实时日志分析:
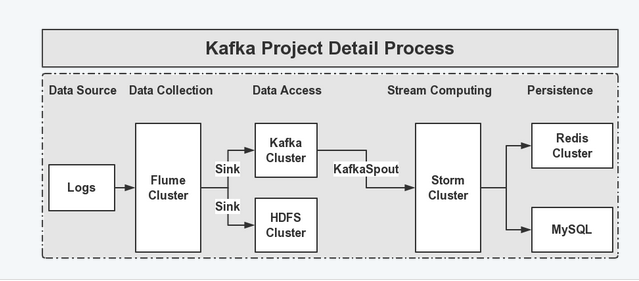
本篇文章主要测试 从flume到kafka的日志收集,storm日志分析,学习中!
flume 配置文件
#collector collector.sources=cs collector.sinks=ck hbaseSink collector.channels=cc hbaseChannel collector.sources.cs.type = exec collector.sources.cs.command = tail -F /data/hudonglogs/self/channel.log collector.sources.cs.channels=cc hbaseChannel collector.channels.cc.type = memory collector.channels.cc.capacity = 1000 collector.channels.cc.transactionCapacity = 100 collector.channels.hbaseChannel.type = memory collector.channels.hbaseChannel.capacity = 1000 collector.channels.hbaseChannel.transactionCapacity = 100 #sink kafka collector.sinks.ck.type = org.apache.flume.sink.kafka.KafkaSink collector.sinks.ck.topic = logs collector.sinks.ck.brokerList = localhost:9092 collector.sinks.ck.requiredAcks = 1 collector.sinks.ck.batchSize = 20 collector.sinks.ck.channel = cc #hbase sink collector.sinks.hbaseSink.type = asynchbase collector.sinks.hbaseSink.channel = hbaseChannel collector.sinks.hbaseSink.table = logs collector.sinks.hbaseSink.columnFamily = content collector.sinks.hbaseSink.batchSize = 5
注意: flume中每一个source可以有多个channel,但是一个sink只能对应一个channel。
kafka consumer
public class KafkaConsumer extends Thread { ConsumerConnector connector; private String topic; public KafkaConsumer(String topic) { this.topic = topic; this.connector = Consumer.createJavaConsumerConnector(createConsumerConfig()); } private ConsumerConfig createConsumerConfig() { Properties props = new Properties(); props.put("zookeeper.connect", KafkaConfig.zkConnect); props.put("group.id", KafkaConfig.groupId); props.put("zookeeper.session.timeout.ms", "40000"); props.put("zookeeper.sync.time.ms", "200"); props.put("auto.commit.interval.ms", "1000"); return new ConsumerConfig(props); } @Override public void run() { Map<String, Integer> topicCountMap = new HashMap<String, Integer>(); topicCountMap.put(topic, new Integer(1)); Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = connector.createMessageStreams(topicCountMap); KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0); ConsumerIterator<byte[], byte[]> it = stream.iterator(); while (it.hasNext()) { System.out.println("receive:" + new String(it.next().message())); try { sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } } } }
启动 kafka集群, 然后启动producer,启动flume

hbase查看:
以上所有环境都是单节点部署!