Python第一课>>>转到思维导图>>>转到我的博客
- 编程语言发展史
- 1.机器语言
- 直接用二进制跟计算机直接沟通交流,直接操作硬件
- 优点:计算机能够直接读懂,速度快
- 缺点:开发效率极低
- PS:站在奴隶的角度说奴隶能够听懂的话
- 2.汇编语言
- 用简单的英文标签来表示二进制数,直接操作硬件
- 优点:开发效率高于机器语言
- 缺点:执行效率较机器语言低
- 3.高级语言
- 站在奴隶主的角度说奴隶主的话
- 1.编译型(类似于谷歌翻译)
- 一次翻译之后,就可以拿着翻译之后的结果多次运行
- 编译的过程需要用到编译器
- 优点:执行效率高
- 缺点:开发效率低
- 2.解释型(类似于同声传译)
- 一行一行的翻译(读一行翻译一行)
- 解释的过程需要用到解释器
- 优点:开发效率高
- 缺点:执行效率低
- PS:
- 学习难度
- 执行效率
- 开发效率
- python是解释型语言
- Python
- 1.胶水语言
- 2.调包侠
- python解释器,环境变量配置,多版本共存
- 在IT行业不要贸然尝试用最新版本的软件!!!
- 第一个Python程序
- 两种运行python程序的方式
- 1.交互式
- 优点:输入内容立刻就有对应的返回结果
- 缺点:无法永久保存数据
- 2.命令行(文件形式)
- 优点:可以永久保存数据
- 缺点:暂时来看运行该文件有点麻烦
- PS:文件后缀名
- 仅仅是给人看的
- 你所认为的不同的文件后缀有不同的功能那是程序员自己写的
- python文件默认的后缀名就是.py结尾
- 运行一个py文件需要走的步骤(*****)
- 1.将python解释器代码从硬盘督导内存
- 2.将你写好的py文件由应哦按读到内存
- 3.解释器解释读取py文件中的内容,解释成计算机能够识别的语句
- (如果是一个普通文本文件,仅仅只会将文件内容展示到屏幕上给用户查看,不会检测翻译文件内容)
- PS:
- Pyhon解释器与普通文本编辑器前面两步是一毛一样的,仅仅第三步不一样(一个是解释语法,一个是文本展示)
- IDE开发编辑器
- pycharm仅仅是一个方便我们开发程序的工具而已
- 变量
- 1.什么是变量
- 量:衡量/记录事物的状态/特征
- 变:状态/特征是可以变化的
- 2.为什么要有变量?
- 3.变量的定义
- 1.只能包含数字,字母,下划线
- 2.数字不能开头
- 3.关键字不能作为变量名
- 变量必须先定义后调用(使用),变量名不要加引号
- 4.变量额三要素
- 1. id():返回的是一串数字
- 2. type():返回的是该变量对应的主句的类型
- 3. value:该变量指向的内存当中数据的值
- 5.通常变量名的命名有两个流派
- 驼峰体(前端语言js推荐的命名方式)
- 下划线(python推荐的命名方式)
- 注意:变量名一定要起的有意义(见名知意),千万不要用中文
- 6.小整数池()
- Python实现int的时候有个小整数池。为了避免因创建相同的值而重复申请内存空间所带来的效率问题, Python解释器会在启动时创建出小整数池,范围是[-5,256],该范围内的小整数对象是全局解释器范围内被重复使用,永远不会被GC回收
-
>>> a = 257
>>> b = 257
>>> id(a)
2919979319120
>>> id(b)
2919979576208
>>> c = 256
>>> d = 256
>>> id(c)
1642892736
>>> id(d)
1642892736
- 垃圾回收机制
- 1.引用计数:
- 内存中的数据如果没有任何变量名与其有绑定关系,那么会被自动回收
- 2.标记清除:
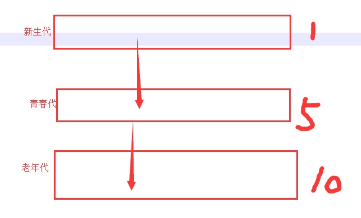
- 3.分代回收;
- 根据值得存活时间的不同,化为不同的等级,等级越高垃圾回收机制扫描的频率越低
- 常亮(不可变的量)
- python里面压根没有常量
- 通常将全大写的变量名看做常量(python程序员约定俗成的)