win10上部署Hadoop-2.7.3——非Cygwin、非虚拟机
开始接触Hadoop,听人说一般都是在Lunix下部署Hadoop,但是本人Lunix不是很了解,所以Google以下如何在Win10下安装Hadoop(之后再在Lunix下弄),找到不少文章,以下是主要参考的文章:
1、Hadoop installation on windows without cygwin in 10 mints
3、Apache Hadoop for Windows Platform
这里是按照第一篇文章操作的。
一、安装jdk,地址为http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 具体的操作以及配置环境变量这里就不演示了,这里有一点需要注意的是默认会安装在C:Program Files 下,开始我也是安装在这里,但是后来报错了,报什么“JAVA_HOME”的错误具体的记不清了。查了一下说是因为安装路径中有空格,晕了,所以安装在如下目录:

二、下载Hadoop,地址为 https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/ 这里选择的是hadoop-2.7.3.tar.gz
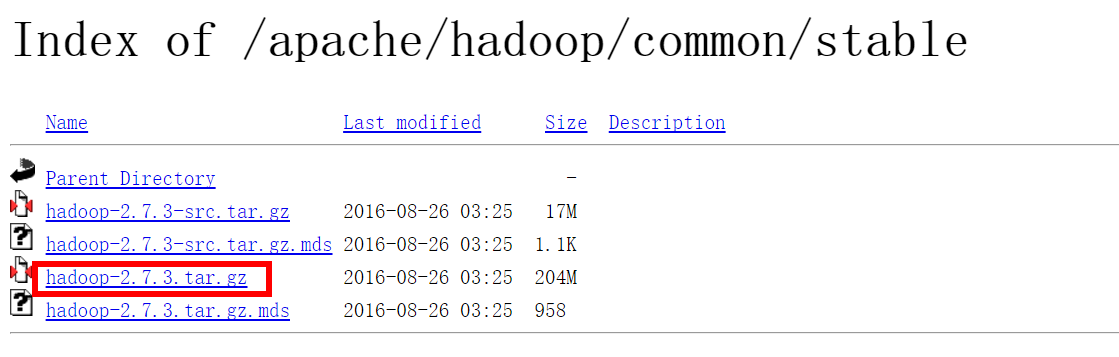
三、将其解压到某一文件夹,这里为D:hadoophadoop-2.7.3
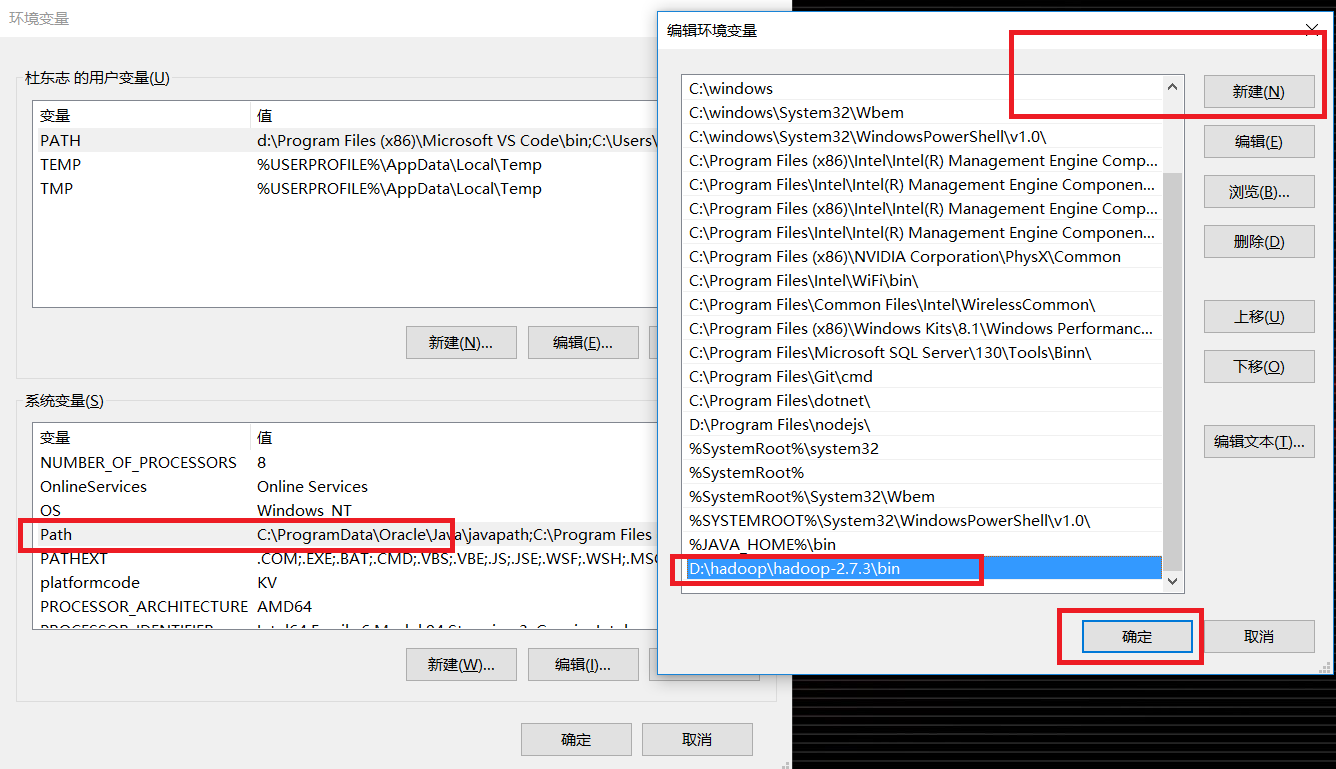
四、添加“HADOOP_HOME”环境变量,并添加到Path环境变量中,按照下图操作

五、修改Hadoop配置文件,在这之前你要先下载sardetushar_gitrepo_download ,之后解压,删掉D:hadoophadoop-2.7.3目录下的bin、etc文件夹,用刚刚解压的替换。
1、D:hadoophadoop-2.7.3etchadoopcore-site.xml


<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2、D:hadoophadoop-2.7.3etchadoopmapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3、D:hadoophadoop-2.7.3etchadoophdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/data/datanode</value>
</property>
</configuration>
这个配置这里要感谢一下这篇帖子:http://stackoverflow.com/questions/34871814/failed-to-start-namenode-in-hadoop 按照第一篇教程配置会出错的!!!
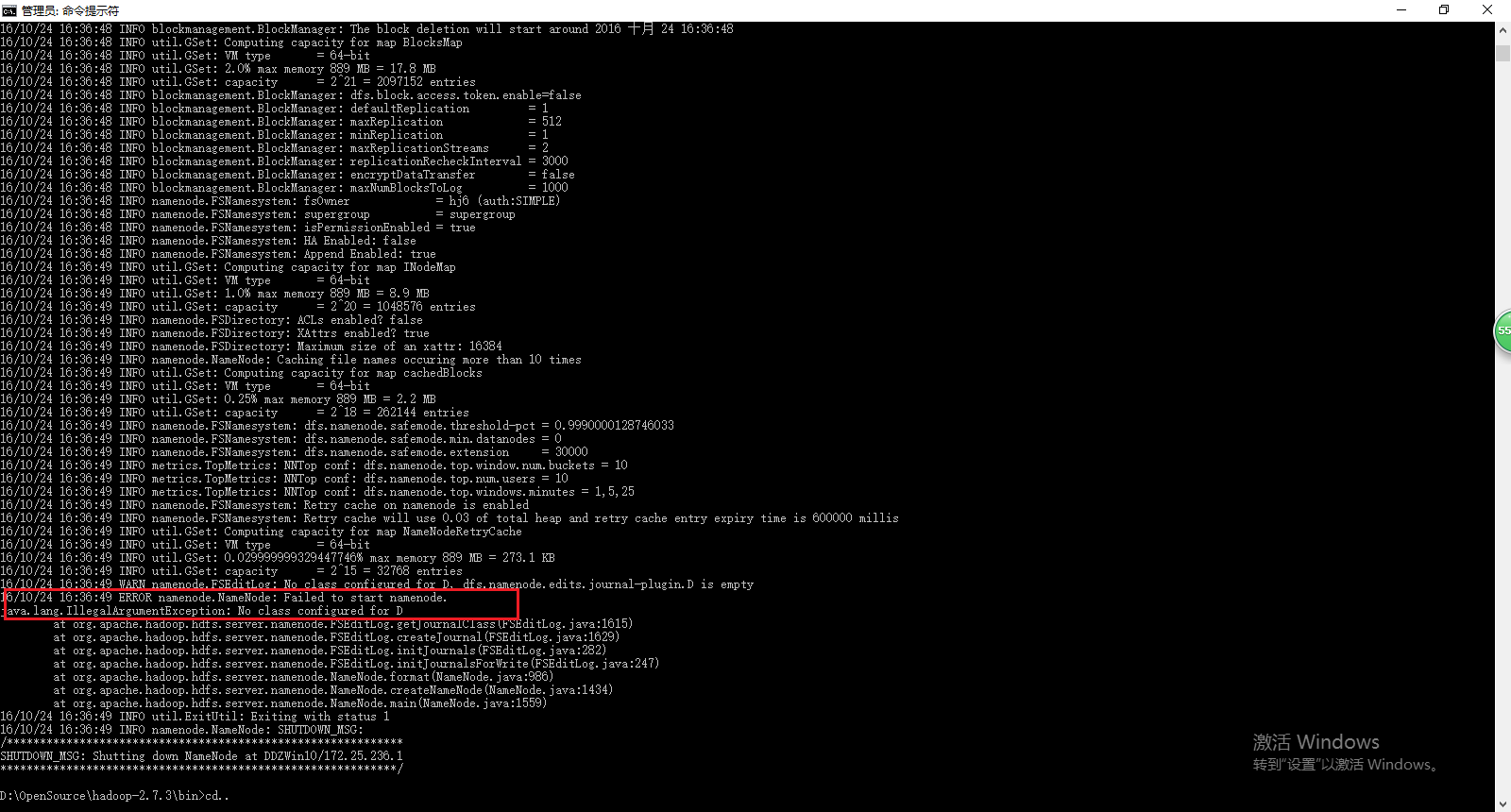
如果你的路径形如d:/hadoop/data/namenode 就会出现上图错误,如果路径是在E:,那么上图中的异常就会是E
4、D:hadoophadoop-2.7.3etchadoopyarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
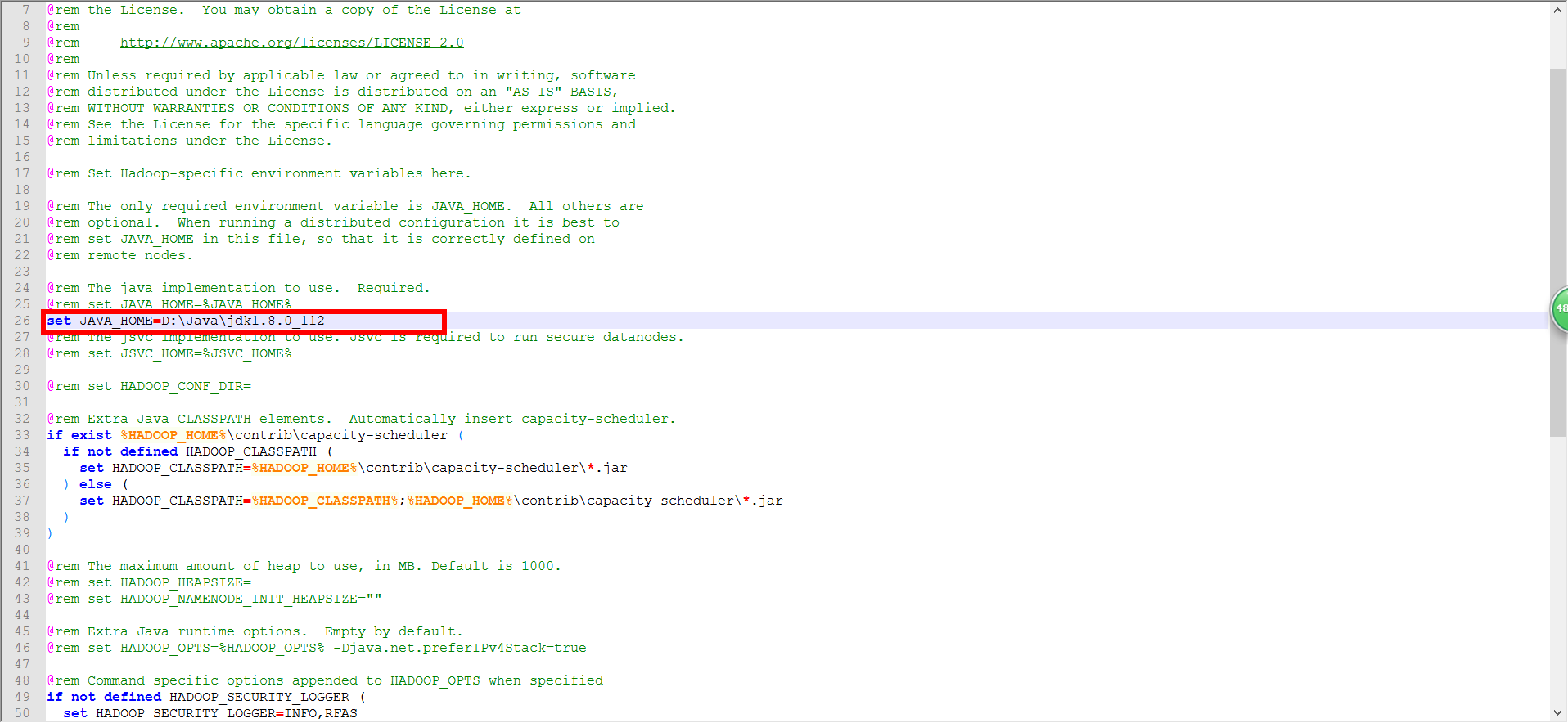
5、D:hadoophadoop-2.7.3etchadoophadoop-env.cmd (修改JDK的安装路径)(注意,如果jdk在C:Program Files下,就使用C:PROGRA~1代替)
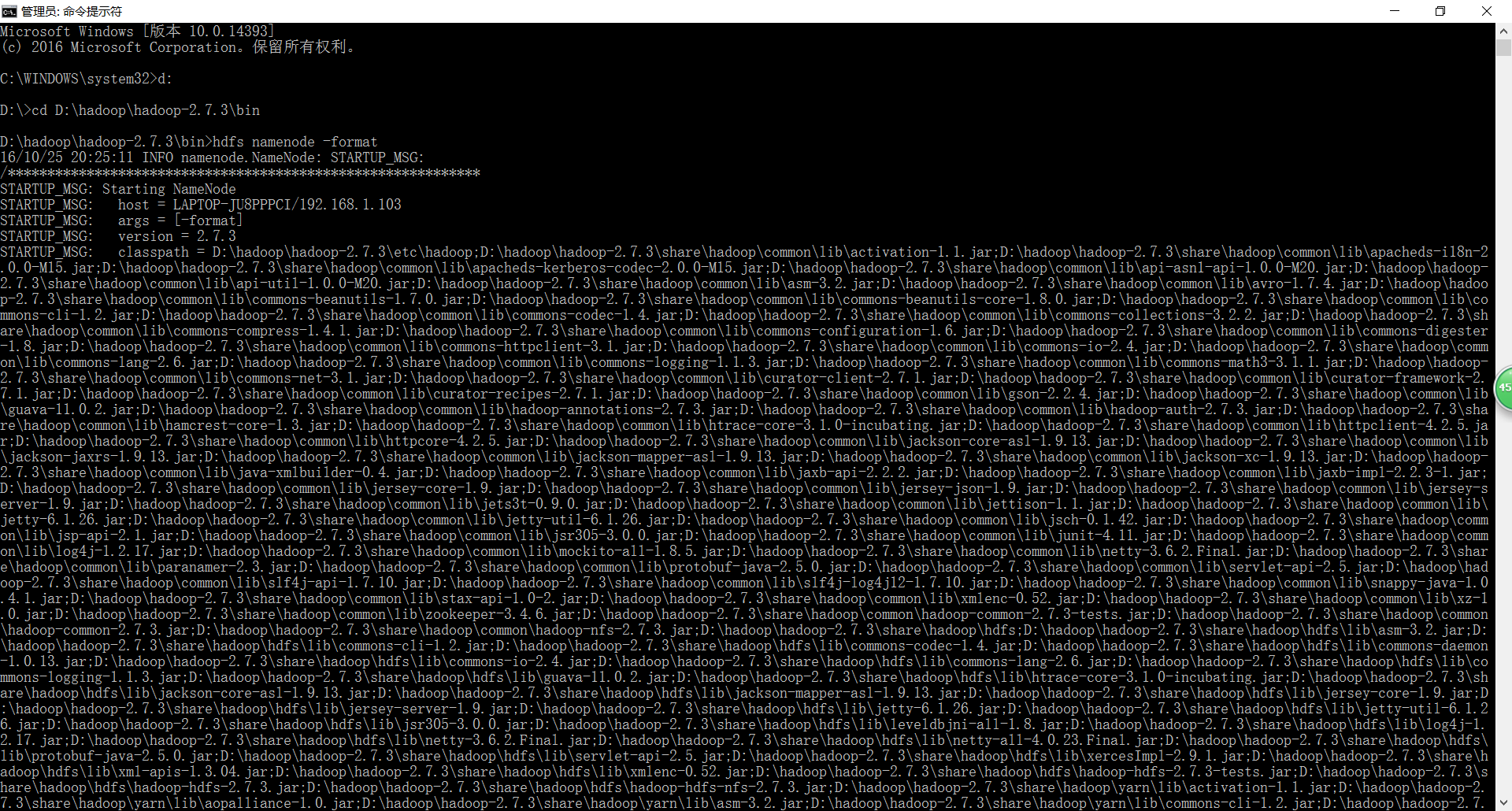
六、格式化HDFS文件系统,hdfs namenode -format 如下图,
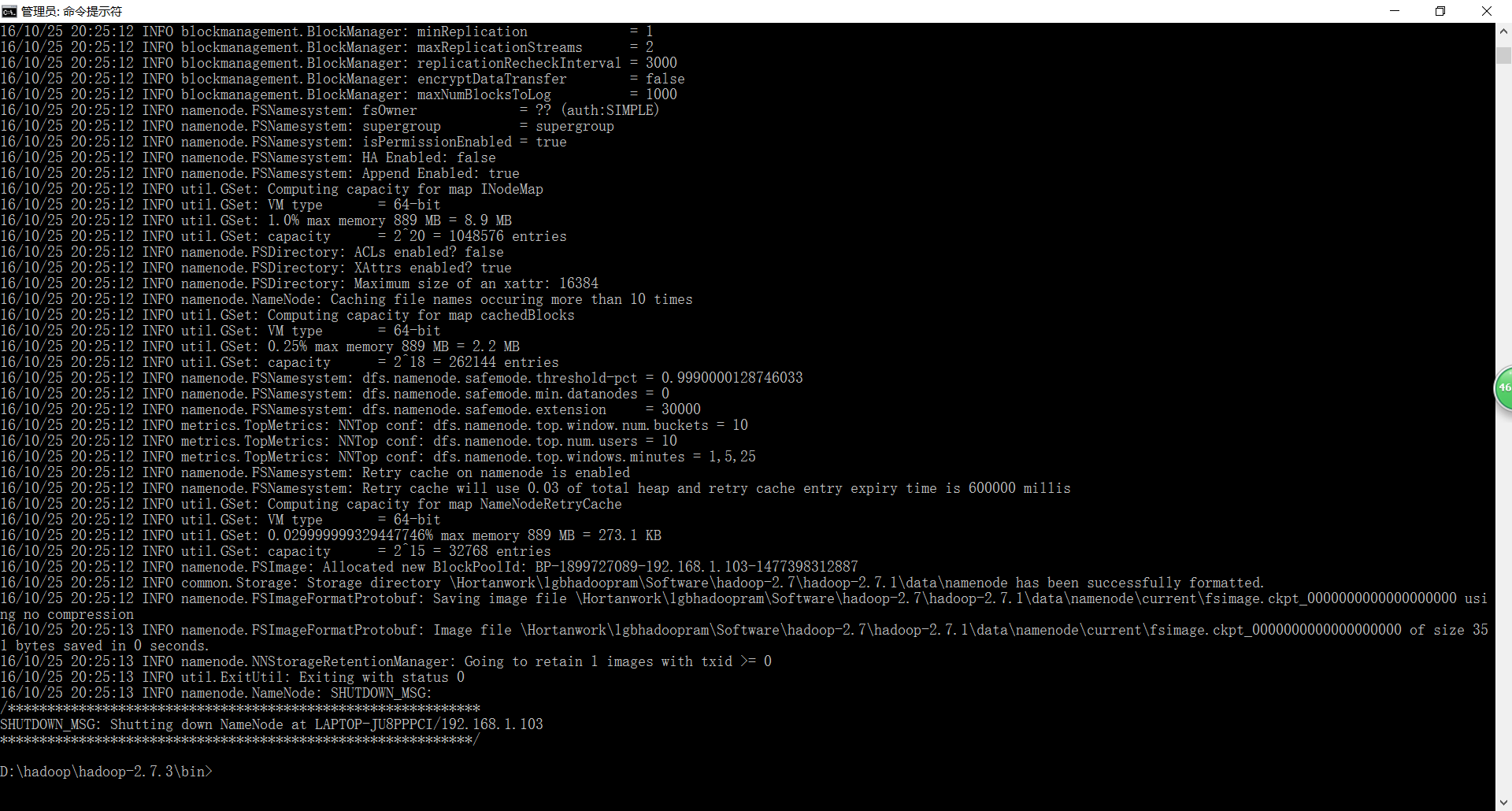
如果这一步没有什么异常基本没有问题了。
七、在命令行(管理员)将目录指向D:hadoophadoop-2.7.3sbin,键入“start-all”
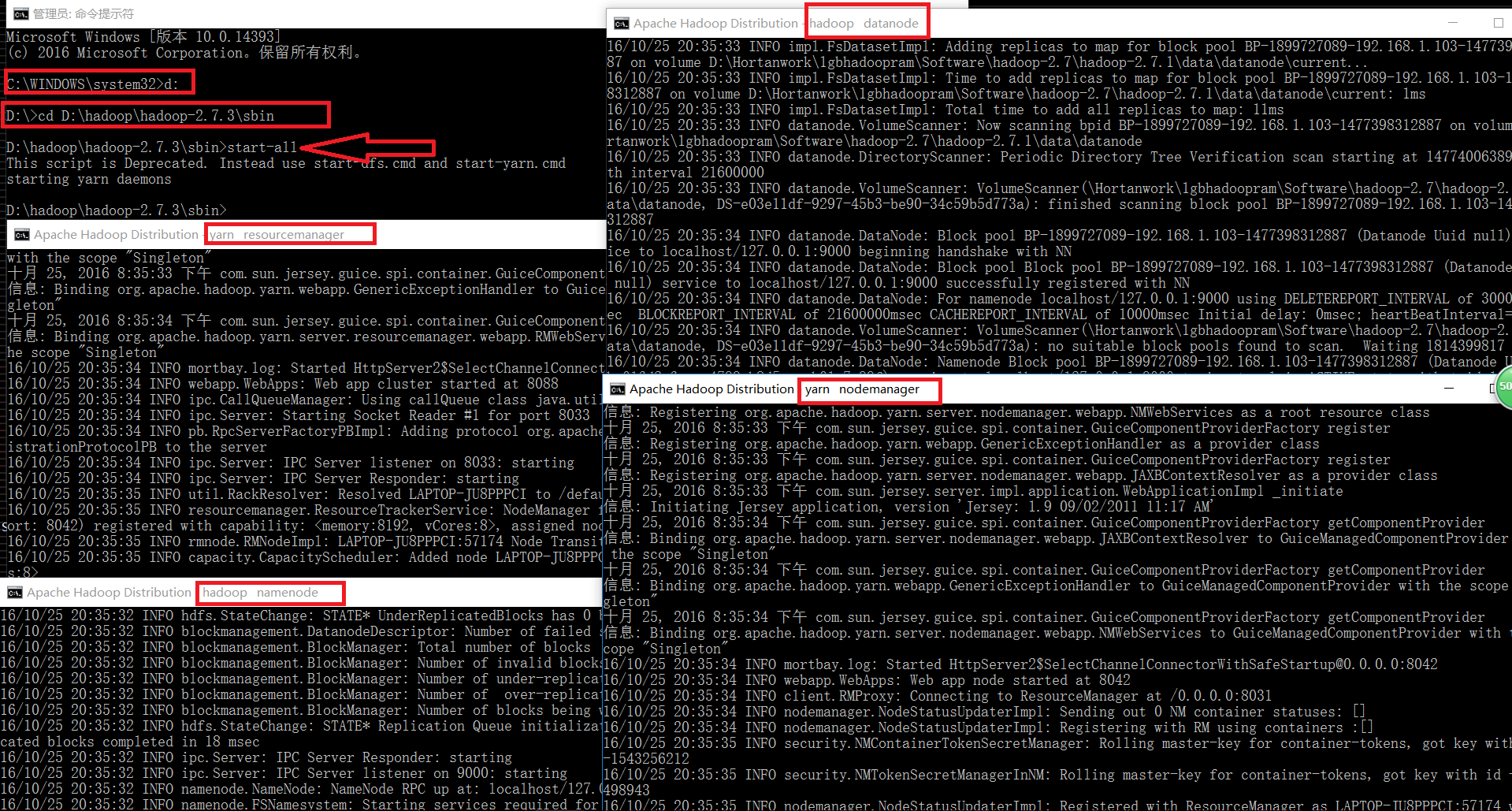
Namenode、Datanode、YARN resourcemanager、YARN nodemanager四个进程启动成功,再看一下网站截图:
localhost:8088

localhost:50070

最后我们可以使用“stop-all”停止Hadoop

原文章:https://www.cnblogs.com/du-blog/p/5998388.html