1. 要实现C++的每一个语言特性,不同的编译器可能采取不同的方法,其中某些特性(如标题所列)的实现可能会对对象的大小和其member functions的执行速度带来冲击.
2. 虚函数.
当通过对象指针或引用调用虚函数时,具体调用哪一个虚函数由指针或引用的动态类型决定,大部分编译器使用vtbls(virtual tables,虚函数表)和vptrs(virtual table pointers,虚函数表指针)来实现这一点.
vtbl通常是一个函数指针的数组或链表,每一个声明或继承虚函数的类都有自己的vtbl,其中的每一个元素就是该类的各个虚函数的指针.假如以下类:


class C1{ public: C1(); virtual void f1(); virtual int f2(char) const; virtual void f3(const string&) const; void f4() const; ... }
C1的vtbl看起来像这样:

(注意,非虚函数f4和C1 constructor并不在表格中!)
如果C2继承C1,并重新定义部分虚函数,即:
class C2: public C1 { public: C2(); virtual ~C2(); virtual void f1(); virtual void f5(char *str); ... };
那么C2的vtbl看起来像这样:

从以上示例可以看出虚函数的第一个成本:必须为每一个拥有虚函数的类消耗一块vtbl空间,用于存储虚函数指针.
由于每个类只有一个vtbl,这就产生了第二个问题:由于C++支持多文件编译,而每一个目标文件都是独立生成的,因而类的vtbl放在哪一个目标文件就需要选择.编译器厂商倾向于两种阵营:一种暴力式做法就是在每一个需要vtbl的目标文件内都产生一个vtbl副本,最后由链接器剥除重复副本;另一种更常见的勘探式做法将vtbl产生于"内含其第一个non-inline,non-pure虚函数定义式"的目标文件中.因此,先前class C1,C2的vtbl应该分别放在内含C1::~C1和C2::~C2定义式的目标文件中.这中勘探式做法要求类必须有一个non-inline的虚函数,如果所有函数都声明为inline,那么大部分编译器会在每一个"使用了class's vtbl"的目标文件中,在大型系统中,由此造成的代码和内存膨胀是十分可观的.因此,要尽量避免将虚函数声明为inline,事实上,编译器通常会忽略虚函数的inline指示.
由于每个对象都需要对应其所属类型的vtbl,以便在通过指针或引用调用虚函数时实现动态绑定,这就导致了虚函数的第二个成本:每个对象都内含一vptr,用于指向该类的vtbl.
vptr被加入对象的某个位置,不同编译器对此实现不同,如果vptr加入到对象尾端(以下都假设vptr加入到尾端),那么对象构造看起来像这样:

4字节的vptr导致的对象大小膨胀所产生的影响可大可小(与对象大小和运行平台等相关),但较大的对象往往意味着较难塞入一个缓存分页(cache page)或虚内存分页(virtual memory page),也就意味着换页(paging)活动可能会增加.
综合上述,object和vtbl的关系可能像这样
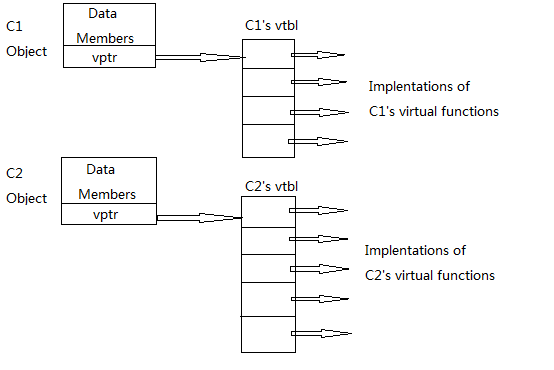
考虑这样的程序片段:
void makeCall(C1* pC1){ pC1->f1(); }
由于指针pC1所值对象的动态类型不确定,因而f1的实体是哪一个也就不确定,但编译器仍然要为f1的调用操作产生可执行代码,完成以下动作:
1). 根据对象对象的vptr找到其vtbl.此动作成本只有一个偏移调整(offset adjustment,以便获得vptr)和一个指针间接动作(以便获得vtbl).
2). 找出被调用函数(本例为f1)在vtbl内的对应指针.其成本只是一个偏移(offset)以求进入vtbl数组.
3). 调用步骤2所得指针指向的函数.
因此以上对于f1的调用操作,编译器产生的代码可能像这样:
(pC1->vptr[i])(pC1); //i为f1在vtbl中的下标
这几乎与一个非虚函数的效率相当.因此虚函数的调用成本基本上和"通过一个函数指针来调用函数"相同,虚函数本身并不构成性能上的瓶颈.
虚函数真正的运行成本在于和inlining发生互动的时候,原则上不应该对虚函数实行inline:inline意味着"在编译期,将调用端的调用操作被被调用函数的函数本体取代",而virtual则意味着"等待,直到运行时期才知道哪个函数被调用".当编译器面对某个调用动作却无法提前得知哪一个函数该被调用时,就没有能力对该函数实现inline了.因此通过指针或引用的虚函数调用是无法被inline的,由于此等调用行为是常态,所以虚函数事实上等于无法被inline.
3. 多重继承和虚继承
多重继承下,"找出对象内的vptrs"会变得比较复杂:此时一个对象内会有多个vptrs(每个base class各对应一个);除了之前所讨论的vtbl,针对base classes而形成的特殊vtbl也会被产生出来.结果虚函数对每一个object和每一个class造成的空间负担又增加了一些,运行期调用成本也有所成长.
多重继承往往导致virtual base classes(虚拟基类)的需求.在non-virtual base的情况下,如果派生类对于基类有多条继承路径,那么派生类会有不止一个基类部分,让基类为virtual可以消除这样的复制现象.然而虚基类也可能导致另一成本:其实现做法常常利用指针,指向"virtual base class"部分,因此对象内可能出现一个(或多个)这样的指针.
例如以下多重继承"菱形"结构:
class A{...}; class B:virtual public A{...}; class C:virtual public A{...}; class D:pulic B,public C{...};
A是个虚基类,B和C都采用虚继承,在某些编译器下,D对象的内存布局可能如下:
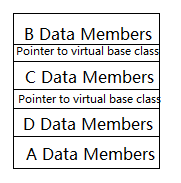
这是在没有虚函数参与的情况下,如果A类有虚函数,那么D的布局类似这样

上图一个奇怪之处在于明明有4个类,却只有三个vptr,原因在于B和D可以共享同一个vptr,大多数编译器会采取此策略.
4. RTTI(runtime type identification,运行时类型识别)
RTTI使得可以在运行时获得objects和classes的相关信息,因此其实现必须需要一些内存来存储那些信息:类型信息用type_info类型的对象存放,可以用typeid操作符取得class对应的type_info对象.
一个类只需要一份RTTI信息,但必须要使得属于这个类的每个对象都能够取得该信息,这和vtbl的要求相同,因此RTTI的的设计理念便是根据class的vtbl来实现.通常在vtbl索引为0的元素存放一指针,用来指向"该vtbl所对应的class"的相应的type_info对象,因此2中的C1的vtbl实际上可能像这样:

运用这种实现方法,RTTI的运行成本就只需要在每一个class vtbl内增加一个条目,再加上每个class所需的一个type_info对象空间.
注意,由于多数编译器利用这种方法实现RTTI,因此要某个类要使用RTTI,就必须有vtbl,而要有vtbl,就必须有虚函数,也就是说,没有虚函数的类是无法使用RTTI的,也就无法啊进行dynamic_cast.
5. 以下表格是虚函数,多重继承,虚拟基类和RTTI的主要成本摘要
|
性质 |
对象大小增加 |
Class 数据量增加 |
Inlining几率降低 |
|
虚函数(Virtual Functions) |
是 |
是 |
是 |
|
多重继承(Multiple Inheritance) |
是 |
是 |
否 |
|
虚拟基类(Virtual Base Classes) |
常常 |
有时候 |
否 |
|
运行时类型识别(RTTI) |
否 |
是 |
否 |
从以上可见,C++要支持面向对象,付出了一定的时间和空间成本,但是也因此实现了更强大易用的功能.如果坚持使用C语言,那么以上功能都必须自己打造.相对于编译器产生的代码,自己打造的东西可能比较没效率,也不够鲁棒性.从效率上来说,自己动手打造未必会比编译器做的更好.当然,有时确实要避免编译器在背后所做的这些工作,比如隐藏的vptr以及"指向virtual base classes"的指针,可能会造成"将C++对象存储于数据库"或"在进程边界间搬移C++对象"时的困难度提高,这是可能就需要手动模拟这些性质.
对于C++面向对象模型的深入了解可参照《深入探索C++对象模型》.