论文:《Image-to-Image Translation with Conditional Adversarial Networks》
发表日期:2017 CVPR
前言
pix2pix是cGAN的一个变体,能够实现从图像到图像的映射,在从标签映射合成照片、从边缘映射重建对象、图片上色等多类人物的表现较好。它比较适合于监督学习,即图像的输入和它的输出是相互匹配的。所谓匹配数据集是指在训练集中两个互相转换的领域之间有明确的一一对应数据。在工程实践中研究者需要自己收集这些匹配数据,但有时同时采集两个不同领域的匹配数据是麻烦的,通常采用的方案是从更完整的数据中还原简单数据。比如直接将彩色图片通过图像处理的方法转为黑白图片。
训练完成后,pix2pix可以将图像从领域A变换到领域B。下面这张图中,左侧的input和output分别是同一个地方白天和夜晚的照片,看作是不同领域X和Y的两张图,生成器G应尽可能得将input转换成output。

注意,因为匹配数据集的存在,研究者尝试用普通CNN进行图像对图像的变换,但是不能生成清晰逼真的图像,因为CNN会试图让最终的输出接近所有相类似的结果。
理论基础
训练思路:
下图展示了Pix2Pix使用cGAN训练生成对抗网络的思路,这里是手绘鞋和真实鞋子图像的一组配对数据,生成器通过作为条件的手绘数据生成了左图中的鞋子,然后我们将两者放入判别器中,判别器应该判断为假,而当我们将真实的配对数据输入时,判别器应该判断为真。

网络架构
生成网络
生成网络深受U-Net架构的启发。U-Net架构和自编码网络的架构非常相似,一个主要区别是U-Net网络在编码网络和解码网络的各层之间有跳跃连接,而自编码网络没有,跳跃连接可以将部分有用的重复信息直接共享到生成器中。-Net网络由编码网络和解码网络组成。下图展示了U-Net的基本架构。

上图展示了U-Net基本架构。可以看到,第一层的输出直接和最后一层合并,第二层的输出和倒数第二层合并,以此类推。如果总层数为n,那么在编码网络的第i层和解码网络的第(n - i)层之间就会有跳跃连接,对于所有层皆是如此。
所有拼接都是沿通道轴进行的。编码网络的最后一层将张量传递给解码网络的第一层。编码网络的最后一块和解码网络的最后一块之间并无拼接。
生成网络由上述两个网络组成。简单说来,编码网络是一个下采样网络,解码网络是一个上采样网络。编码网络将维度是(256, 256, 1)的图像下采样为维度是(1, 1, 512)的内部表示,而解码网络将维度是(1, 1, 512)的内部表示上采样为维度是(256, 256, 1)的输出图像。
判别网络
pix2pix的判别网络架构受到了PatchGAN架构的启发。PatchGAN包含8个卷积块,若输入的形状为(256, 256, 1),最后的输出形状变成(1, 1, 512),最后经过扁平化层将张量转换成一组数组,再经过全连接层得到最后判定。
故判别网络由8个卷积块、1个全连接层和1个扁平化层组成。判别网络接收从维度为(256, 256, 1)的图像中提取的一组图像块,然后估测给定图像块为真的概率,一般使这个值激活在0~1之间;。
目标函数
我们先重温之前提到过的cGAN的目标函数,如式(8-1)所示,其中(D(x, y))表示真实配对数据输入图像x与输出图像y对于判别器D的结果,而(D(x, G(x, z)))则是x经过生成器产生的图像G(x, z)对于判别器判断的结果。

除了上面的cGAN优化函数以外,Pix2Pix的论文里还提到可以加入L1 Loss作为传统的损失函数对网络加以优化。

最终的生成器目标函数如下所示,其中λ为超参量,可以根据情况调节,当λ=0时表示不采用L1 Loss的损失函数。

在cGAN中虽然没有随机参量z,其实整个网络也是可以运行的,但这导致的结果是生成器的每一个输入都会对应一个确定的输出结果。
实验结果
下面我们来看一下Pix2Pix在不同状态下的测试结果,调节公式中的λ,有以下三种情况:仅使用传统的L1 Loss、仅使用cGAN以及同时使用两者的目标函数,结果如图所示。
L1 & cGAN

更多具体数据的测试结果如下所示,分别计算了五种组合情况下的像素精确度、分类精确度以及分类IoU(Intersection over Union的缩写,一种计算预测区域与真实区域重叠部分占比的计算方法), L1 + cGAN的组合在各项指标中都是最接近理想状态的。

从图1中,我们会发现L1 Loss的输出结果是大致接近原始图像的,但是由于之前提到传统深度学习的问题即导致生成图像非常模糊,而使用cGAN所生成的图像则具备了细节清晰的效果,但是它的问题在于额外添加了很多不必要的细节,有时离原本的真实图像在细节上差距较大。最后一组L1 + cGAN的输出结果是比较令人满意的,综合了两者的特性,既完善了细节也保证了一致性。
我们可以总结出L1 Loss用于生成图像的大致结构、轮廓等,也可以说是图像的低频部分。而cGAN则主要用于生成细节,是图像的高频部分。Pix2Pix在这一点上进行了优化,研究者认为既然GAN仅用于高频部分的生成,那么在训练过程中也没有必要把整个图像都拿来做训练,仅需把图像的一部分作为判别器的接收区域即可,这也就是PatchGAN的思想。由于参数更少,PatchGAN可以使得训练过程变得更加高效,同时也可以针对更大的图像数据集进行训练。
不同Patch的影响
在Patch的大小上Pix2Pix也进行了测试,针对原始图像为286×286的情况,分别采用了1×1像素(称为PixelGAN)、16×16像素、70×70像素以及全图286×286像素(称作ImageGAN),结果如下图所示。相比于模糊的L1生成图像,PixelGAN虽然未能在图像细节上改进,但是在色彩上面已经优于原始L1的方案。16×16和70×70的PatchGAN均取得了比较不错的效果,相比之下70×70在色彩还原和图像细节上都更胜一筹,而最后ImageGAN和70×70的PatchGAN相差不大。在最终的数据结果中,70×70的PatchGAN取得了最好的成绩。


U-Net & 编解码器
下图展示了使用传统编码解码网络与U-Net之间的差别,在仅使用L1 Loss和L1 +cGAN的两种情况下,U-Net都具备了比较高的清晰度,生成了更高质量的图像数据。表8-3记录了四种组合情况下三种准确度的比较,使用U-Net的L1 + cGAN方案在各种精度计算下都表现最优。


不同场景下的pix2pix效果图



知识补充
PatchGAN的patch
GAN一般情况下的网络结构,在一些人的实验中已经表明对于要求高分辨率、高细节保持的图像领域中并不适合,有些人根据这一情况设计了PatchGAN的思路。这种GAN的差别主要是在于Discriminator上,一般的GAN是只需要输出一个true or fasle 的矢量,这是代表对整张图像的评价;但是PatchGAN输出的是一个N x N的矩阵,这个N x N的矩阵的每一个元素,比如a(i,j) 只有True or False 这两个选择(label 是 N x N的矩阵,每一个元素是True 或者 False,来表示patch ij的真假),这样的结果往往是通过卷积层来达到的,所以PatchGAN将判别器换成了全卷积网络.因为逐次叠加的卷积层最终输出的这个N x N 的矩阵,其中的每一个元素,实际上代表着原图中的一个比较大的感受野,也就是说对应着原图中的一个Patch,因此具有这样结构以及这样输出的GAN被称之为PatchGAN。
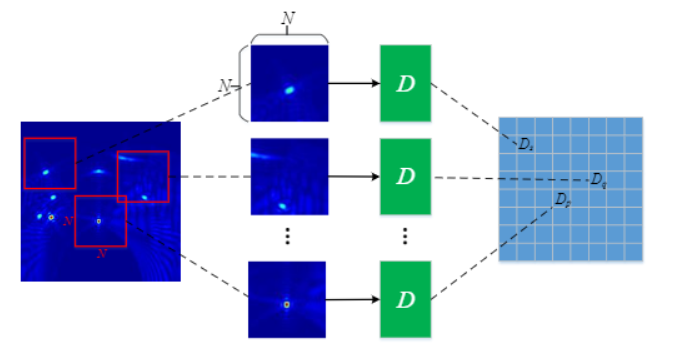
这样,通过每个patch 进行差别的判别,实现了局部图像特征的提取和表征,有利于实现更为高分辨率的图像生产;同时, 对最后的分类特征图进行平均后,也能够实现相比。