最近在学习一个网站补充一下cg基础。但是前几天网站突然访问不了了,同学推荐了waybackmachine这个网站,它定期的对网络上的页面进行缓存,但是好多图片刷不出来,很憋屈。于是网站恢复访问后决定把网页爬下来存成pdf。
两点收获:
1.下载网页时图片、css等文件也下载下来,并且修改html中的路径。
2. beautifulsoup、wkhtmltopdf很强大,用起来很舒心
前期准备工作:
0.安装python
1.安装pip
下载pip的安装包get-pip.py,下载地址:https://pip.pypa.io/en/latest/installing.html#id7
然后在get-pip.py所在的目录下运行get-pip.py
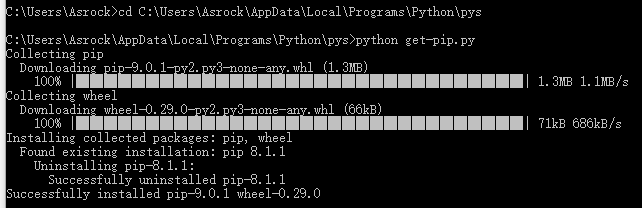
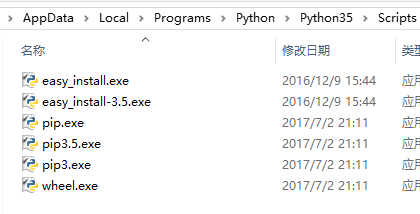
执行完成后,在python的安装目录下的Scripts子目录下,可以看到pip.exe
升级的话用 python -m pip install -U pip
2. 安装wkhtmltopdf : 适用于多平台的 html 到 pdf 的转换工具
3. install requests、beautifulsoup、pdfkit.
pdfkit 是 wkhtmltopdf 的Python封装包
beautifulsoup用于操纵html内容。
2.代码实现
from _ssl import PROTOCOL_TLSv1
from functools import wraps
import os
from ssl import SSLContext
import ssl
from test.test_tools import basepath
import urllib
from urllib.parse import urlparse # py3
from bs4 import BeautifulSoup
import requests
import urllib3
def sslwrap(func):
@wraps(func)
def bar(*args, **kw):
kw['ssl_version'] = ssl.PROTOCOL_TLSv1
return func(*args, **kw)
return bar
def save(url,cls,outputDir,outputFile):
print("saving " + url);
response = urllib.request.urlopen(url,timeout=500)
soup = BeautifulSoup(response,"html5lib")
#set css
#save imgs
#save html
if(os.path.exists(outputDir+outputFile)):
os.remove(outputDir+outputFile);
if(cls!=""):
body = soup.find_all(class_=cls)[0]
with open(outputDir+outputFile,'wb') as f:
f.write(str(body).encode(encoding='utf_8'))
else:
with open(outputDir+outputFile,'wb') as f:
f.write(str(soup.find_all("html")).encode(encoding='utf_8'))
print("finish!");
return soup;
def crawl(base,outDir):
ssl._create_default_https_context = ssl._create_unverified_context
heads = save(base+"/index.php?redirect","central-column",outDir,"/head.html");
for link in heads.find_all('a'):
pos = str(link.get('href'))
if(pos.startswith('/lessons')==True):
curDir = outDir+pos;
if(os.path.exists(curDir)==False):
makedirs(curDir)
else:
print("already exist " + curDir);
continue
counter = 1;
while(True):
body = save(base+pos,"",curDir,"/"+str(counter)+".html")
counter+=1;
hasNext = False;
for div in body.find_all("div",class_="footer-prev-next-cell"):
if(div.get("style")=="text-align: right;"):
hrefs = div.find_all("a");
if(len(hrefs)>0):
hasNext = True;
pos = hrefs[0]['href'];
print(">>next is at:"+pos)
break;
if(hasNext==False):
break;
if __name__ == '__main__':
crawl("https://www.***.com", "E:/Documents/CG/***");
print("finish")