最近有套系统数据库周末总是告警,CPU使用率超过90%,开始由开发那边再跟进处理,我也就没参与,后来发现没进展就登录上去看了下,然后进行了部分优化,优化后效果还是比较明显的,具体优化过程本文会做详细的阐述。
一、现象描述
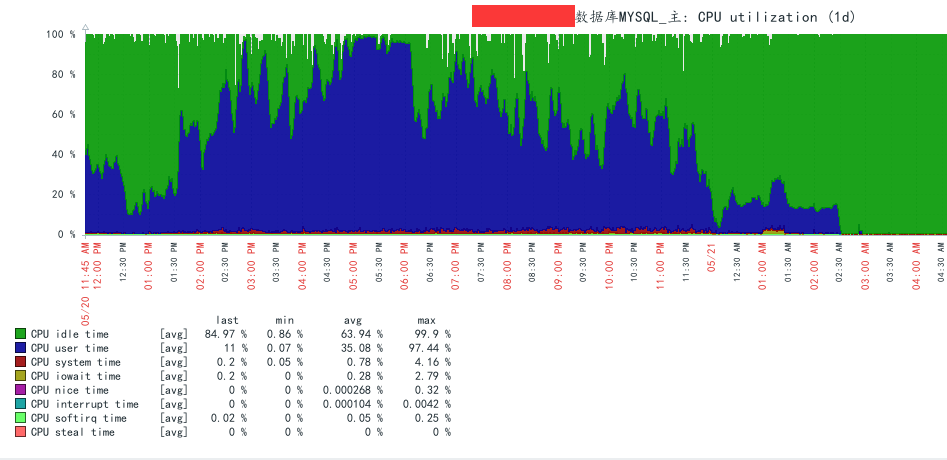
数据库服务器CPU使用率超过90%,而此数据库架构为mycat对应的一主三从(之前一主二从,由于CPU使用率高,开发那边对库做了扩展,从负载均衡的角度降低CPU压力,从效果上看没达到应有的效果),其中mycat的负载策略是3,即所有读操作分配到从库上完成,但实际是主库抓包发现也会有大量的查询操作。

zabbix监控数据:
二、问题原因
1、mycat读写分离,读操作为何会分发到主库
经过tcpdump抓包和general_log抓包分析,确实存在着大量的select操作,开始我以为是mycat的读写负载的配置有问题(设置了读写负载2,导致所有数据库均分发select),后来检查发现mycat配置的是1,后改成3,现象依旧。这里我就想到了是否调用存储过程、事务的开启和关闭,经过测试和跟踪发现,确实在事务手动开启和关闭的情况下,select查询操作会分发到主库。这种原因是mysql默认开始autocommit=1,也就是默认自动提交,而一旦程序通过set autocommit=0;update ..../select ..../select ...;commit;set autocommit=1;类似这种操作,那么这些事务会分发到主库,导致主库有了大量的select查询。
2、cpu负载之所以高,是由于大量的select操作导致的
在并发量大的情况下,大量的sql操作会导致cpu资源消耗严重,尤其是在sql执行较慢的情况下,所以我们首先要做的就是对负载较高的时间段,抓取相关的SQL进行分析,针对mysql我们当然要分析的就是慢日志。
三、处理过程
根据监控发现CPU负载在周一到周日,周末的负载尤其严重,和开发沟通后得知此系统主要面对的群体是一些周末上班的同事,这里就对负载较高的14点到22点做慢日志分析,发现居然慢日志很少,这种情况是不正常的。
慢日志分析:pt-query-digest --since='2018-05-20 14:00:00' --until='2018-05-20 22:00:00' slow.log >slow.txt
备注:mysql5.7的慢日志时间格式默认是utc时间(比我们慢8小时,可通过下面的参数调整)
SHOW GLOBAL VARIABLES LIKE 'log_timestamps'; set global log_timestamps=SYSTEM;
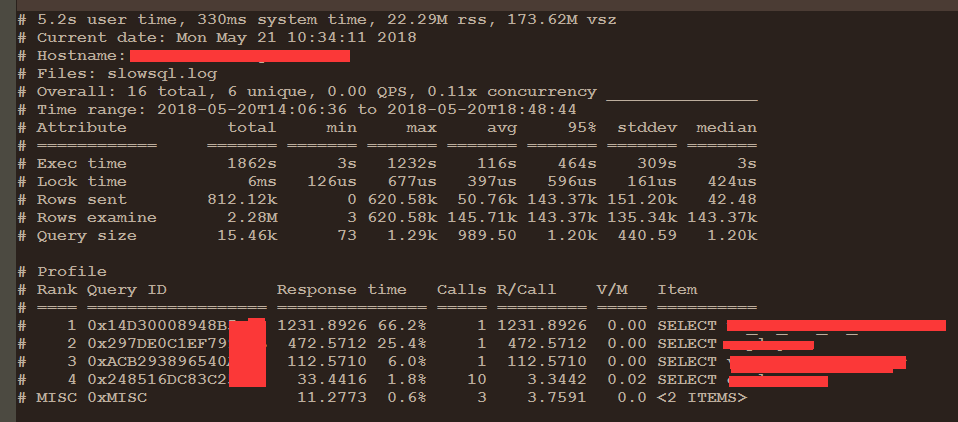
经过分析,这些慢日志不是导致CPU负载高的主要原因,那么为什么这个时间段慢日志这么少,又导致CPU负载这么严重呢?去查看mysql参数发现,慢日志设置的是3秒,这里动态调整为1秒后,一段时间后,抓取到很多相关的慢SQL,具体慢日志分析和优化我这里就不说了,无非是索引优化,SQL改写什么的。
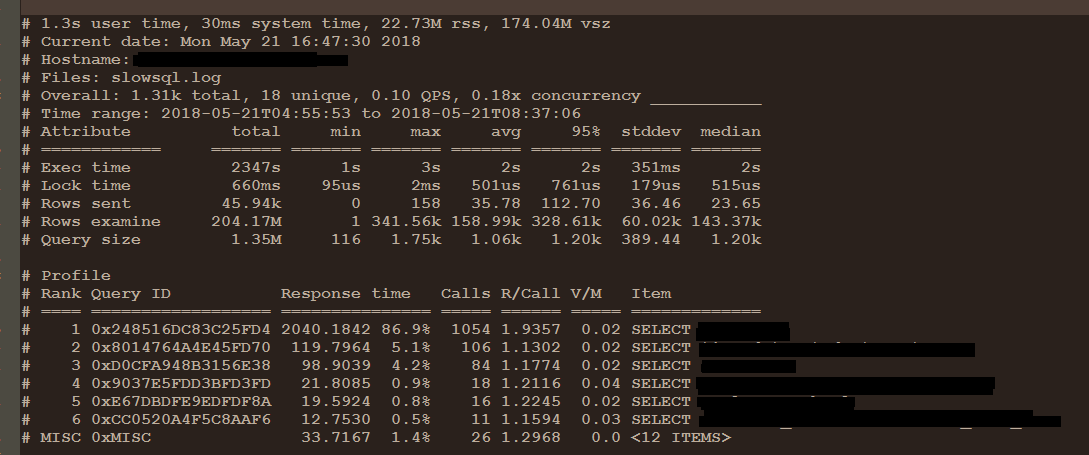
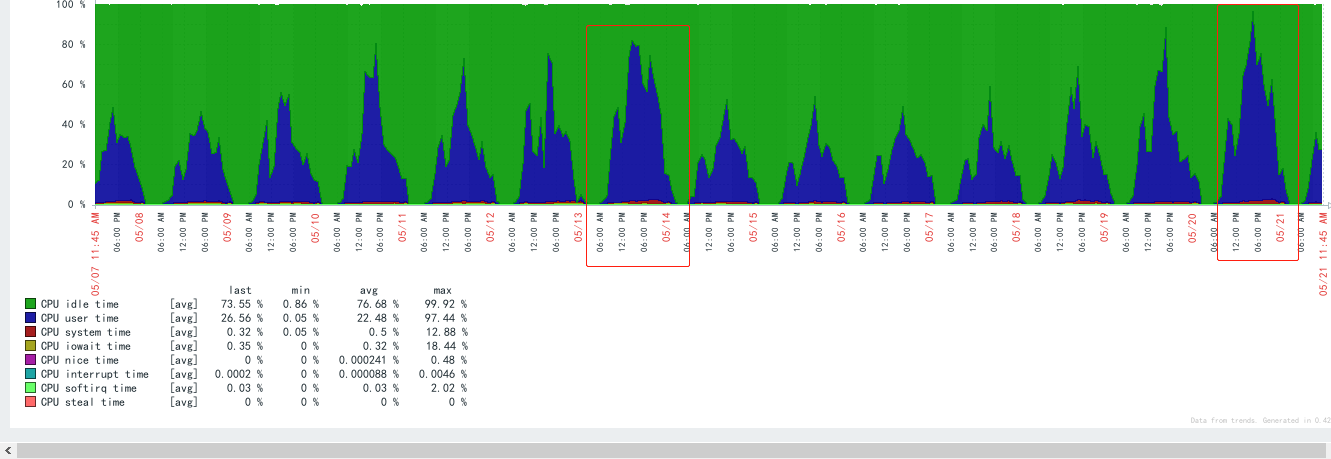
优化后效果如下:(5.21日18:30做的优化)
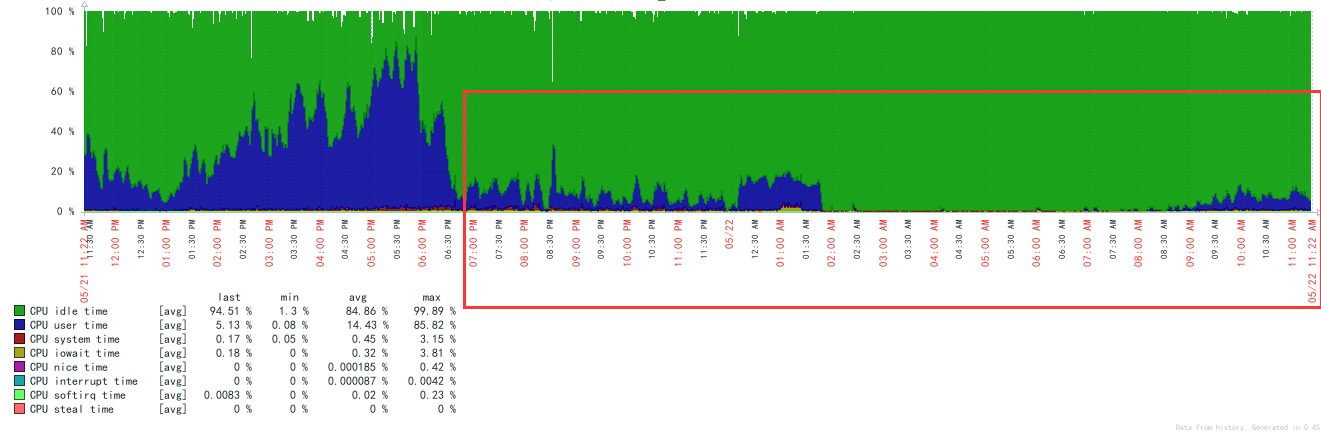
至此CPU负载基本稳定,优化告一段落,需进一步监控。
20180522一天运行数据如下:
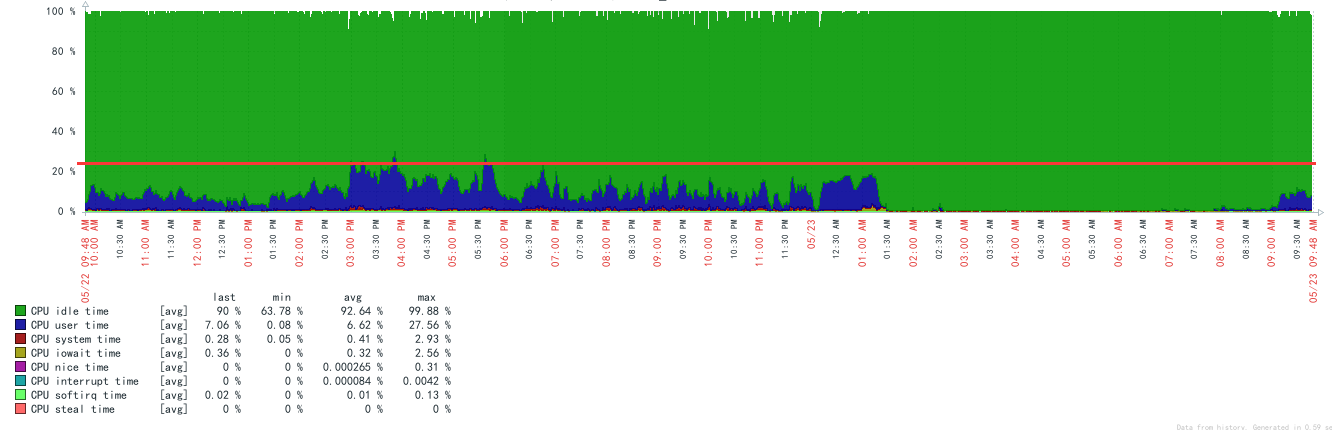
优化后几天的观察效果如下:

四、TCPDUMP抓包脚本
tcpdump参数:
-a 将网络地址和广播地址转变成名字; -d 将匹配信息包的代码以人们能够理解的汇编格式给出; -dd 将匹配信息包的代码以c语言程序段的格式给出; -ddd 将匹配信息包的代码以十进制的形式给出; -e 在输出行打印出数据链路层的头部信息,包括源mac和目的mac,以及网络层的协议; -f 将外部的Internet地址以数字的形式打印出来; -l 使标准输出变为缓冲行形式; -n 指定将每个监听到数据包中的域名转换成IP地址后显示,不把网络地址转换成名字; -nn: 指定将每个监听到的数据包中的域名转换成IP、端口从应用名称转换成端口号后显示 -t 在输出的每一行不打印时间戳; -v 输出一个稍微详细的信息,例如在ip包中可以包括ttl和服务类型的信息; -vv 输出详细的报文信息; -c 在收到指定的包的数目后,tcpdump就会停止; -F 从指定的文件中读取表达式,忽略其它的表达式; -i 指定监听的网络接口; -p: 将网卡设置为非混杂模式,不能与host或broadcast一起使用 -r 从指定的文件中读取包(这些包一般通过-w选项产生); -w 直接将包写入文件中,并不分析和打印出来; -s snaplen snaplen表示从一个包中截取的字节数。0表示包不截断,抓完整的数据包。默认的话 tcpdump 只显示部分数据包,默认68字节。 -T 将监听到的包直接解释为指定的类型的报文,常见的类型有rpc (远程过程调用)和snmp(简单网络管理协议;) -X 告诉tcpdump命令,需要把协议头和包内容都原原本本的显示出来(tcpdump会以16进制和ASCII的形式显示),这在进行协议分析时是绝对的利器。
-G 写入输出报告时间间隔,单位秒
src host ipaddr 源地址
dst host ipaddr 目标地址
tcpdump抓包脚本
#!/bin/bash date +"%Y-%m-%d %H:%M:%I" tcpdump -i eth1 -s0 -G600 -l -w - dst port 3306 | strings | perl -e ' while(<>) { chomp; next if /^[^ ]+[ ]*$/; if(/^(SELECT|UPDATE|DELETE|INSERT|SET|COMMIT|ROLLBACK|CREATE|DROP|ALTER|CALL)/i) { if (defined $q) { print "$q "; } $q=$_; } else { $_ =~ s/^[ ]+//; $q.=" $_"; } }' date +"%Y-%m-%d %H:%M:%I"
五、MYSQL执行顺序
执行顺序:from... where...group by... having.... select ... order by...