




-
MLP实现


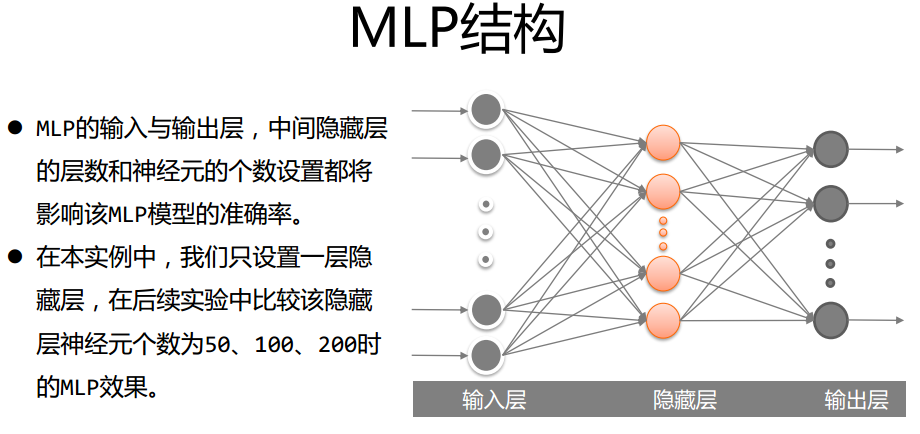

- 调整参数比较性能结果
# -*- coding: utf-8 -*- """ Created on Wed Aug 30 21:14:38 2017 @author: Administrator """ import numpy as np #导入numpy工具包 from os import listdir #使用listdir模块,用于访问本地文件 from sklearn.neural_network import MLPClassifier ## 版本选择sklearn-v0.18;sklearn更新anaconda方法:conda update scikit-learn #定义img2vector函数,将加载的32*32的图片矩阵展开成一列向量 def img2vector(fileName): retMat = np.zeros([1024],int) #定义返回的矩阵,大小为1*1024 fr = open(fileName) #打开包含32*32大小的数字文件 lines = fr.readlines() #读取文件的所有行 for i in range(32): #遍历文件所有行 for j in range(32): #并将01数字存放在retMat中 retMat[i*32+j] = lines[i][j] return retMat #定义加载训练数据的函数readDataSet,并将样本标签转化为one-hot向量 def readDataSet(path): fileList = listdir(path) #获取文件夹下的所有文件 numFiles = len(fileList) #统计需要读取的文件的数目 dataSet = np.zeros([numFiles,1024],int) #用于存放所有的数字文件 hwLabels = np.zeros([numFiles,10]) #用于存放对应的one-hot标签 for i in range(numFiles): #遍历所有的文件 filePath = fileList[i] #获取文件名称/路径 digit = int(filePath.split('_')[0]) #通过文件名获取标签 hwLabels[i][digit] = 1.0 #将对应的one-hot标签置1 dataSet[i] = img2vector(path +'/'+filePath) #读取文件内容 return dataSet,hwLabels #read dataSet fpath='F:RANJIEWENMachineLearningPython机器学习实战_moocdata手写数字digits\' train_dataSet, train_hwLabels = readDataSet(fpath+'trainingDigits') # 调整参数,隐藏层数量,学习率,最大迭代次数比较性能结果 clf = MLPClassifier(hidden_layer_sizes=(100,), activation='logistic', solver='adam', learning_rate_init = 0.00001, max_iter=2000) print(clf) clf.fit(train_dataSet,train_hwLabels) #read testing dataSet dataSet,hwLabels = readDataSet(fpath+'testDigits') res = clf.predict(dataSet) #对测试集进行预测 error_num = 0 #统计预测错误的数目 num = len(dataSet) #测试集的数目 for i in range(num): #遍历预测结果 #比较长度为10的数组,返回包含01的数组,0为不同,1为相同 #若预测结果与真实结果相同,则10个数字全为1,否则不全为1 if np.sum(res[i] == hwLabels[i]) < 10: error_num += 1 print("Total num:",num," Wrong num:", error_num," WrongRate:",error_num / float(num))
- kNN比较
# -*- coding: utf-8 -*- """ Created on Thu Aug 31 10:11:15 2017 @author: Administrator knn-neighbors """ import numpy as np #导入numpy工具包 from os import listdir #使用listdir模块,用于访问本地文件 from sklearn import neighbors #定义img2vector函数,将加载的32*32的图片矩阵展开成一列向量 def img2vector(fileName): retMat = np.zeros([1024],int) #定义返回的矩阵,大小为1*1024 fr = open(fileName) #打开包含32*32大小的数字文件 lines = fr.readlines() #读取文件的所有行 for i in range(32): #遍历文件所有行 for j in range(32): #并将01数字存放在retMat中 retMat[i*32+j] = lines[i][j] return retMat #定义加载训练数据的函数readDataSet,并将样本标签转化为one-hot向量 def readDataSet(path): fileList = listdir(path) #获取文件夹下的所有文件 numFiles = len(fileList) #统计需要读取的文件的数目 dataSet = np.zeros([numFiles,1024],int) #用于存放所有的数字文件 hwLabels = np.zeros([numFiles])#用于存放对应的标签(与神经网络的不同) for i in range(numFiles): #遍历所有的文件 filePath = fileList[i] #获取文件名称/路径 digit = int(filePath.split('_')[0]) #通过文件名获取标签 hwLabels[i] = digit #直接存放数字,并非one-hot向量 dataSet[i] = img2vector(path +'/'+filePath) #读取文件内容 return dataSet,hwLabels #read dataSet fpath='F:RANJIEWENMachineLearningPython机器学习实战_moocdata手写数字digits\' train_dataSet, train_hwLabels = readDataSet(fpath+'trainingDigits') knn = neighbors.KNeighborsClassifier(algorithm='kd_tree', n_neighbors=3) knn.fit(train_dataSet, train_hwLabels) #read testing dataSet dataSet,hwLabels = readDataSet(fpath+'testDigits') res = knn.predict(dataSet) #对测试集进行预测 error_num = np.sum(res != hwLabels) #统计分类错误的数目 num = len(dataSet) #测试集的数目 print("Total num:",num," Wrong num:", error_num," WrongRate:",error_num / float(num))