案例:
现在手上有许多的文档,需要将其按照类型(体育,财经,科技等)进行分类,也就是对文章进行分组或聚类.
分析:
如果手上有已经标记过类型的数据,可以将其作为训练集进行学习.
那么这是否是一个多元分类问题?
其实是监督学习问题
现在我们有一堆无标签的文档,打算推断出相关文章的分组向量.
Input:文档向量
Output:集群标签
这是一个无监督学习任务.
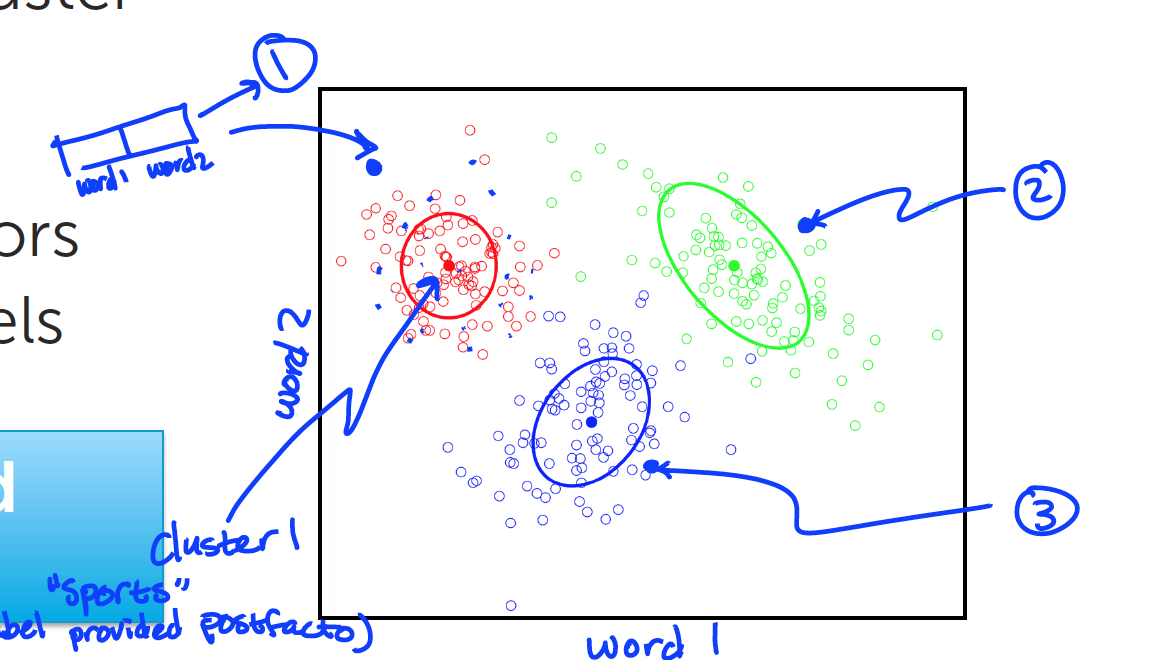
怎样去定义一个集群:
集群用中心和形状来定义.
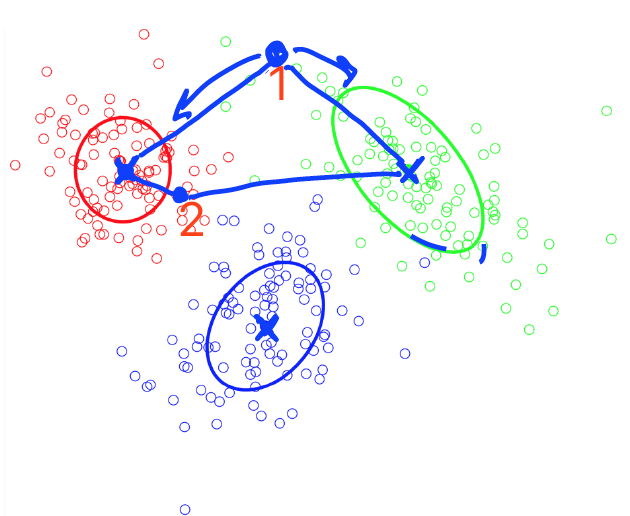
以形状来判断,上方1号点明显应属于椭圆形集群.而若是以距离来看,2号点明显属于圆形集群.
聚类算法:k-means
k均值算法(k-means):固定k个集群,看每个集群的平均值.只考虑集群中心,以此来将数据点分不到不通的集群中.
步骤:
1.初始化集群中心
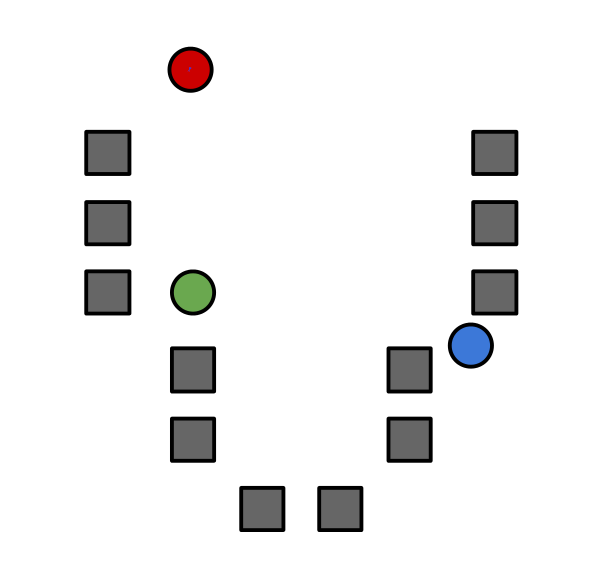
2.把所有数据点分给离它最近的集群中心.(沃罗诺伊镶嵌算法)
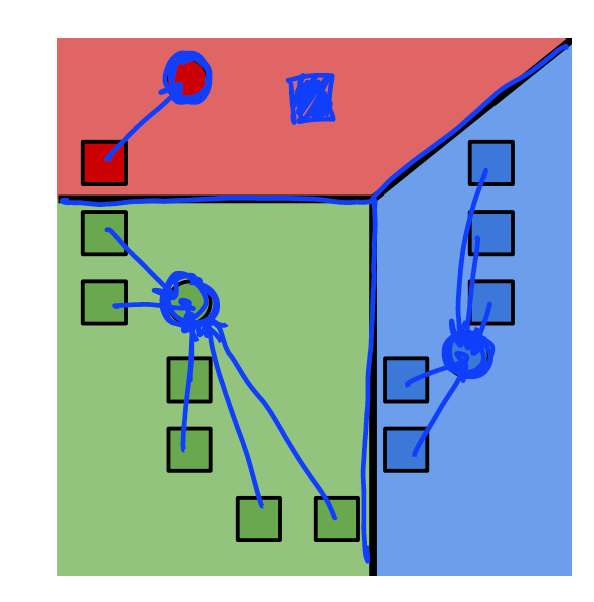
3.将聚类中心修改为指定的观测值的平均值.
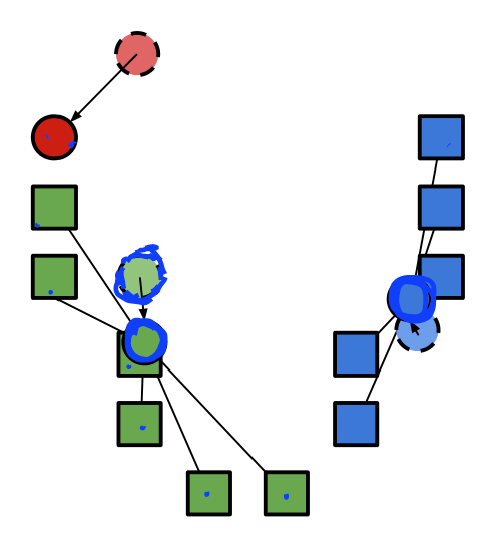
4.重复前面的步骤,直到结果收敛.
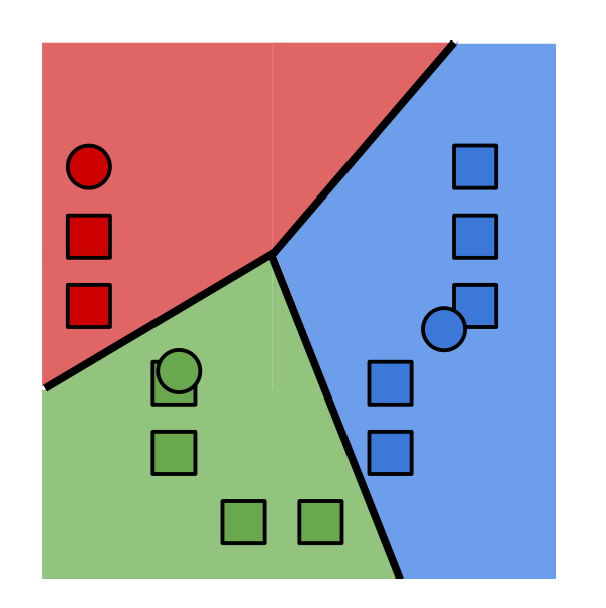
其他的例子:
1.图像分类
2.疾病分类
3.商品分类
4.网页搜索优化
5.房价预测
6.预测犯罪率
end
课程:机器学习基础:案例研究(华盛顿大学)
视频链接: https://www.coursera.org/learn/ml-foundations/lecture/EPR3S/clustering-documents-task-overview
week4 Clustering models and algorithms