1. json序列化模块
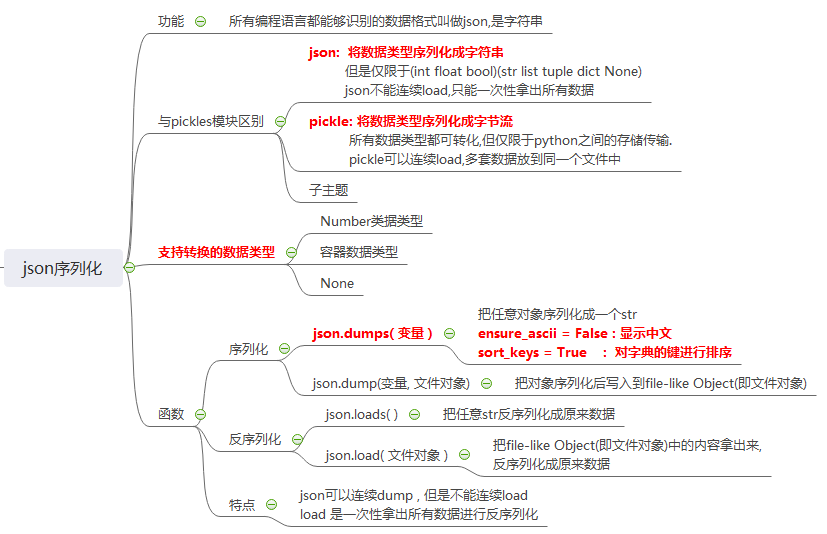


# ### json """ 所有编程语言都能够识别的数据格式叫做json,是字符串 json: 将数据类型序列化成字符串 pickle:将数据类型序列化成字节流 json能够转换的数据类型: int float bool str list tuple dict None """ import json # ### (1) json基本语法 """dumps 和 loads 是一对,用来序列化和反序列化数据的 ensure_ascii = False : 显示中文 sort_keys = True : 对字典的键进行排序 """ # dumps 把任意对象序列化成一个str dic = {"name":"常远","age":20,"sex":"男性","family":["爸爸","妈妈","妹妹"]} res = json.dumps(dic,ensure_ascii=False,sort_keys=True) print(res,type(res)) # loads 把任意str反序列化成原来数据 dic = json.loads(res) print(dic,type(dic)) """dump 和 load 是一对,根据文件进行操作存储""" dic = {"name":"常远","age":20,"sex":"男性","family":["爸爸","妈妈","妹妹"]} with open("ceshi1.json",mode="w",encoding="utf-8") as fp: json.dump(dic,fp,ensure_ascii=False) with open("ceshi1.json",mode="r",encoding="utf-8") as fp: dic = json.load(fp) print(dic , type(dic)) # ### (2)json 和 pickle之间的区别 # json """ json可以连续dump , 但是不能连续load load 是一次性拿出所有数据进行反序列化 """ dic1 = {"a":1,"b":2} dic2 = {"c":3,"d":4} with open("ceshi2.txt",mode="w+",encoding="utf-8") as fp: json.dump(dic1,fp) fp.write(" ") json.dump(dic2,fp) fp.write(" ") # 不能够把两个字典都识别出来 """ # error with open("ceshi2.txt",mode="r",encoding="utf-8") as fp: res = json.load(fp) print(res) """ # 文件对象是迭代器 from collections import Iterator res = isinstance(fp,Iterator) print(res) # loads方法来识别出每一个字典 with open("ceshi2.txt",mode="r+",encoding="utf-8") as fp: for i in fp: # print(i,type(i)) dic = json.loads(i) print(dic ,type(dic) ) # pickle """ pickle 可以连续dump , 也可以连续load pickle在插入数据时,在数据末尾写了结束的标识符,所以可以识别各个数据 """ import pickle dic1 = {"a":1,"b":2} dic2 = {"c":3,"d":4} with open("ceshi3.pkl",mode="wb") as fp: pickle.dump(dic1,fp) pickle.dump(dic2,fp) # 可以连续load print("<===>") with open("ceshi3.pkl",mode="rb") as fp: """ dic = pickle.load(fp) print(dic,type(dic)) dic = pickle.load(fp) print(dic,type(dic)) """ try: while True: dic = pickle.load(fp) print(dic) except: pass """ try .. except .. try: 把有问题的代码写到try代码块中 except: 如果发生了报错,直接执行except这个代码块 """ """ # 总结: # json 和 pickle 两个模块的区别: (1)json序列化之后的数据类型是str,所有编程语言都识别, 但是仅限于(int float bool)(str list tuple dict None) json不能连续load,只能一次性拿出所有数据 (2)pickle序列化之后的数据类型是bytes, 所有数据类型都可转化,但仅限于python之间的存储传输. pickle可以连续load,多套数据放到同一个文件中 """
2. random 模块

# ### 随机模块 random import random #random() 获取随机0-1之间的小数(左闭右开) 0<= x < 1 res = random.random() print(res) #randrange() 随机获取指定范围内的整数(包含开始值,不包含结束值,间隔值) # 一个参数 0~1 res = random.randrange(2) print(res) # 二个参数 1~9 res = random.randrange(1,10) print(res) # 三个参数 res = random.randrange(1,10,3) # 1 4 7 print(res) #randint() 随机产生指定范围内的随机整数 (了解) res = random.randint(2,5) # 2 3 4 5 print(res) #uniform() 获取指定范围内的随机小数(左闭右开) # 1 <= x < 3 res = random.uniform(1,3) print(res) # -2 < x <= 1 参数的大小可以反着写,但不推荐. res = random.uniform(1,-2) print(res) """ # return a + (b-a) * self.random() a = 1 b = -2 1 + (-2-1) * (0<= x < 1) 当x=0 => 1 1 + (-2-1) * (0<= x < 1) 当x=1 => -2 -2 < x <= 1 """ #choice() 随机获取序列中的值(多选一) lst = ["李德亮","林明辉","林荫站"] res = random.choice(lst) print(res) # 自定义choice lst = ["李德亮","林明辉","林荫站"] def mychoice(lst): num = len(lst) # 3 rand_num = random.randrange(num) # 0 1 2 return lst[rand_num] print( mychoice(lst) ) #sample() 随机获取序列中的值(多选多) [返回列表] lst = ["李德亮","林明辉","林荫站","王文","周杰伦","郭富城"] res = random.sample(lst,2) print(res) #shuffle() 随机打乱序列中的值(直接打乱原序列) lst = [ 1,2,3,4] res = random.shuffle(lst) print(res) # None 返回值没有意义 print(lst) # 小案例:随机验证码 """ # a -> 97 z->122 # A -> 65 Z->90 # print( ord("a")) # print( chr(97) ) """ def func(): strvar = "" # 循环四次 for i in range(4): #a~z sm_char = chr(random.randrange(97,123)) #A-Z bg_char = chr(random.randrange(65,91)) #0~9 num = str(random.randrange(10)) #把可能的字符元素塞到列表 lst = [sm_char,bg_char,num] #通过choice抽取其中的元素 strvar += random.choice(lst) # 返回最后的字符串 return strvar res = func() print(res)
3. time 模块
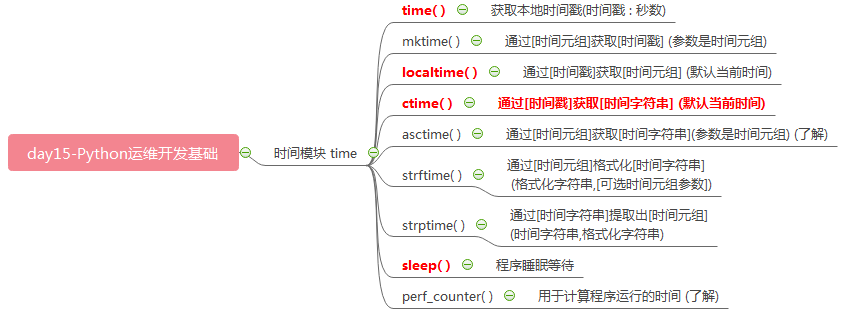
# ### 时间模块 time import time #time() 获取本地时间戳 (时间戳 : 秒数) res = time.time() print(res) #mktime() 通过[时间元组]获取[时间戳] (参数是时间元组) ttp = (2019,10,28,11,28,30,0,0,0) res = time.mktime(ttp) print(res) #localtime() 通过[时间戳]获取[时间元组] (默认当前时间) res = time.localtime() # 默认当前时间 print(res) res = time.localtime(1572233310) print(res) #ctime() 通过[时间戳]获取[时间字符串] (默认当前时间) res = time.ctime(1572233310) print(res) res = time.ctime() print(res) #asctime() 通过[时间元组]获取[时间字符串](参数是时间元组) (了解) ttp = (2019,10,28,11,34,30,1,0,0) res = time.asctime(ttp) print(res) # 优化版 (推荐) ttp = (2019,10,28,11,34,30,0,0,0) res = time.mktime(ttp) time_str = time.ctime(res) print(time_str) #strftime() 通过[时间元组]格式化[时间字符串] (格式化字符串,[可选时间元组参数]) ttp = (1955,10,28,11,39,10,0,0,0) # strftime 在linux系统中支持中文,windows不支持 res = time.strftime("%Y-%m-%d %H:%M:%S 比尔盖茨,世界首富生日") # (默认以当前时间进行转换) print(res) res = time.strftime("%Y-%m-%d %H:%M:%S 比尔盖茨,世界首富生日",ttp) print(res) #strptime() 通过[时间字符串]提取出[时间元组] (时间字符串,格式化字符串) strvar = "1955-10-28 11:39:10 比尔盖茨,世界首富生日" strvar2 = "%Y-%m-%d %H:%M:%S 比尔盖茨,世界首富生日" res = time.strptime(strvar,strvar2) print(res) #sleep() 程序睡眠等待 """ time.sleep(2) print("睡醒了") """ #perf_counter() 用于计算程序运行的时间 (了解) startime = time.perf_counter() for i in range(10000000): pass endtime = time.perf_counter() res = endtime - startime print(res) startime = time.time() for i in range(10000000): pass endtime = time.time() res = endtime - startime print(res)
4. zipfile 压缩模块
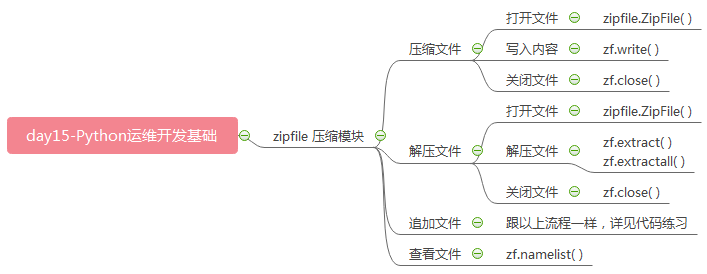
# ### zipfile 压缩模块 (zip) import zipfile # (1) 压缩文件 # 打开文件 zf = zipfile.ZipFile("ceshi1.zip","w",zipfile.ZIP_DEFLATED) # 写入内容 write(路径,别名) zf.write("/bin/bzmore","bzmore") zf.write("/bin/cat","cat") # 创建一个临时文件 叫tmp , 在tmp文件夹中放入chacl文件 zf.write("/bin/chacl","tmp/chacl") # 关闭文件 zf.close() # (2) 解压文件 # 打开文件 zf = zipfile.ZipFile("ceshi1.zip","r") # 解压单个文件 extract(文件名,路径) # zf.extract("bzmore","ceshi1") # 解压所有文件 zf.extractall("ceshi2") # 关闭文件 zf.close() # (3) 追加文件 [支持with语法] with zipfile.ZipFile("ceshi1.zip","a",zipfile.ZIP_DEFLATED) as zf: zf.write("/bin/chmod","chmod") # (4) 查看压缩包中的内容 namelist with zipfile.ZipFile("ceshi1.zip","r") as zf: lst = zf.namelist() print(lst)
5. os模块 -系统进行操作
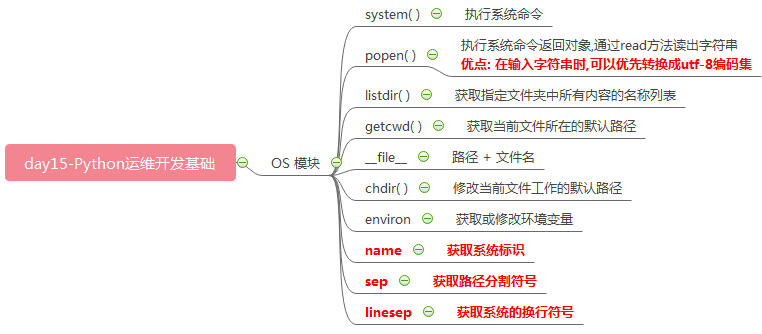
# ### os模块 -系统进行操作 import os # os.system("touch ceshi1028.txt") # os.system("rm -rf ceshi1028.txt") # os.system("ipconfig") #popen() 执行系统命令返回对象,通过read方法读出字符串 """优点:在输入字符串时,可以优先转换成utf-8编码集""" # obj = os.popen("ipconfig") obj = os.popen("ifconfig") print(obj) res = obj.read() print(res) #listdir() 获取指定文件夹中所有内容的名称列表 lst = os.listdir("/home/wangwen") print(lst) #getcwd() 获取当前文件所在的默认路径 res = os.getcwd() print(res) # /mnt/hgfs/gongxiang8/day15 # __file__ 路径 + 文件名 print(__file__) #chdir() 修改当前文件工作的默认路径 """ os.chdir("/home/wangwen/mywork") os.system("mkdir ceshi100") """ #environ 获取或修改环境变量 print( os.environ ) print( os.environ["PATH"] ) os.environ["PATH"] += ":/home/wangwen/mywork" """ environ( {'PATH': '/root/PycharmProjects/untitled/venv/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin', 'XAUTHORITY': '/home/wangwen/.Xauthority', 'TERM': 'xterm-256color', 'LANG': 'zh_CN.UTF-8', 'PS1': '(venv) ', 'SUDO_USER': 'wangwen', 'DISPLAY': ':0', 'SUDO_GID': '1000', 'MAIL': '/var/mail/root', 'USERNAME': 'root', 'LOGNAME': 'root', 'PWD': '/mnt/hgfs/gongxiang8/day15', 'SUDO_UID': '1000', 'PYCHARM_HOSTED': '1', 'PYCHARM_DISPLAY_PORT': '36249', 'LANGUAGE': 'zh_CN:zh', 'PYTHONPATH': '/root/PycharmProjects/untitled:/home/wangwen/mysoft/pycharm-2019.1.2/helpers/pycharm_matplotlib_backend:/home/wangwen/mysoft/pycharm-2019.1.2/helpers/pycharm_display', 'SHELL': '/bin/bash', 'PYTHONIOENCODING': 'UTF-8', 'OLDPWD': '/home/wangwen/mysoft/pycharm-2019.1.2/bin', 'USER': 'root', 'SUDO_COMMAND': './pycharm.sh', 'VIRTUAL_ENV': '/root/PycharmProjects/untitled/venv', 'PYTHONUNBUFFERED': '1', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.xspf=00;36:', 'HOME': '/home/wangwen'}) """ """ [linux] 通过python操作linux里面的脚本,要把脚本的路径添加到环境变量path路径中 (1) 在/home/wangwen/mywork 创建文件abc.sh (2) 在abc.sh里 写入ifconfig这个命令 (3) 修改abc.sh权限,改成777 (4) os.environ["PATH"] += ":/home/wangwen/mywork" 把脚本对应的路径添加到环境变量中 (5) python system这个命令执行 abc.sh 这个脚本 [windows] cmd中通过命令调出qq窗口 (1) 找到该文件的路径,右键属性找路径 (2) 右键我的电脑属性->高级系统设置->系统变量Path->新建把刚才的路径黏贴上去 (3) cmd -> QQScLauncher.exe """ os.system("abc.sh") #--os 模块属性 #name 获取系统标识 linux,mac ->posix windows -> nt print(os.name) #sep 获取路径分割符号 linux,mac -> / window-> print( os.sep ) #linesep 获取系统的换行符号 linux,mac -> window-> 或 print( os.linesep ) print( repr(os.linesep) )
day15