Solr4.8.0源码分析(25)之SolrCloud的Split流程(一)
题记:昨天有位网友问我SolrCloud的split的机制是如何的,这个还真不知道,所以今天抽空去看了Split的原理,大致也了解split的原理了,所以也就有了这篇文章。本系列有两篇文章,第一篇为core split,第二篇为collection split。
1. 简介
这里首先需要介绍一个比较容易混淆的概念,其实Solr的HTTP API 和 SolrCloud的HTTP API是不一样,如果接受到的是Solr的HTTP API,比如"http://localhost:8983/solr/admin/cores?action=SPLIT&core=core0&targetCore=core1&targetCore=core2",该方法对应的是CoreAdminHandler 。而"http://localhost:8983/solr/admin/collections?action=SPLITSHARD&collection=core0&shard=shard1",该方法对应的是CollectionsHandler.所以发送不同的HTTP 命令效果是不一样的。两个命令的代码分支是在以下SolrDispatchFilter中形成的:
1 // Check for the core admin page 2 if( path.equals( cores.getAdminPath() ) ) { 3 handler = cores.getMultiCoreHandler(); 4 solrReq = SolrRequestParsers.DEFAULT.parse(null,path, req); 5 handleAdminRequest(req, response, handler, solrReq); 6 return; 7 } 8 boolean usingAliases = false; 9 List<String> collectionsList = null; 10 // Check for the core admin collections url 11 if( path.equals( "/admin/collections" ) ) { 12 handler = cores.getCollectionsHandler(); 13 solrReq = SolrRequestParsers.DEFAULT.parse(null,path, req); 14 handleAdminRequest(req, response, handler, solrReq); 15 return; 16 }
2. Core的Split
讲过了core api 和collection的api,那么我们开始来讲core的split。core的split命令在第一小节中已经讲到,如下所示:"cores?action=SPLIT&core=core0&targetCore=core1&targetCore=core2" ,以上命令的意思是将core0切分成core1和core2(core0还是继续保留并对外提供服务的)。除了上述命令,还有以下几个配置参数:
- path,path是指core0索引最后切分好后存放的路径,它支持多个,比如cores?action=SPLIT&core=core0&path=path1&path=path2。
- targetCore,就是将core0索引切分好后放入targetCore中(targetCore必须已经建立),它同样支持多个,请注意path和targetCore两个参数必须至少存在一个。
-
split.key, 根据该key进行切分,默认为unique_id.
- ranges, 哈希区间,默认按切分个数进行均分。
- 由此可见Core的Split api是较底层的借口,它可以实现将一个core分成任意数量的索引(或者core)。
接下来我们来了解下Core的Split的源码,流程图如下:
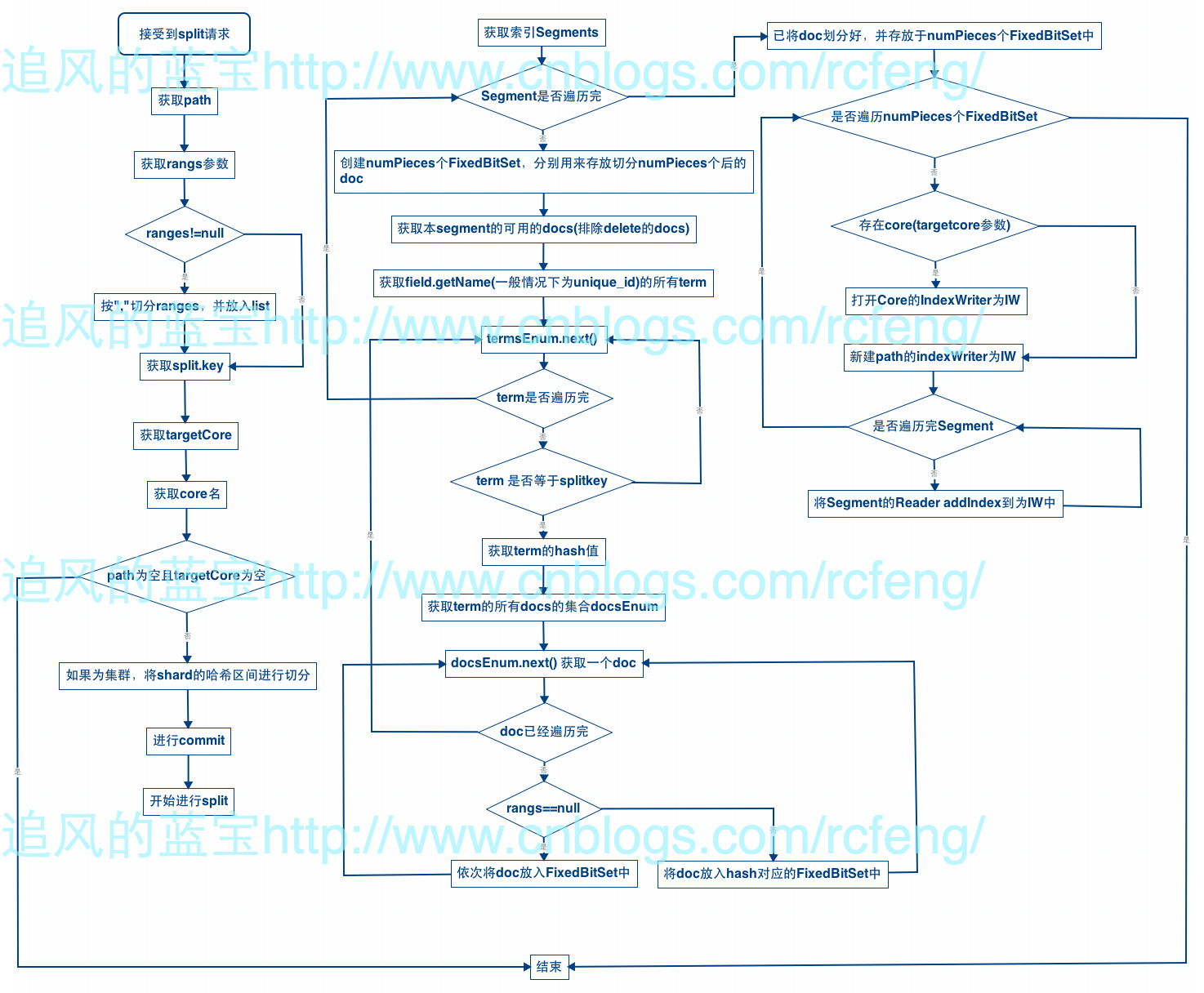
由于代码较多,这里就不贴出来了,可以查看SolrIndexSplitter.java和CoreAdminHandle.java,DirectUpdateHandle2.java对照着比较下,剩下的要补充几点:
1. Core Split是底层的实现接口,它在进行Split的时候不会去对原core的数据进行任何操作,所以即使过程中出现任何问题都不会影响原数据,且在split过程中原core一直在服务的。
2. Core Split可以实现一个core split为多个core,它即支持单机模式下的split也支持集群模式下对一个shard进行split,Collection的split底层就是调用该接口的。
3. 上图流程图中我分成了三列,分别对应三个步骤:
- 解析split请求(最左),主要是确立好hash区间。
- 对Segment中的docs进行切分(中间),切分好的数据是存放在FixedBitSet里面,FixedBitSet是Solr存放的doc id的集合,通过特定的格式进行存储,这在后文中将会具体介绍。
- 将切分好的数据addindex到新的core或者path下,addIndex本质上是进行merge。但是在进行addIndex时候需要注意,addindex传入多少个segment它就会将这些Segment合并成一个Segment,所以如果一下子传入大量的Segment,最后会合并成一个很大的segment,这过程中符合很大。而Split中是每一次传入一个Segment,这样的结果就是出现很多个较小的Segment。
- 最后Split是按新的core或者path依次来的,split完成之后并不会立马就可见,需要人为的进行一下reload操作。
总结:
本文介绍了Core Split的流程以及原理,为Collection Split的介绍做了个奠基。