概述:
交代一下背景,这算是一次项目经验吧,属于公司一个已上线平台的功能,这算是离职人员挖下的坑,随着数据越来越多,原本的SQL查询变得越来越慢,用户体验特别差,因此SQL优化任务交到了我手上。
这个SQL查询关联两个数据表,一个是攻击IP用户表主要是记录IP的信息,如第一次攻击时间,地址,IP等等,一个是IP攻击次数表主要是记录每天IP攻击次数。而需求是获取某天攻击IP信息和次数。(以下SQL语句测试均在测试服务器上上,正式服务器的性能好,查询时间快不少。)
准备:
查看表的行数: 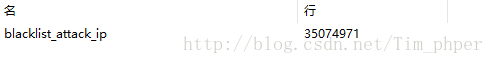

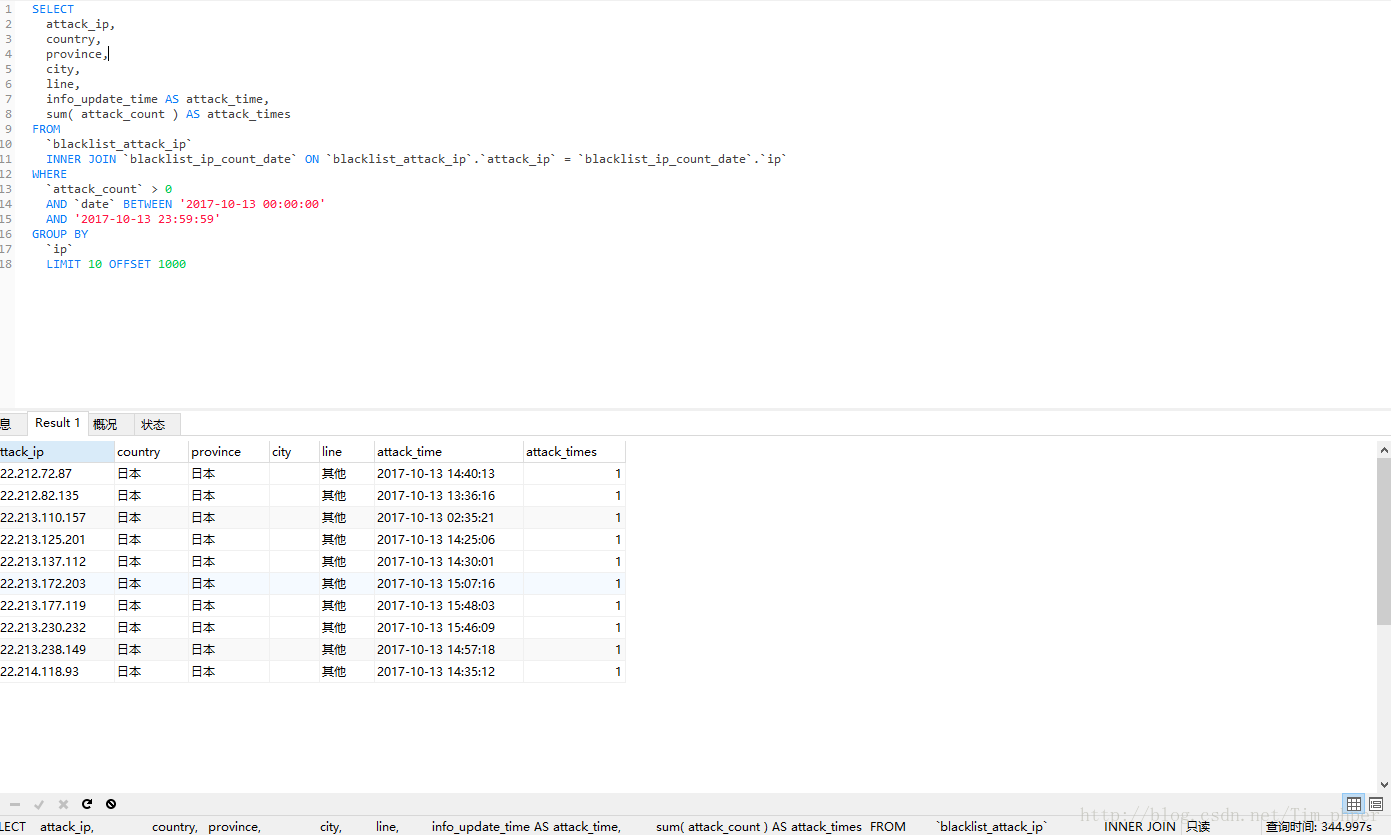
未优化前SQL语句为:
SELECT
attack_ip,
country,
province,
city,
line,
info_update_time AS attack_time,
sum( attack_count ) AS attack_times
FROM
`blacklist_attack_ip`
INNER JOIN `blacklist_ip_count_date` ON `blacklist_attack_ip`.`attack_ip` = `blacklist_ip_count_date`.`ip`
WHERE
`attack_count` > 0
AND `date` BETWEEN '2017-10-13 00:00:00'
AND '2017-10-13 23:59:59'
GROUP BY
`ip`
LIMIT 10 OFFSET 1000- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
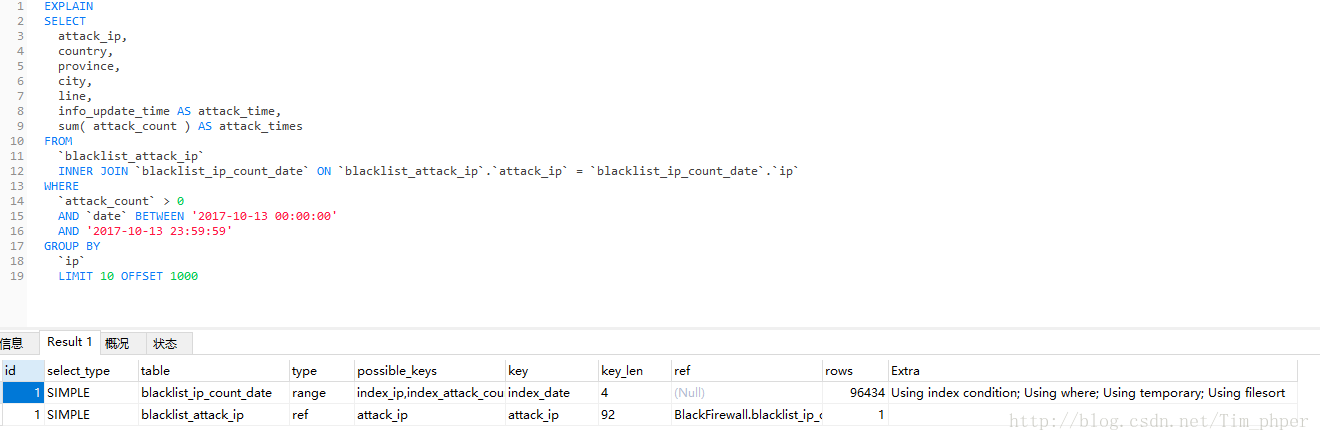
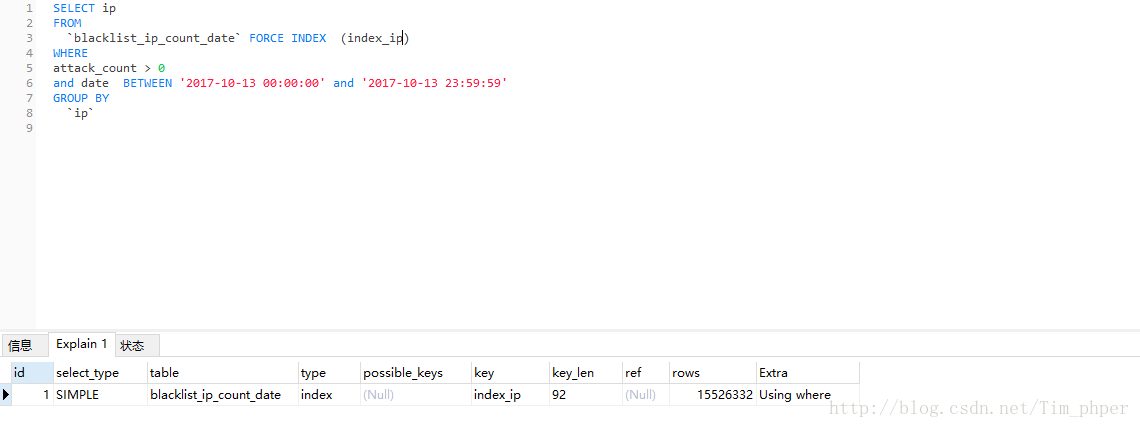
先EXPLAIN分析一下:
这里看到索引是有的,但是IP攻击次数表blacklist_ip_count_data也用上了临时表。那么这SQL不优化直接第一次执行需要多久(这里强调第一次是因为MYSQL带有缓存功能,执行过一次的同样SQL,第二次会快很多。)
实际查询时间为300+秒,这完全不能接受呀,这还是没有其他搜索条件下的。
那么我们怎么优化呢,索引既然走了,我尝试一下避免临时表,这时我们先了解一下临时表跟group by的使联系:
查找了网上一些博客分析GROUP BY 与临时表的关系 :
1. 如果GROUP BY 的列没有索引,产生临时表.
2. 如果GROUP BY时,SELECT的列不止GROUP BY列一个,并且GROUP BY的列不是主键 ,产生临时表.
3. 如果GROUP BY的列有索引,ORDER BY的列没索引.产生临时表.
4. 如果GROUP BY的列和ORDER BY的列不一样,即使都有索引也会产生临时表.
5. 如果GROUP BY或ORDER BY的列不是来自JOIN语句第一个表.会产生临时表.
6. 如果DISTINCT 和 ORDER BY的列没有索引,产生临时表.
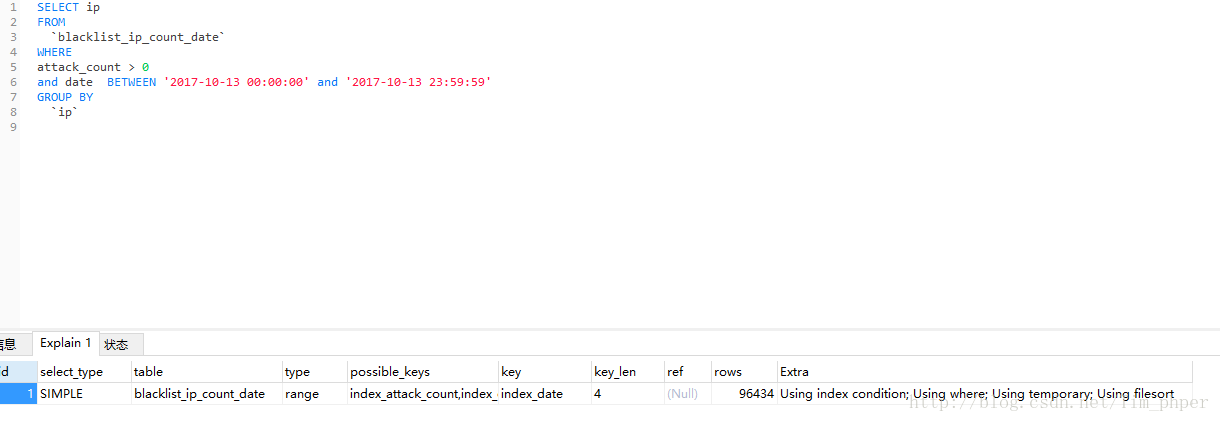
仔细按照上面分析一下,这SQL可能是因为第二条导致的,blacklist_ip_count_date这个表的确主键不是IP,SELECT是多列的,那么我们试试单独提出单表测试能不能避免临时表:
很遗憾,并不能避免,但是我们仔细看看这EXPLAIN 里面的KEY 分析,用的索引是date单字段的索引。这好像就是导致了第一条的问题了,相当于GROUP BY没有用索引。那么我们试试强制使用IP单字段的索引呢?
这里看来的确是索引的问题,导致了临时表啊,然而再看看ROWS的数量,原来的9W变成了1552W,这不是不是捡了芝麻掉了西瓜吗?
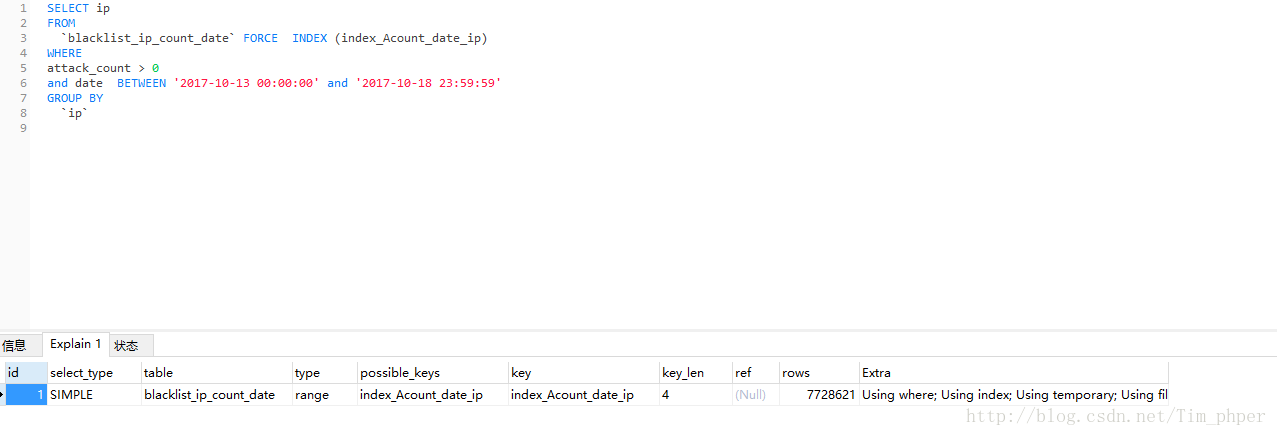
这里单列索引 避免了临时表可是联系的行数又增加了,那么我们再试试复合索引呢?
于是创建attack_count、date、ip的复合索引index_Acount_date_ip
ROWS的行数770W而且还是有临时表,看来这复合索引也是不可取。
到此,避免临时表方法失败了,我们得从其他角度想想如何优化。
其实,9W的临时表并不算多,那么为什么导致会这么久的查询呢?我们想想这没优化的SQL的执行过程是怎么样的呢?
网上搜索得知内联表查询一般的执行过程是:
1、执行FROM语句
2、执行ON过滤
3、添加外部行
4、执行where条件过滤
5、执行group by分组语句
6、执行having
7、select列表
8、执行distinct去重复数据
9、执行order by字句
10、执行limit字句- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
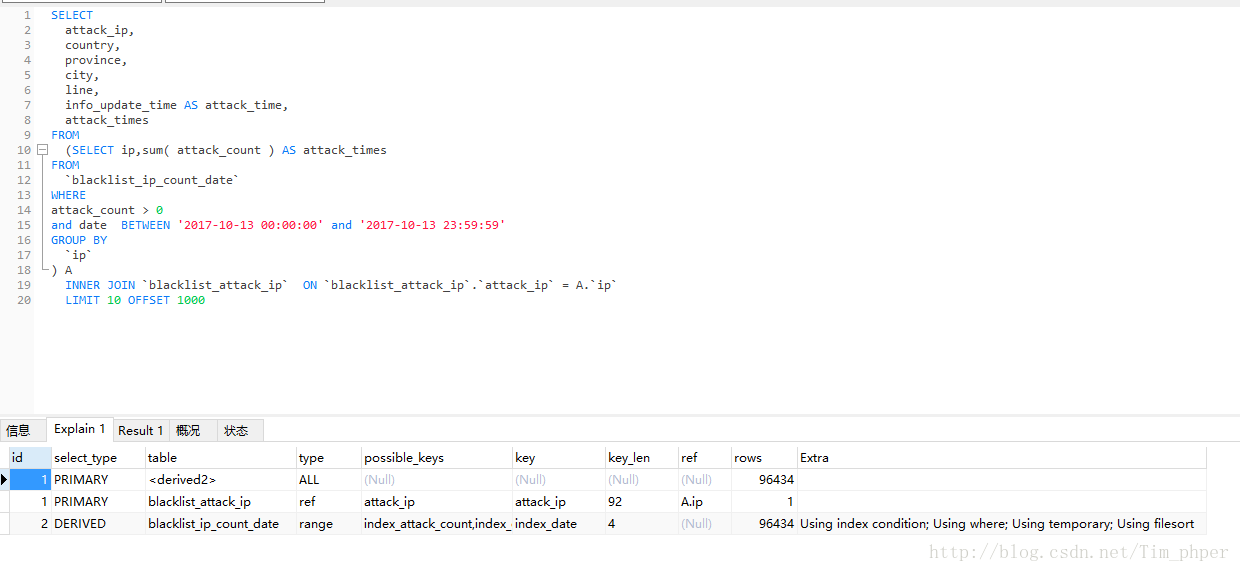
这里得知,Mysql 是先执行内联表然后再进行条件查询的最后再分组,那么想想这SQL的条件查询和分组都只是一个表的,内联后数据就变得臃肿了,这时候再进行条件查询和分组是否太吃亏了,我们可以尝试一下提前进行分组和条件查询,实现方法就是子查询联合内联查询。
这里EXPLAIN看来,只是多了子查询,ROWS和临时表都没有变化。那么我们看看实际的效果呢?
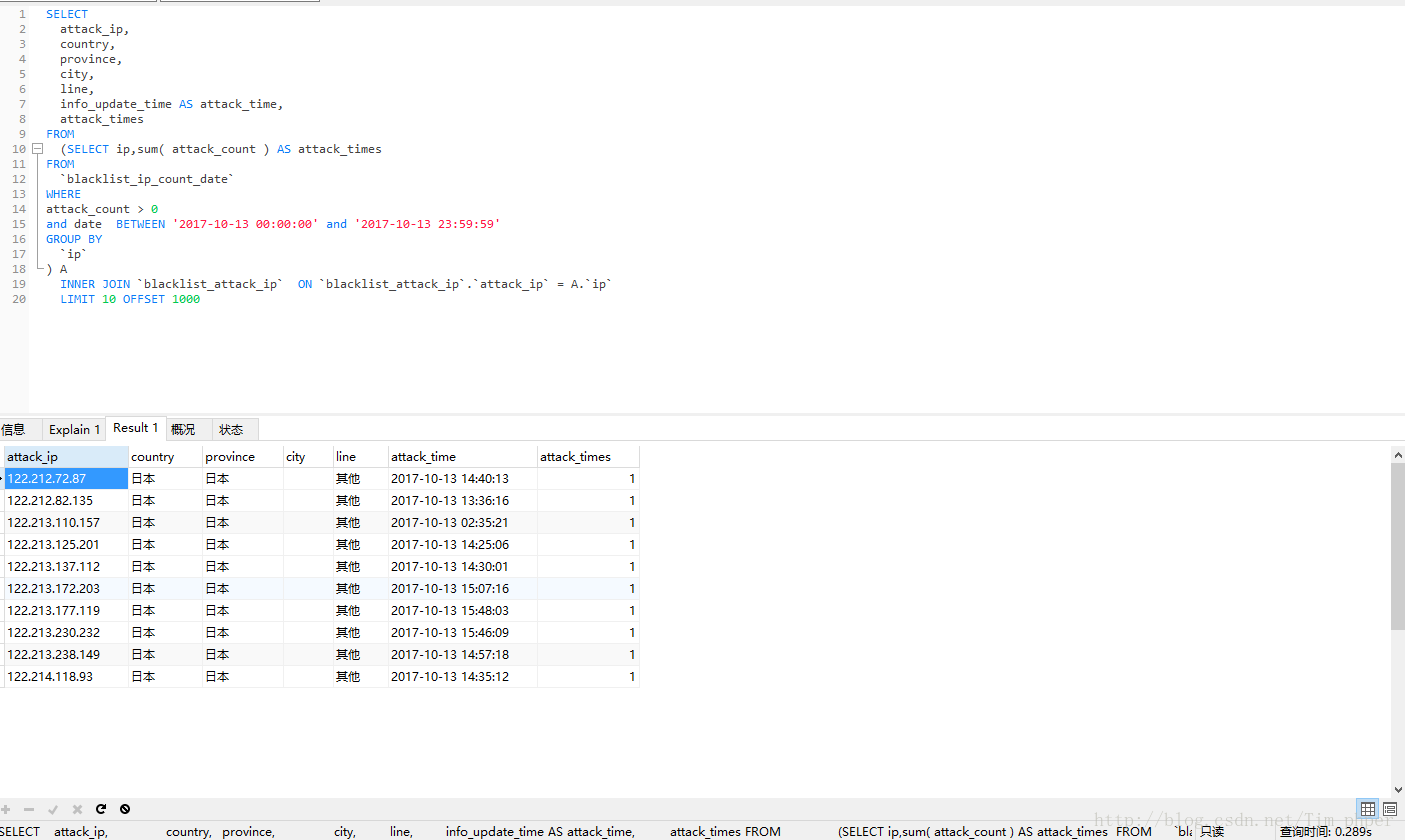
可见,取出来的数据完全一模一样,可是优化后效率从原来的330秒变成了0.28秒,这里足足提升了1000多倍的速度。这也基本满足了我们的优化需求。
估计到这里,你猜这里就是全部的优化方案?不不不,整个优化过程怎么可能只是发现一个优化方案。还有其他方案我会分开文章写,具体请查看我的下一篇文章MYSQL一次千万级连表查询优化(二)。
总结:
整个过程中我们得知,其实EXPLAIN有时候并不能指出你的SQL的所有问题,有一些隐藏问题必须要你自己思考,正如我们这个例子,看起来临时表是最大效率低的源头,但是实际上9W的临时表对MYSQL来说不足以挂齿的。我们进行内联查询前,最好能限制连的表大小的条件都先用上了,同时尽量让条件查询和分组执行的表尽量小。感谢您们的阅读,如果有更好的方案,欢迎留言交流!!!