
1、Impala简介
• Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。
• 基于Hive使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点
• 是CDH平台首选的PB级大数据实时查询分析引擎
官网:http://www.cloudera.com/products/apache-hadoop/impala.html
http://www.impala.io/index.html
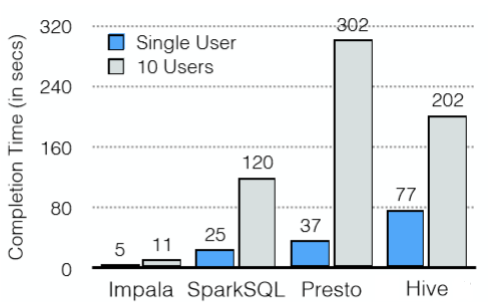
下面是在基于单用户和多用户查询的时候,不同的查询分析器所使用的时间:
2、Impala的特点
• 1、基于内存进行计算,能够对PB级数据进行交互式实时查询、分析
• 2、无需转换为MR,直接读取HDFS数据
• 3、C++编写,LLVM统一编译运行
• 4、兼容HiveSQL
• 5、具有数据仓库的特性,可对hive数据直接做数据分析
• 6、支持Data Local
• 7、支持列式存储
• 8、支持JDBC/ODBC远程访问
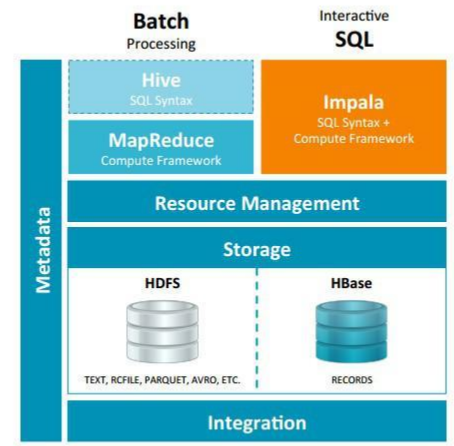 (相比于Hive,Impala不需要启动MapReduce直接同HDFS或HBase进行交互)
(相比于Hive,Impala不需要启动MapReduce直接同HDFS或HBase进行交互)
3、Impala 劣势
• 1、对内存依赖大
• 2、C++编写 开源?!
• 3、完全依赖于hive
• 4、实践过程中 分区超过1w 性能严重下下降
• 5、稳定性不如hive
4、Impala安装
• 安装方式:
– 1、ClouderaManager
– 2、手动安装(待续)
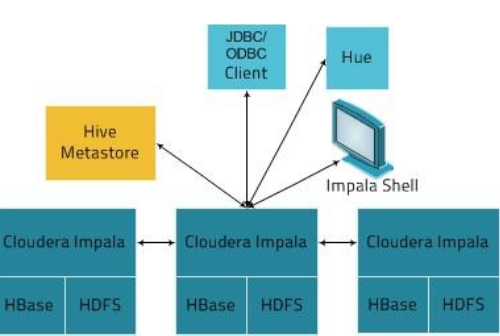
可以使用CDH安装,方便快捷,而且管理起来更加方便,下面是CDH安装以后的CDH管理界面:
5、Impala核心组件
• Statestore Daemon
• 实例*1 - statestored
– 负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息.
– 负责query的调度
• Catalog Daemon
• 实例*1 - catalogd
– 分发表的元数据信息到各个impalad中
– 接收来自statestore的所有请求
• Impala Daemon
• 实例*N – impalad
– 接收client、hue、jdbc或者odbc请求、Query执行并返回给中心协调节点
– 子节点上的守护进程,负责向statestore保持通信,汇报工作
6、Impala架构
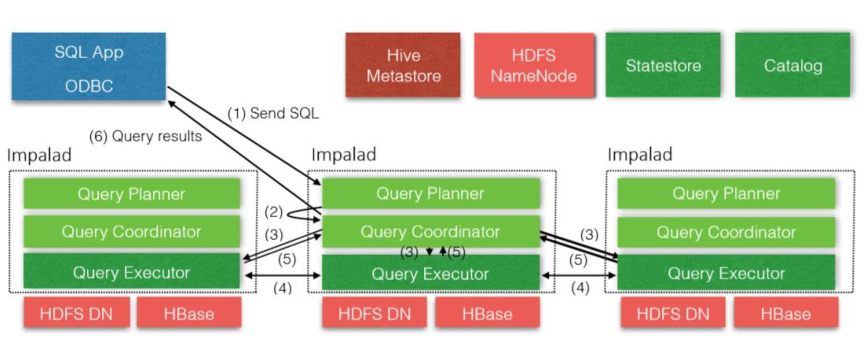
(1) 由Client发送一个执行SQL到任意一台Impalad的Query Planner
(2) 由Query Planner 把SQL发向Query Coordinator
(3) 由Query Coordinator 来调度分配任务到Impalad的所有节点
(4) 各个Impalad节点的Query Executor 进行执行SQL工作
(5) 执行SQL结束以后,将结果返回给Query Coordinator
(6) 再由Query Coordinator 将结果返回给Client