什么是优先队列?
我们在常见的线性结构中,已经知道什么是普通队列了,普通队列就是一种“先进先出,后进后出”的数据结构,即普通队列的出队顺序和入队顺序是一样的,但我们的优先队列,它的出队顺序和入队顺序无关,它的出队顺序是和优先级相关的,当然这个优先级我们可以自己定义。
为什么使用优先队列?
举一个生活中的例子,就是医院里需要做手术的病人,医院不会根据哪个病人先来就先送去手术室,而是会根据病人生命危险的程度来决定应该谁先进入手术室。再说一个计算机中的例子,例如在操作系统中,进行任务的调度,在我们现在的操作系统中,会同时执行多个任务,操作系统需要为这个多个任务分配计算机资源,包括分配CPU时间片,具体去分配资源的时候,操作系统就要看各个任务的优先级,去动态的选择优先级最高的任务执行。注意动态这个关键词,如果我的任务数量是固定的,那么其实我们是不需要制造新的数据结构来处理这个问题,我们就只有这N个任务,那我们直接按照优先级排一个序,然后从高序到低序去执行就行了,这个过程我们需要的是一个排序算法,而不是一个优先队列。但是通常实际情况,我们是不知道要处理多少个任务的。就比如当我们的任务中心处理掉一个请求后,然后又来了很多新的请求,我们不能一开始就确定我们的任务处理中心要处理多少个请求,这就是动态的意思。
优先队列本质上也是一种队列,和我们在常见的线性结构中定义的队列接口是一样的,只不过在具体实现时有所不同。我们可以实现优先队列可以通过普通的线性结构来实现,既不管你是通过数组实现还是链表实现,你会发现在入队时的时间复杂度为O(1),但是在出队时的时间复杂度却为O(n),因为使用顺序结构实现的优先队列在进行出队操作时,我们需要先遍历这个这个优先队列,找到优先级最高的元素时再进行出队;当然我们也可以使用顺序线性结构实现优先队列,这样我们就可以在出队时让时间复杂度为O(1),但是在入队时,我们的时间复杂度就为O(n)了,因为我们每次在向优先队列中添加新元素时,都需要对优先队列中所有元素的优先级进行对比,然后添加到按优先级排序中的位置。有没什么办法让我们实现的优先队列的出队和入队操作效率都很高呢?这就是本文要讲的另外一种数据结构了,我们可以通过堆来实现优先队列,堆也是一种树结构。
| 实现方式 | 入队操作 | 出队操作 |
|---|---|---|
| 普通线性结构 | O(1) | O(n) |
| 顺序线性结构 | O(n) | O(1) |
| 堆 | O(logn) | O(logn) |
堆也是一种树,本文主要说的是二叉堆,二叉堆是一棵完全二叉树。什么是完全二叉树呢?完全二叉树就是把元素按照数的形状一层一层的放,直到放完为止,即把元素顺序排成树的形状。堆也是一棵平衡二叉树,因为完全二叉树一定是平衡二叉树,什么是平衡二叉树?即对于整棵树来说,最大深度和最小深度的差值不能大于1,因此平衡二叉树一定不会退化成链表。
二叉堆的性质:堆中某个节点的值总是不大于其父节点的值,本文讲的是最大堆,即根节点的值是最大的,相应地也可以定义最小堆。
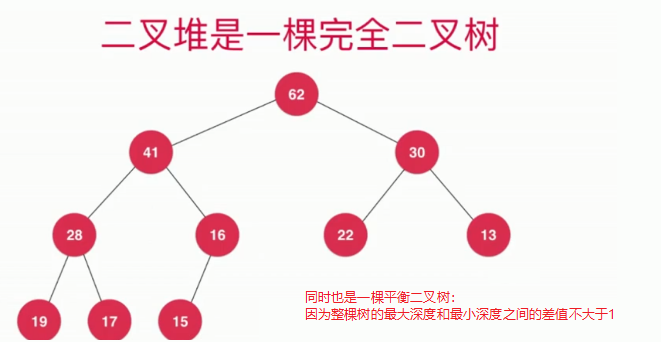
基于完全二叉树的性质,我们可以使用数组来存储二叉堆中的元素:
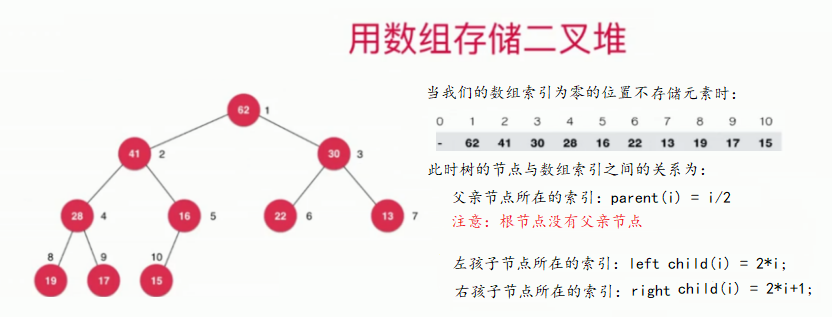
我们也可以在索引为零的位置存储二叉堆的根节点,不过此时当前节点的父亲节点、左孩子节点和右孩子节点的索引关系就会发生如下改变:

如何创建一个二叉最大堆?
当我们使用数组表示最大堆时,我们可以使用在常见的线性结构中自定义的动态数组,这样我们在向堆中添加和删除元素时,我们就可以动态地改变数组的容量,不需要考虑数组容量的问题了。
/**
* 基于二叉最大堆的性质:堆中某个节点的值总是不大于其父节点的值
* @param <E> 二叉最大堆中的元素必须要具有可比较性
*/
public class MaxHeap<E extends Comparable<E>> {
//使用的是我们的自定义动态数组
private Array<E> data;
//有参构造--用户指定堆的大小
public MaxHeap(int capacity){
data = new Array<E>(capacity);
}
//无参构造
public MaxHeap(){
//这里我们就使用动态数组的默认大小
data = new Array<E>();
}
//返回堆中元素的个数
public int getSize(){
return data.getSize();
}
//返回一个布尔值,判断堆是否为空
public boolean isEmpty(){
return data.isEmpty();
}
}
根据我们之前再说使用数组存储二叉堆时,二叉堆中的节点与数组中的索引的关系用具体代码表示,如下:
// 返回完全二叉树的数组表示中,一个索引所表示的元素的父亲节点的索引
private int parent(int index){
//如果为根节点,由于根节点没有父亲节点,则抛出异常
if(index == 0)
throw new IllegalArgumentException("index-0 doesn't have parent.");
return (index - 1) / 2;
}
// 返回完全二叉树的数组表示中,一个索引所表示的元素的左孩子节点的索引
private int leftChild(int index){
return index * 2 + 1;
}
// 返回完全二叉树的数组表示中,一个索引所表示的元素的右孩子节点的索引
private int rightChild(int index){
return index * 2 + 2;
}
如何向堆中添加元素?
当我们新添加的元素大于父亲节点时,就不满足二叉最大堆的性质,我们就需要交换这两个元素的位置,待添加元素与其父亲节点交换位置的过程就叫做上浮(Sift Up),如下图:
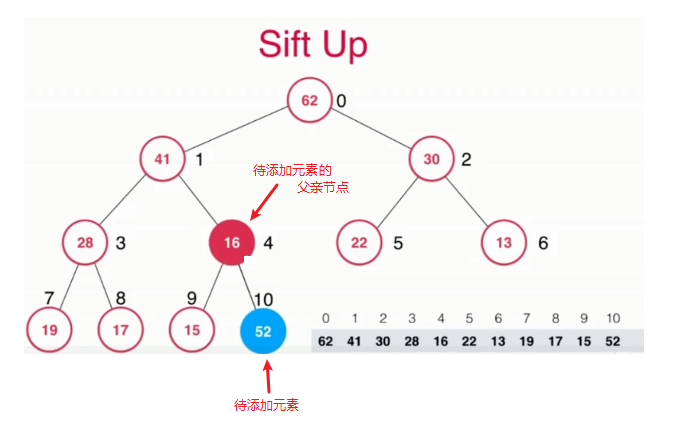
具体代码实现如下:
//向堆中添加元素
public void add(E e){
//把元素存储到动态数组中
data.addLast(e);
//data.getSize()-1 是待添加元素在动态数组中的索引
siftUp(data.getSize()-1);
}
private void siftUp(int index) {
//比较当前元素的父亲节点 data.get(parent(index)的值与带添加元素的值大小
//如果待添加元素的父亲节点的值小于带添加元素,则需要交换位置
while (index>0 && data.get(parent(index)).compareTo(data.get(index)) <0 ){
//在我们的动态数组中新增一个两个索引位置元素交换的方法
data.swap(index,parent(index));
//交换索引的值,进行下一轮循环比较
index = parent(index);
}
}
在我们的动态数组Array中新增一个两个索引位置元素交换的方法:
public void swap(int index, int parent) {
//判断索引合法性
if (index<0 || index>= size || parent<0 ||parent>=size){
throw new IllegalArgumentException("Index is illegal.");
}
//交换两个元素的位置
E t = data[index];
data[index] = data[parent];
data[parent] = t;
}
如何从堆中取出元素?
从堆中取出元素和sift down:取出队中最大的元素,因为我们只是取出堆顶的元素,即根节点,把根节点元素取出后,我们的堆就变成了两个子树,我们现在需要把堆中最后的一个元素放在堆顶,即作为二叉树的根节点,我们的数组也删除这个元素,但此时又不满足堆的性质了,我们就需要对根节点进行下沉(sift down),需要和他元素值最大的那个孩子互换位置。
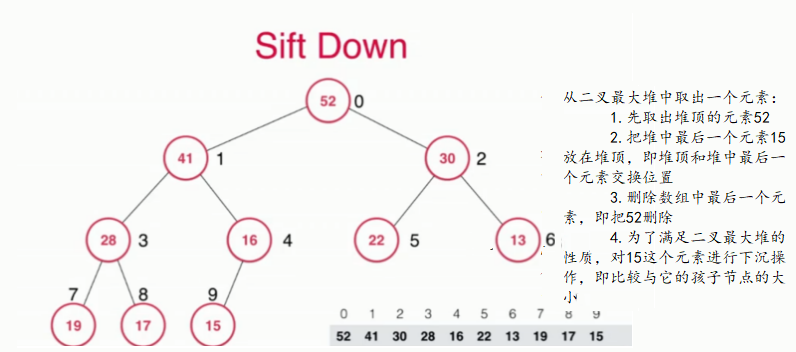
//取出堆中最大元素
public E extractMax(){
E res = findMax();
//交换最大元素和堆中最后一个元素的位置
data.swap(0,data.getSize()-1);
//删除堆中最后一个元素
data.removeLast();
siftDown(0);
return res;
}
private void siftDown(int index) {
//即判断左孩子节点不为空
while (leftChild(index) < data.getSize()){
//获取左孩子节点的索引
int childIndex = leftChild(index);
//childIndex+1 即为右孩子的索引
if (childIndex+1 < data.getSize() &&
//在右孩子不为空的情况下,比较右孩子和左孩子的大小
data.get(childIndex+1).compareTo(data.get(childIndex))> 0 ){
childIndex ++;//即data[childIndex] 是 leftChild 和 rightChild 中的最大值
}
if (data.get(index).compareTo(data.get(childIndex)) >= 0){
break;
}
data.swap(index,childIndex);
index = childIndex;
}
}
//二叉最大堆中最大的元素就是堆顶的元素,在数组中对应索引为零的元素
private E findMax() {
if(data.getSize() == 0)
throw new IllegalArgumentException("Can not findMax when heap is empty.");
return data.get(0);
}
下面就让我们来对于二叉堆的添加和删除操作进行测试,该测试代码实现了对数据的降序排序,测试代码如下:
public static void main(String[] args) {
int n = 1000000;
//测试自定义的最大堆
MaxHeap<Integer> maxHeap = new MaxHeap<Integer>();
Random random = new Random();
for(int i = 0 ; i < n ; i ++)
//向我们的最大堆中添加100万个随机整数
maxHeap.add(random.nextInt(Integer.MAX_VALUE));
int[] arr = new int[n];
for(int i = 0 ; i < n ; i ++)
//从最大堆中取出堆顶的元素,放入arr数组中
arr[i] = maxHeap.extractMax();
for(int i = 1 ; i < n ; i ++)
//如果arr数组的前一个元素的值小于后一个元素的值,则说明我们实现的二叉堆有问题
if(arr[i-1] < arr[i])
throw new IllegalArgumentException("Error");
System.out.println("Test MaxHeap completed.");
}
时间复杂度分析:由于我们的二叉堆是一颗完全二叉树,所以它的add()和extractMax()的时间复杂度都是O(log n)。
下面再让我们来看看二叉堆的其他操作:
replace:取出最大元素后,放入一个新的元素,即是替换的意思。
实现思路一:我们可以先extractMax(),然后在进行add(),两次O(log n)操作。
实现思路二:我们可以直接将堆顶元素替换以后Sift Down,一次O(log n)操作。
//replace:将堆顶元素替换以后Sift Down
public E replace(E e){
E maxValue = findMax();
data.set(0,e);
siftDown(0);
return maxValue;
}
Heapify:将任意数组整理成堆的形状
对于任意一个数组,我们可以先看成一个完全二叉树,从最后一个非叶子节点计算,倒着从后向前不断 地进行sift down(下层操作),直到第一个非叶子节点
如何获取最后一个非叶子节点的索引?就是最后一个节点的父亲节点,如果是从0开始索引,则最后一个非叶子节点的索引为(i-1)/2,如果是从1开始索引,则父节点索引为i/2。
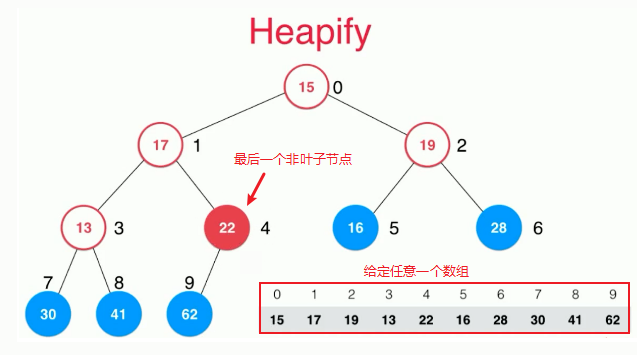
Heapify的算法复杂度:将n个元素逐个插入一个空堆中,时间复杂为O(nlogn),在进行heapify的过程,时间复杂度为O(n).
在heapify代码实现之前,我们需要在实现的动态数组中添加一个构造器,该构造器可以将传入的数组转为动态数组。
public Array(E[] arr){
data = (E[])new Object[arr.length];
for (int i=0; i<arr.length; i++){
data[i] = arr[i];
}
size = arr.length;
}
在我们的最大堆中实现Heapify操作:
//从第一个非叶子节点进行下沉操作,直到根节点
public MaxHeap(E[] arr){
data = new Array<E>(arr);
for (int i=parent(arr.length-1); i>=0; i--){
siftDown(i);
}
}
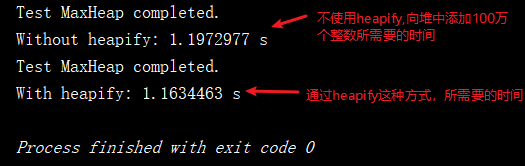
下面据让我们来对是否使用heapify进行测试:
private static double testHeap(Integer[] testData, boolean isHeapify){
long startTime = System.nanoTime();
MaxHeap<Integer> maxHeap;
if(isHeapify)
maxHeap = new MaxHeap<Integer>(testData);
else{
maxHeap = new MaxHeap<Integer>();
for(int num: testData)
maxHeap.add(num);
}
int[] arr = new int[testData.length];
for(int i = 0 ; i < testData.length ; i ++)
arr[i] = maxHeap.extractMax();
for(int i = 1 ; i < testData.length ; i ++)
if(arr[i-1] < arr[i])
throw new IllegalArgumentException("Error");
System.out.println("Test MaxHeap completed.");
long endTime = System.nanoTime();
return (endTime - startTime) / 1000000000.0;
}
public static void main(String[] args) {
int n = 1000000;
Random random = new Random();
Integer[] testData = new Integer[n];
for(int i = 0 ; i < n ; i ++)
testData[i] = random.nextInt(Integer.MAX_VALUE);
//不使用heapify
double time1 = testHeap(testData, false);
System.out.println("Without heapify: " + time1 + " s");
//使用heapify
double time2 = testHeap(testData, true);
System.out.println("With heapify: " + time2 + " s");
}
从测试代码的运行结果可以看出,对与100万个整数这种数据量来说,O(nlogn)和O(n)这两种时间复杂度所花费的时间差不多:
基于堆实现优先队列
这里是基于自定义的最大堆进行实现的优先队列,元素值越大,优先级越高,具体代码实现如下:
public class PriorityQueue<E extends Comparable<E>> implements Queue<E> {
private MaxHeap<E> maxHeap;
//无参构造 -- 初始化最大堆
public PriorityQueue() {
this.maxHeap = new MaxHeap<E>();
}
@Override
public int getSize() {
return maxHeap.getSize();
}
@Override
public boolean isEmpty() {
return maxHeap.isEmpty();
}
@Override
public void enqueue(E e) {
maxHeap.add(e);
}
//出队是优先级高的先出去,这里是元素值越大,优先级越高
@Override
public E dequeue() {
return maxHeap.extractMax();
}
@Override
public E getFront() {
return maxHeap.findMax();
}
}
优先队列的经典问题
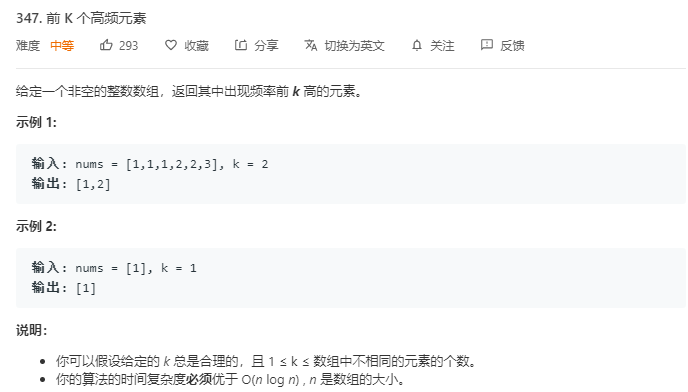
在100 0000个元素中选出前100名?这个问题相当于是在N个元素中选出前M个元素的一种特殊情况,我们来看下leetcode官网上的347号问题:题目描述如下图
现在让我们使用自己实现的优先队列列来解决的这个问题:
//定义我们优先队列的出队规则
private class Freq implements Comparable<Freq>{
//e代表元素 freq代表出现的频次
public int e, freq;
public Freq(int e, int freq){
this.e = e;
this.freq = freq;
}
@Override
public int compareTo(Freq another){
//频次高的先出队
if(this.freq < another.freq)
return 1;
else if(this.freq > another.freq)
return -1;
else
return 0;
}
}
public List<Integer> topKFrequent(int[] nums, int k) {
//使用map来存储这个数,以及这个数出现的频次
TreeMap<Integer,Integer> map = new TreeMap<Integer, Integer>();
for (int num : nums) {
//如果map中已经存在num,则对num的频次加一
if (map.containsKey(num)){
map.put(num,map.get(num) + 1);
}else {
map.put(num,1);
}
}
PriorityQueue<Freq> pq = new PriorityQueue<Freq>();
for (Integer key : map.keySet()) {
//若优先队列中的元素个数小于K
if (pq.getSize() < k){
pq.enqueue(new Freq(key,map.get(key)));
//否则进行频次比较,若当前元素的频次更高,则入队
//保证优先队列中的k个元素都是数组中出现次数最高的前K个
}else if(map.get(key) > pq.getFront().freq){
pq.dequeue();
pq.enqueue(new Freq(key, map.get(key)));
}
}
List<Integer> res = new LinkedList<Integer>();
while(!pq.isEmpty())
res.add(pq.dequeue().e);
return res;
}
我们也可以使用Java类库提供的优先队列来解决这个问题,需要注意的是,Java类库中提供的优先队列是基于最小堆实现的,如下:
public List<Integer> topKFrequent(int[] nums, int k) {
TreeMap<Integer, Integer> map = new TreeMap<>();
for(int num: nums){
if(map.containsKey(num))
map.put(num, map.get(num) + 1);
else
map.put(num, 1);
}
PriorityQueue<Integer> pq = new PriorityQueue<>(
//这里使用lambda表达式实现了优先队列的优先级规则
(a, b) -> map.get(a) - map.get(b)
);
for(int key: map.keySet()){
if(pq.size() < k)
pq.add(key);
else if(map.get(key) > map.get(pq.peek())){
pq.remove();
pq.add(key);
}
}
LinkedList<Integer> res = new LinkedList<>();
while(!pq.isEmpty())
res.add(pq.remove());
return res;
}