
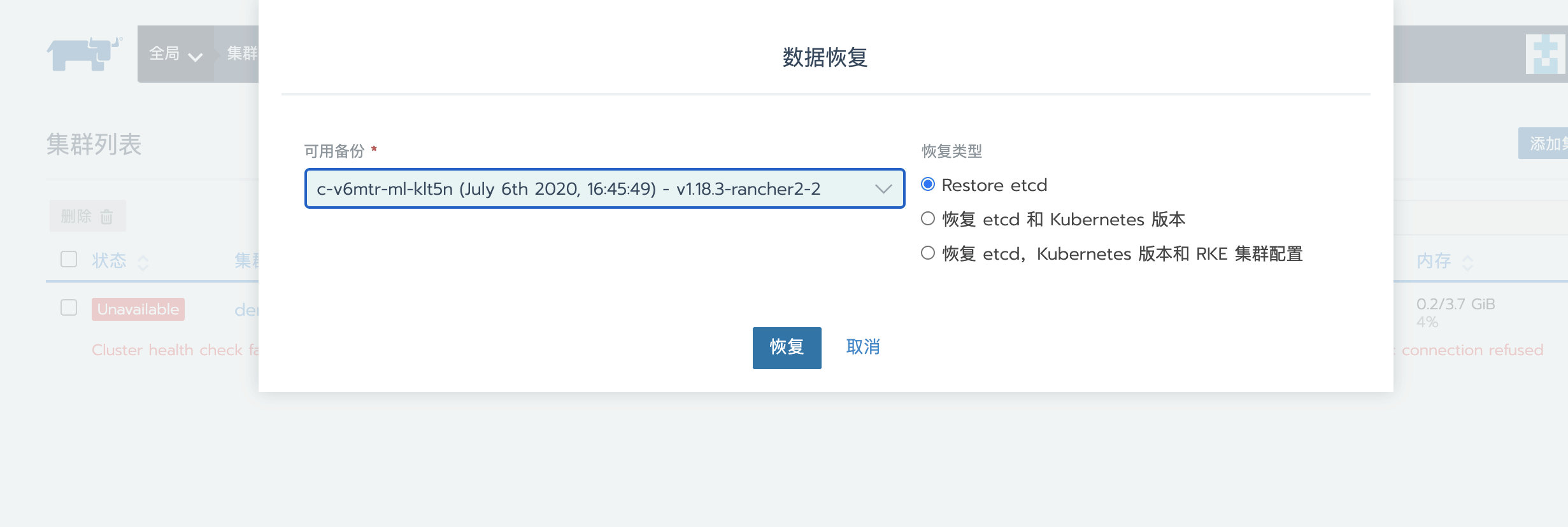
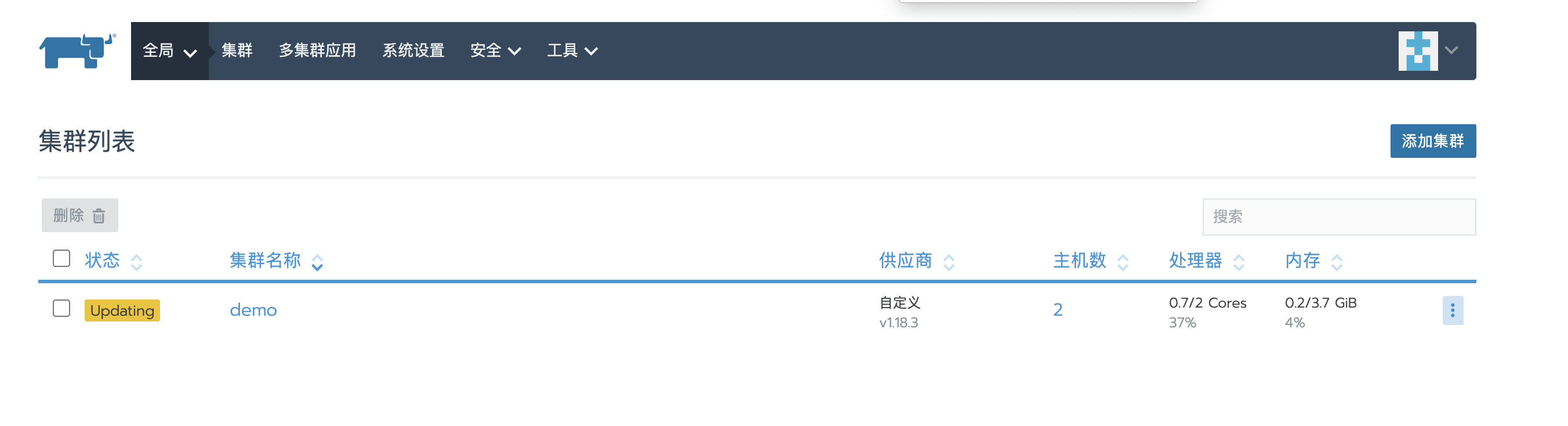
现在集群的状态变成了Updating,已经开始使用之前创建的快照进行恢复集群了
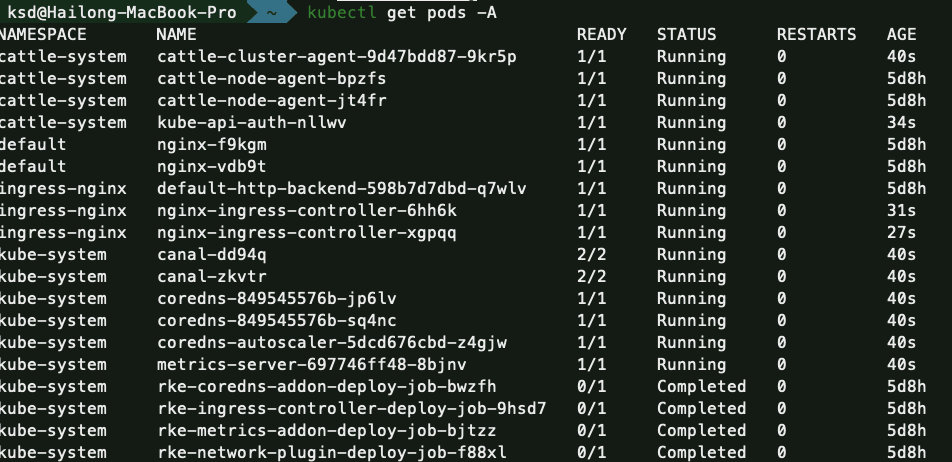
稍等片刻,可以看到kubernetes组件全部运行起来。
集群状态也变为了Active,此时,集群已经成功恢复
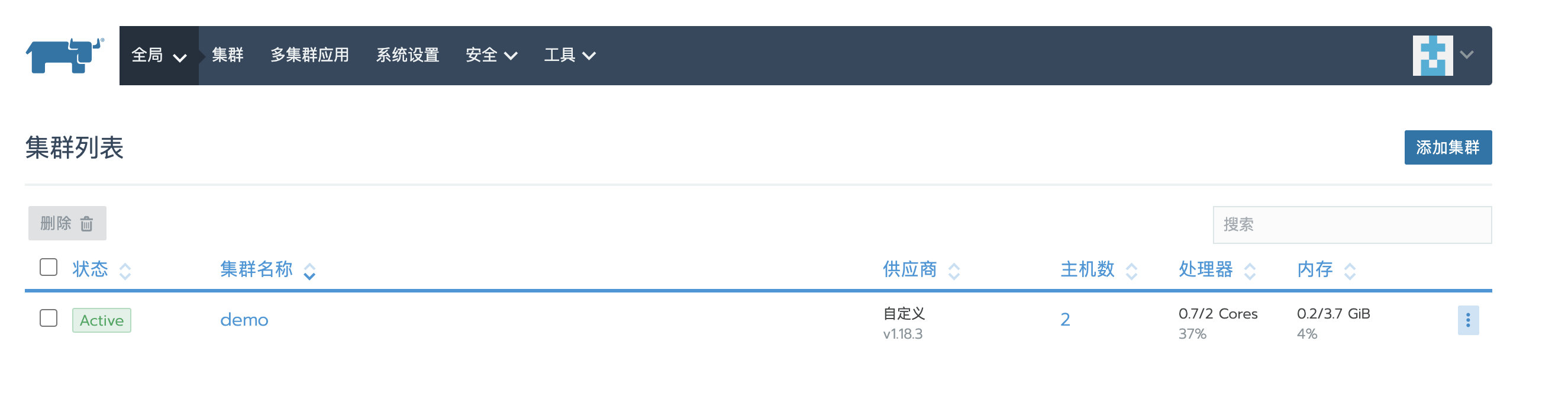
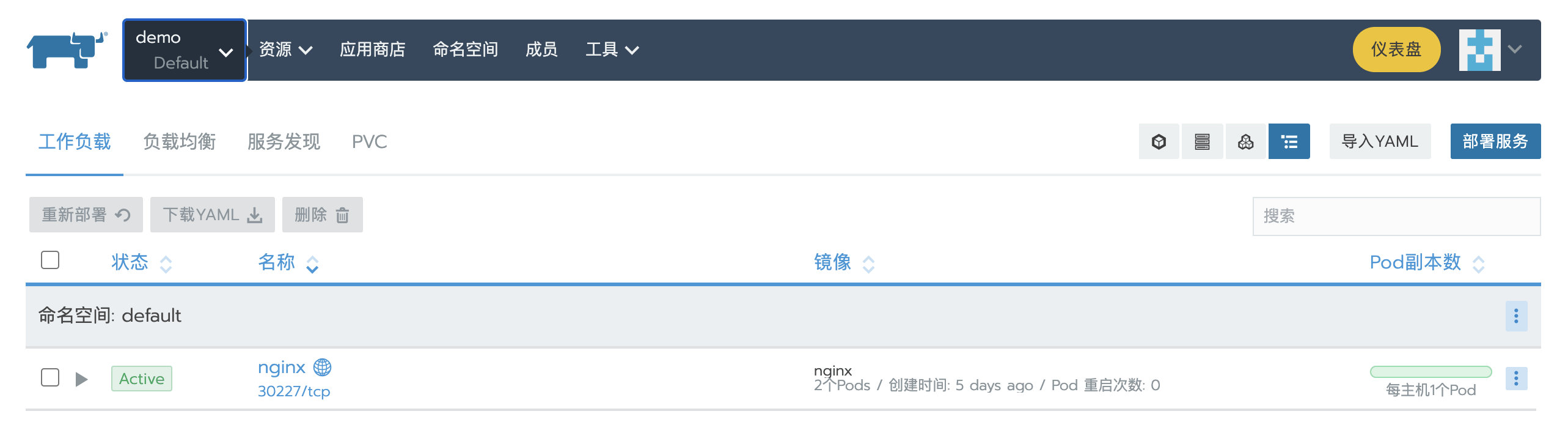
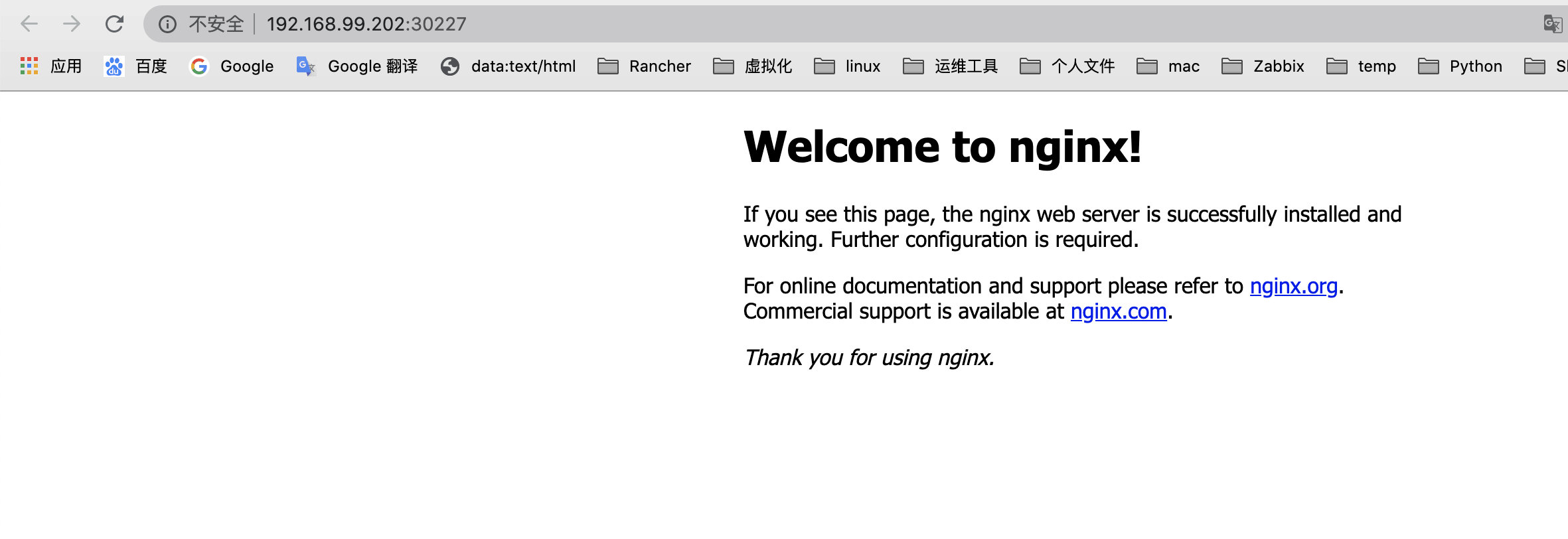
业务应用检查
之前部署的名为nginx的nginx应⽤依旧存在,且运行正常。
如何恢复被删除的custom集群
在Rancher UI中误删自定义的集群,如果要恢复该集群,必须需要有Rancher local集群和自定义集群的备份才可以恢复。
备份集群
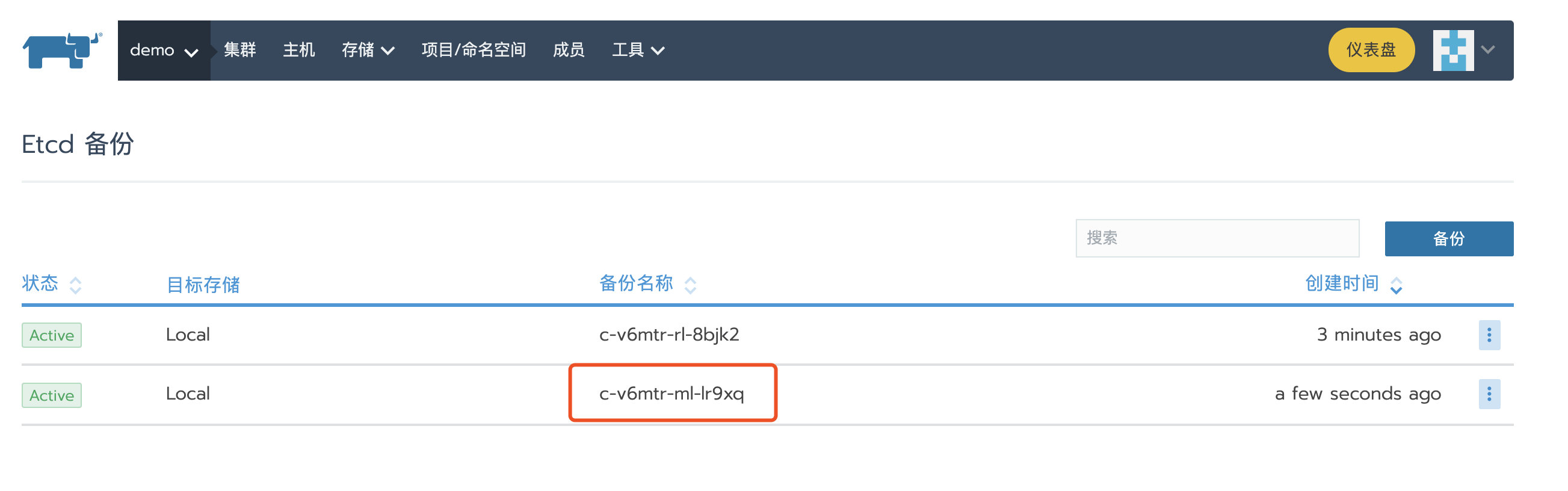
备份custom集群
参考 https://rancher2.docs.rancher.cn/docs/cluster-admin/backing-up-etcd/_index 备份custom集群,备份成功后,可以导航到集群->工具->备份查看备份。
备份local集群
参考 https://rancher2.docs.rancher.cn/docs/backups/_index 备份local集群,备份成功后,将在本地生成一个tar.gz文件。

模拟故障
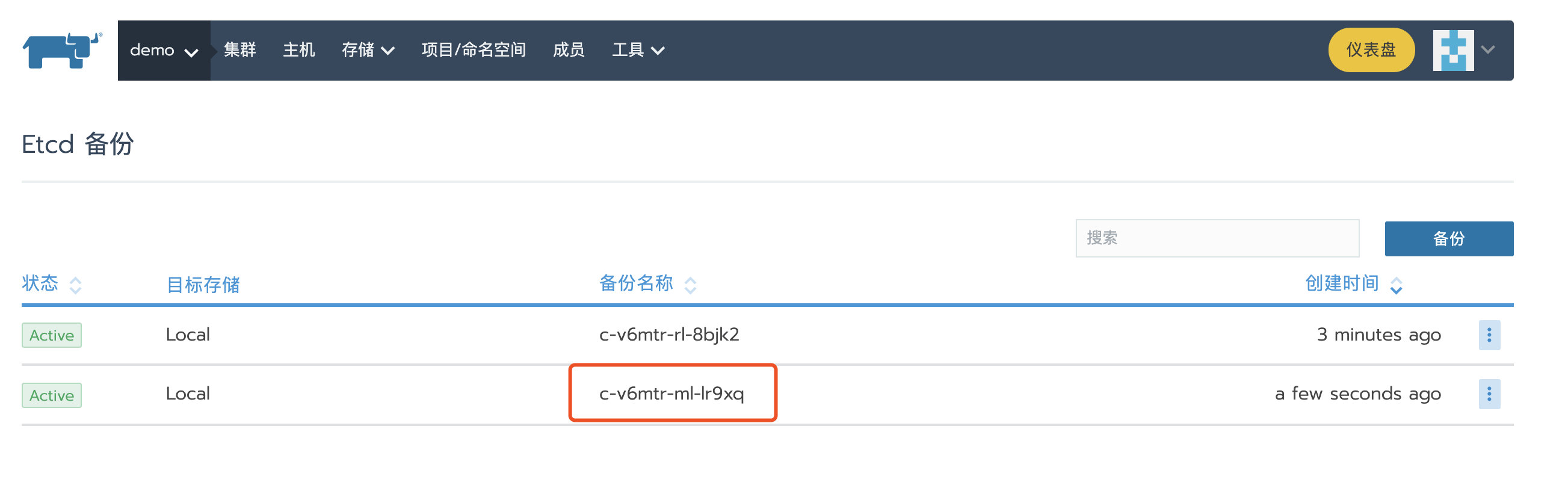
备份custom集群
参考 https://rancher2.docs.rancher.cn/docs/cluster-admin/backing-up-etcd/_index 备份custom集群,备份成功后,可以导航到集群->工具->备份查看备份。
备份local集群
备份local集群可参考:
https://rancher2.docs.rancher.cn/docs/backups/_index
备份成功后,将在本地生成一个tar.gz文件。

模拟故障
接下来可以在Rancher UI上将集群删除来模拟故障。
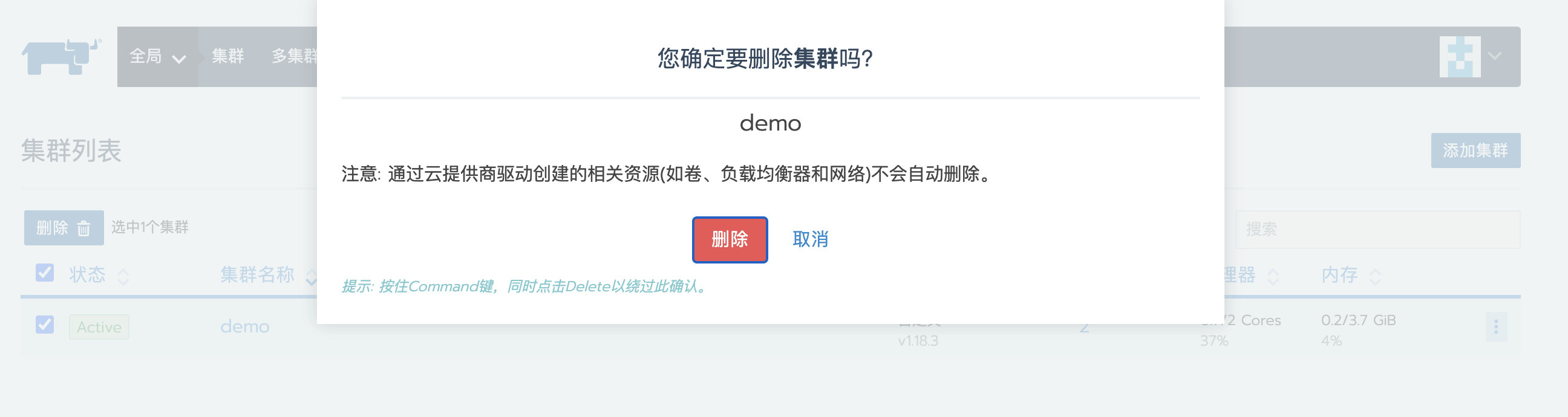
恢复local集群
恢复local集群,可参考:
https://rancher2.docs.rancher.cn/docs/backups/restorations/_index
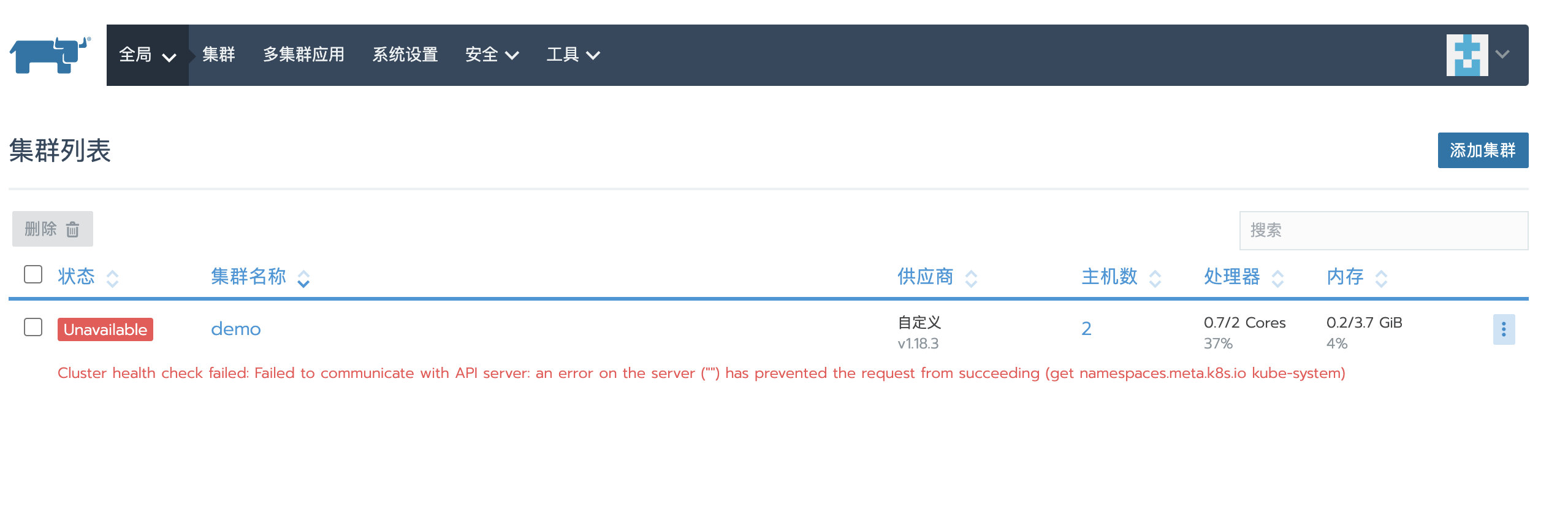
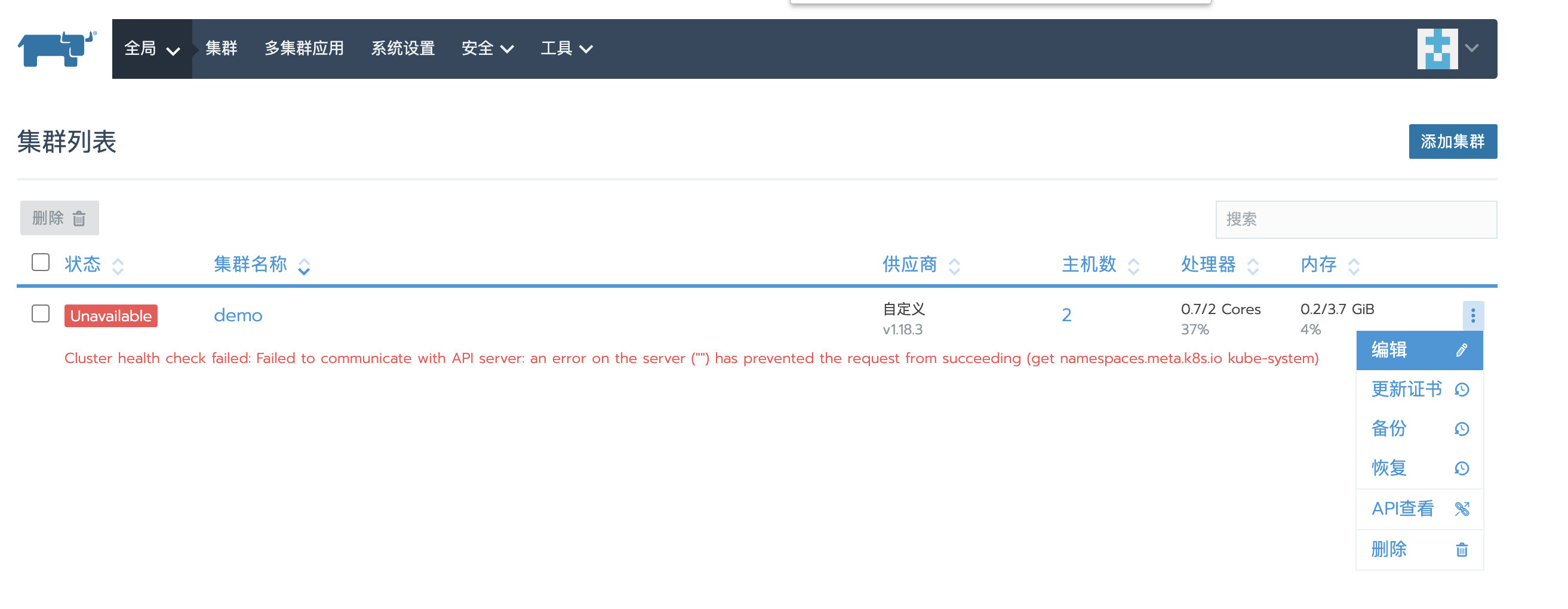
local恢复成功后,重新登录Rancher UI,可以看到刚才被删除的custom集群又重新显示了,但状态是Unavailable
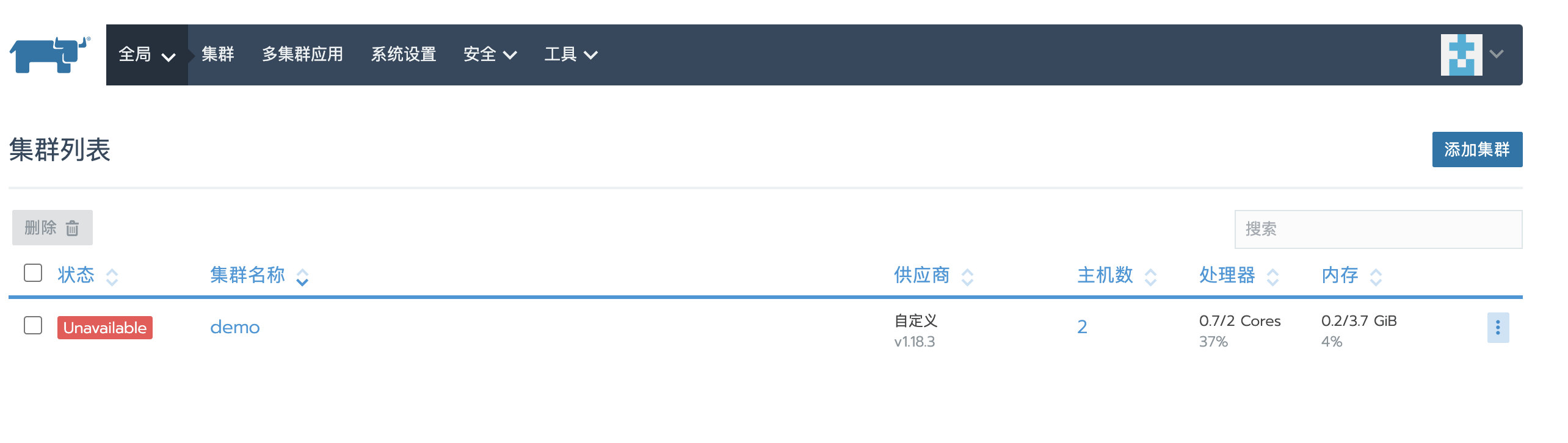
恢复custom集群
接下来,可以根据之前创建的custom集群快照恢复custom集群。
恢复custom集群参考:
https://rancher2.docs.rancher.cn/docs/cluster-admin/restoring-etcd/_index
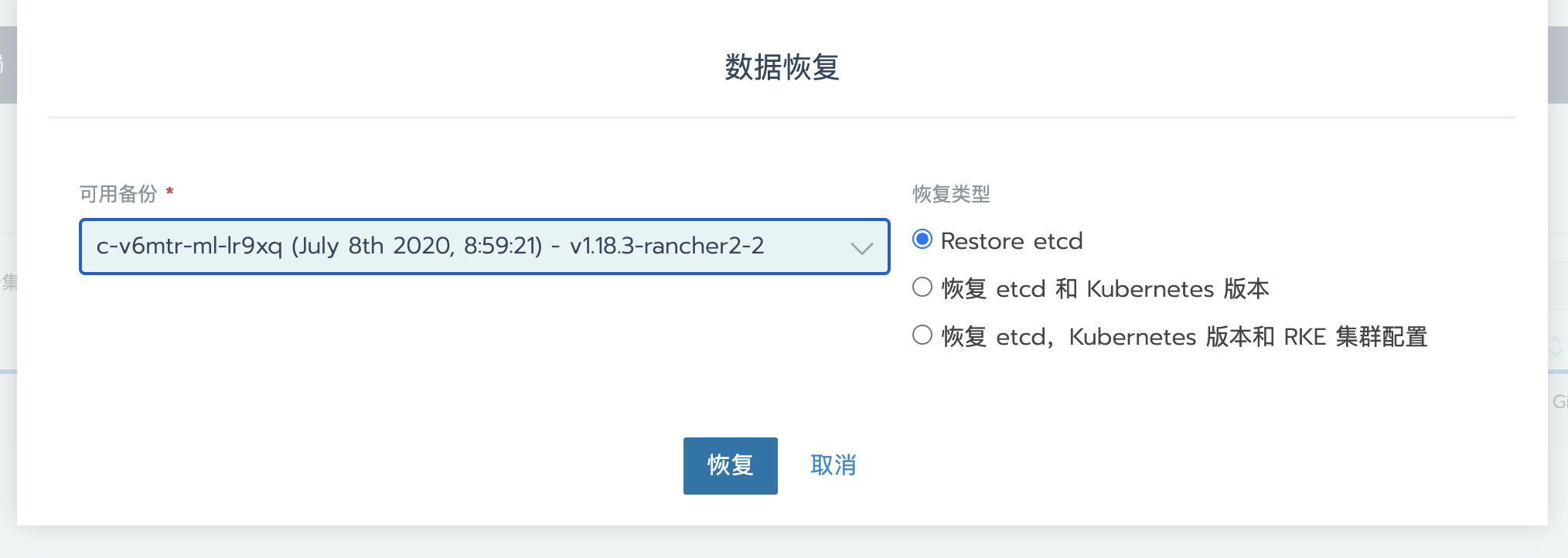
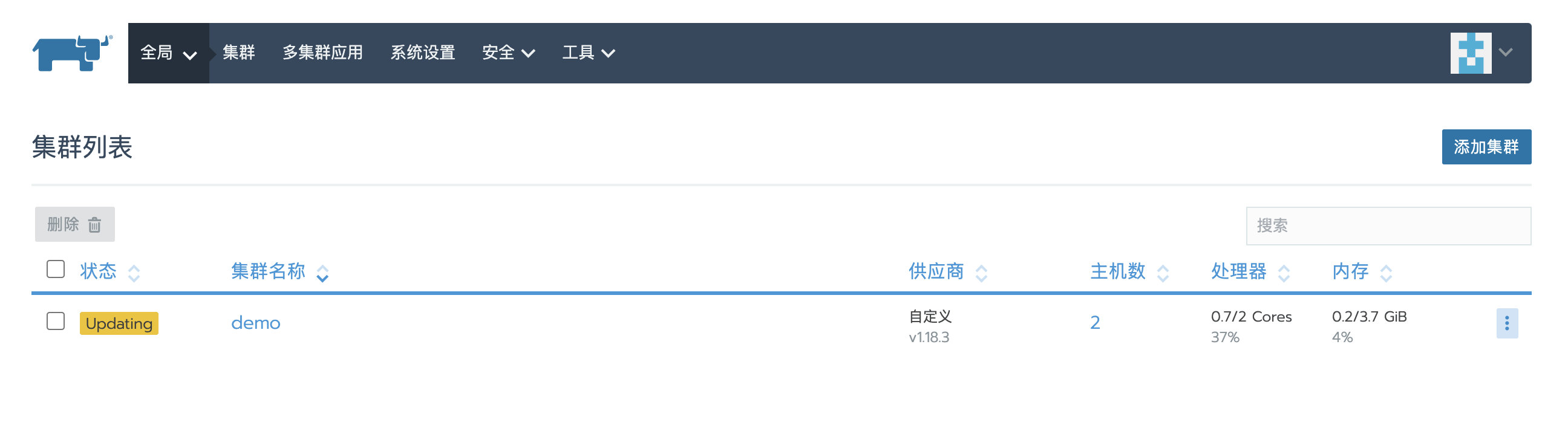
恢复后,集群状态变为Updating,稍等片刻,可以看到集群状态又变为Active,集群恢复成功。
总 结
从以上几个场景的恢复操作可以看出,大部分的恢复方案都依赖于集群的备份,所以大家在生产环境中一定要做好定时备份,并且最好将备份文件上传到远端备份服务器,这样可以在灾难情况下保护您的数据。