一、监控指标
成熟稳健的系统往往需要对集群运行时的各个指标进行收集,如系统的load、CPU的利用率、I/O繁忙程度、网络traffic、内存利用率、应用心跳等。
1、load
系统的load被定义为特定时间间隔内运行队列中的平均线程数,每一个CPU的核都维护了一个运行队列。
一般每个CPU当前的活动线程数不大于3,视为正常;大于5表示系统负载非常高了。
命令:top、uptime
2、CPU利用率
在linux系统下,CPU的时间消耗主要在这几个方面,即用户进程、内核进程、中断处理、I/O等待、Nice时间、丢失时间、空闲等几个部分,而CPU的利用率则为这些时间所占总时间的百分比。
us(User Time)用户时间,表示CPU执行用户进程所占用的时间;
sy(System Time)系统时间,表示CPU在内核态所花费的时间;
ni(Nice Time)调整优先级时间,表示CPU在调整进程优先级的时候花费的时间;
id(Idle Time)空闲时间,表示系统处于空闲期,等待进程运行,这个过程所占用的时间;
wa(Waiting Time)等待时间,表示CPU在等待I/O操作所花费的时间;
hi(Hard Irq Time)硬件中断时间,表示系统处理硬件中断所占用的时间;
si(Soft Irq Time)软件中断时间,表示系统处理软件中断所占用的时间;
st(Steal Time)丢失时间,表示当前虚拟机与该宿主上的其他虚拟机间的CPU争用时间;
命令: top + 1、 jps + top -p x
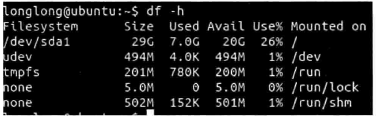
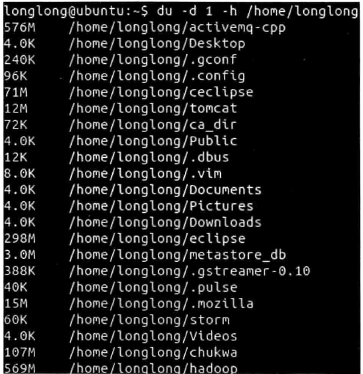
3、磁盘剩余空间
du -d1 -h /home
-d 指定递归深度,-h按照文件大小单位的格式化输出
4、网络traffic
sar -n DEV 1 1
-n 表示汇报网络状况,DEV查看各个网卡的网络流量,第一个1表示每秒抽样一次,第二个1表示总共取一次,
Average表示平均值。

5、磁盘I/O
iostat -d -k
-d 表示查看磁盘的使用情况, -k表示以KB为单位显示;

6、内存的使用
free -m
linux的内核会将剩余的内存申请为cached,而cached不属于free范畴,用于分配给程序的内存不仅仅只有free,还包括buffers和cached占用的内存;
对于应用来说,更值得关注的应该是虚拟内存swap的消耗,swap内存使用过多,表示物理内存不够用,操作系统将
本应该是物理内存的一部分内存页调度到磁盘上。swap I/O较为频繁,会严重影响系统的性能。
vmstat 可以查看到swap I/O情况
7、qps
query per second,即每秒查询数。qps在很大程度上代表了系统在业务上的繁忙程度,而每次请求的背后,可能对应着多次磁盘I/O、所赐网络请求,以及多个CPU时间片。
8、rt
response time 直接关系前端的用户体验。降低rt时间需要从各个方面入手,例如:部署CDN边缘节点来缩短用户请求的物理路径;通过内容压缩来减少传输的字节数;使用缓存来减少磁盘I/O和网络请求等。
CPU、内存、网络、磁盘、qps和rt,是所有类型的应用都需要关注;如select/ps、update/ps只针对数据库应用,thread running值针对MySql数据库应用,FullGC只针对Java应用。
9、select/ps
请求数量过多,则可以适当的增加读库,以降低系统读的压力;
10、update/ps、delete/ps
请求数量过多,则可以对相应的库进行拆分,将请求分散到其他集群;
11、GC
当GC发生时,JVM上的应用程序的工作线程会暂时停止运行,从外部来看便是程序暂时停止响应。可应对JVm的一些内存参数进行调整和优化,以降低GC时应用停止响应的时间。
二、心跳检测
对于自治的分布式系统而言,一般都会有一整套的集群心跳监测机制,能够实时地移除掉宕机的Slave,避免路由规则将任务分配给已宕机的机器来处理;
1、ping
ping指令能够检测网络链路是否畅通,远端主机是否能够到达;
2、应用层检测
使用应用层的心跳检测来对应用的健康状态进行监控,通过curl指令定时访问应用中的自检url,课实时地感知到应用的健康状态,一旦系统无响应或者响应超时,即可输出报警信息,以被相应的监控调度系统捕捉到,第一时间通知开发和运维人员进行处理;
3、业务检测
对于web程序,自动检测页面的异常情况;
3.1 通过页面大小的变动范围来判断页面是否出现异常,但是受大的改版影响比较大;
3.2 检测页面的返回值,但是这样检测跟具体的业务挂钩,或者对业务的代码具有一定的侵入性;
三、容量评估及应用水位
在新系统上线之前,或者需要在已在线的系统上做一些推广活动时,相关的业务方需要对系统的访问量进行评估;
1、业务方需要给出总的访问量(PV、UV)以后,推导到每个独立的子系统;
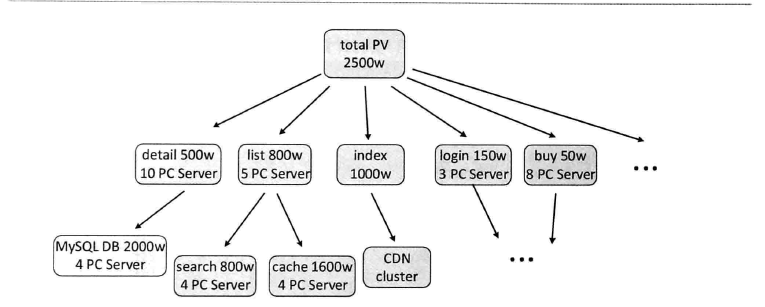
2、取其中的一个最小子集来进行压力测试,以便得出每个单元所能承载的访问量;
测试机器的配置需要与线上的机器保持一致,主要关心两个值qps、rt,当rt达到无法忍受的上限时,或者系统某些地方开始出现瓶颈,如内存不足,系统频繁Full GC,I/O等待时间过长,CPU load超高,这个时候的qps便是一个单元能够承受的极限值;
3、对系统进行评估出需要的机器数;
使用80/20原则,80%的访问请求将在20%的时间内到达,这样便可以根据系统对应的PV计算出系统的峰值qps
峰值qps=(总的PV*80%)/(60*60*24*20%)
机器数 = 总的峰值qps / 压测得出的单台机器极限qps
4、系统上线或者正在承受比较大压力时,通过当前的运行水位图来了解当前系统的压力;
通过访问日志分析,或者其他的统计手段,实时计算出当前系统的qps值(前1~2分钟的平均值),然后结合系统上线之前压测得到的单台机器的极限qps,乘以当前部署的机器总数,便能得到当前的水位:
当前水位 = 当前总qps / (单台机器极限qps*机器数) * 100%