环境:
Hadoop1.x,CentOS6.5,三台虚拟机搭建的模拟分布式环境,gnuplot,
数据:http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html
方案目标:
提供的blog数据是简单的文件请求访问数据
205.189.154.54 - - [01/Jul/1995:00:00:29 -0400] "GET /shuttle/countdown/count.gif HTTP/1.0" 200 40310
每一行如上所示的规则。目标是计算每个文件的访问次数,以及访问次数的频率分布
思路:
这个目标其实非常容易实现。其中涉及的最大的一个知识点是关于job的依赖。在这个目标的解决方案中,可以使用两套MapReduce,前一个计算出每个文件的访问次数,后一个对频率进行统计,最后利用gnuplot工具绘制分布图形。
一、MapReduce程序
在这套程序中,MapReduce的编写很简单,就不写了。主要是主程序的框架写好就行了。
package ren.snail; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hdfs.util.EnumCounters.Map; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.TextInputFormat; import org.apache.hadoop.mapred.jobcontrol.JobControl; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat; import org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import com.sun.xml.internal.ws.api.model.wsdl.editable.EditableWSDLBoundFault; public class Main extends Configured implements Tool { public static void main(String[] args) throws Exception { int result = ToolRunner.run(new Configuration(), new Main(), args); } @Override public int run(String[] arg0) throws Exception { // TODO Auto-generated method stub Configuration configuration = getConf(); Job job1 = new Job(configuration, "groupby"); job1.setJarByClass(Main.class); FileInputFormat.addInputPath(job1, new Path(arg0[0])); FileOutputFormat.setOutputPath(job1, new Path(arg0[1])); job1.setMapperClass(GroupMapper.class); job1.setReducerClass(GroupReducer.class); job1.setOutputFormatClass(TextOutputFormat.class); job1.setOutputKeyClass(Text.class); job1.setOutputValueClass(IntWritable.class); Job job2 = new Job(configuration, "sort"); job2.setJarByClass(Main.class); FileInputFormat.addInputPath(job2, new Path(arg0[1] + "/part-r-00000")); FileOutputFormat.setOutputPath(job2, new Path(arg0[1]+"/out2")); job2.setMapperClass(SortMapper.class); job2.setReducerClass(SortReducer.class); job2.setInputFormatClass(KeyValueTextInputFormat.class); job2.setOutputFormatClass(TextOutputFormat.class); job2.setOutputKeyClass(IntWritable.class); //这里定义的输出格式是map输出到reduce的格式,不是reduce输出到HDFS的格式 job2.setOutputValueClass(IntWritable.class); ControlledJob controlledJob1 = new ControlledJob(job1.getConfiguration()); ControlledJob controlledJob2 = new ControlledJob(job2.getConfiguration()); controlledJob2.addDependingJob(controlledJob1); //job依赖,使得job2利用Job1产生的数据 JobControl jobControl = new JobControl("JobControlDemoGroup"); jobControl.addJob(controlledJob1); jobControl.addJob(controlledJob2); Thread jobControlThread = new Thread(jobControl); jobControlThread.start(); while (!jobControl.allFinished()) { Thread.sleep(500); } jobControl.stop(); return 0; } }
最后,我们得到了想要的数据,还有频率分布的数据。接下来使用gunplot来进行绘制
二、GnuPlot
gnuplot的安装很简单,采用 yum install gunplot就能安装。
安装好后,编写代码如下:
set terminal png set output "freqdist.png" //输出文件名 set title "Frequnecy Distribution of Hits by Url"; //绘制的图像名称 set ylabel "Number of Hits"; set xlabel "Urls (Sorted by hits)"; set key left top set log y set log x plot "~/test/data.txt" using 2 title "Frequency" with linespoints
可能出现问题:
Could not find/open font when opening font "arial", using internal non-scalable font
解决方案:
yum install wqy-zenhei-fonts.noarch #其实这个是安装字体,但是一般都已经安装了的
进入gnuplot的shell,输入set term png font "/usr/share/fonts/wqy-zenhei/wqy-zenhei.ttc" 10 #设置png图片的字体,可能会输出
Options are 'nocrop font /usr/share/fonts/wqy-zenhei/wqy-zenhei.ttc 12 ',不用管,在运行程序,其实你已经生成了你想要的图片
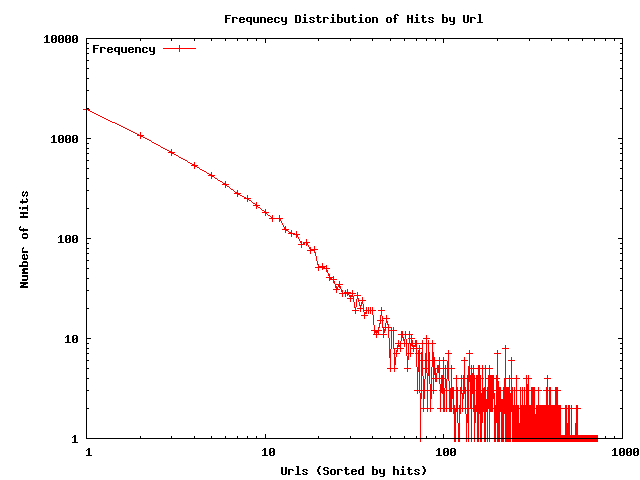
不仅可以画散点图,还可以有直方图折线图等等,主要是对plot程序的修改,就不在一一实验了