一、Prometheus概述:
Prometheus是一个开源系统监测和警报工具箱。 Prometheus Operator 是 CoreOS 开发的基于 Prometheus 的 Kubernetes 监控方案,也可能是目前功能最全面的开源方案。
主要特征:
1)多维数据模型(时间序列由metri和key/value定义)
2)灵活的查询语言
3)不依赖分布式存储
4)采用 http 协议,使用 pull 拉取数据
5)可以通过push gateway进行时序列数据推送
6)可通过服务发现或静态配置发现目标
7)多种可视化图表及仪表盘支持
Prometheus架构如下:

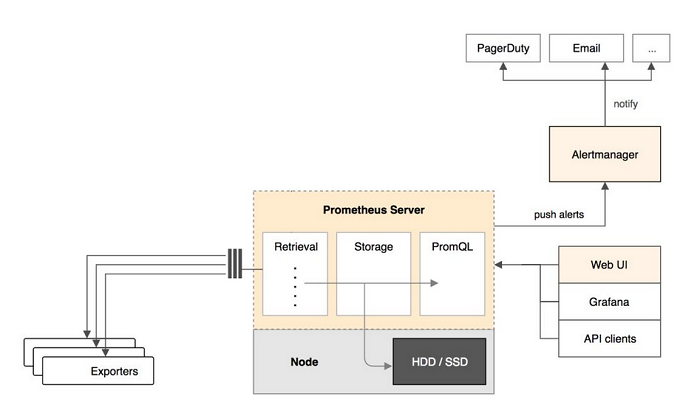
Prometheus组件包括:Prometheus server、push gateway 、alertmanager、Web UI等。
Prometheus server 定期从数据源拉取数据,然后将数据持久化到磁盘。Prometheus 可以配置 rules,然后定时查询数据,当条件触发的时候,会将 alert 推送到配置的 Alertmanager。Alertmanager 收到警告的时候,可以根据配置,聚合并记录新时间序列,或者生成警报。同时还可以使用其他 API 或者 Grafana 来将收集到的数据进行可视化。
Prometheus Server
Prometheus Server 负责从 Exporter 拉取和存储监控数据,并提供一套灵活的查询语言(PromQL)供用户使用。
Exporter
Exporter 负责收集目标对象(host, container…)的性能数据,并通过 HTTP 接口供 Prometheus Server 获取。
可视化组件
监控数据的可视化展现对于监控方案至关重要。以前 Prometheus 自己开发了一套工具,不过后来废弃了,因为开源社区出现了更为优秀的产品 Grafana。Grafana 能够与 Prometheus 无缝集成,提供完美的数据展示能力。
Alertmanager
用户可以定义基于监控数据的告警规则,规则会触发告警。一旦 Alermanager 收到告警,会通过预定义的方式发出告警通知。支持的方式包括 Email、PagerDuty、Webhook 等。
二、Prometheus Operator 架构
Prometheus Operator 的目标是尽可能简化在 Kubernetes 中部署和维护 Prometheus 的工作。其架构如下图所示:
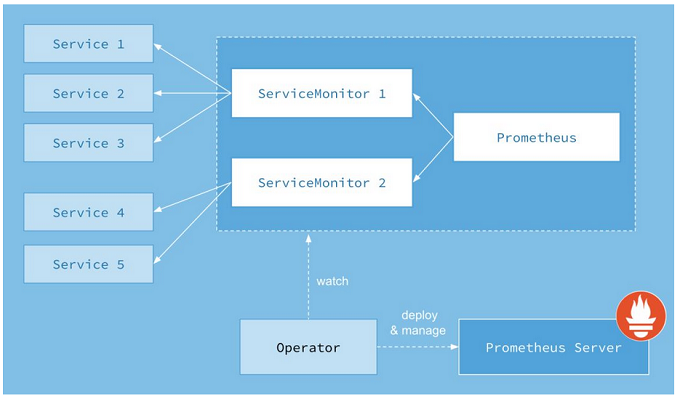
图上的每一个对象都是 Kubernetes 中运行的资源。
Operator
Operator 即 Prometheus Operator,在 Kubernetes 中以 Deployment 运行。其职责是部署和管理 Prometheus Server,根据 ServiceMonitor 动态更新 Prometheus Server 的监控对象。
Prometheus Server
Prometheus Server 会作为 Kubernetes 应用部署到集群中。为了更好地在 Kubernetes 中管理 Prometheus,CoreOS 的开发人员专门定义了一个命名为 Prometheus 类型的 Kubernetes 定制化资源。我们可以把 Prometheus看作是一种特殊的 Deployment,它的用途就是专门部署 Prometheus Server。
Service
这里的 Service 就是 Cluster 中的 Service 资源,也是 Prometheus 要监控的对象,在 Prometheus 中叫做 Target。每个监控对象都有一个对应的 Service。比如要监控 Kubernetes Scheduler,就得有一个与 Scheduler 对应的 Service。当然,Kubernetes 集群默认是没有这个 Service 的,Prometheus Operator 会负责创建。
ServiceMonitor
Operator 能够动态更新 Prometheus 的 Target 列表,ServiceMonitor 就是 Target 的抽象。比如想监控 Kubernetes Scheduler,用户可以创建一个与 Scheduler Service 相映射的 ServiceMonitor 对象。Operator 则会发现这个新的 ServiceMonitor,并将 Scheduler 的 Target 添加到 Prometheus 的监控列表中。
ServiceMonitor 也是 Prometheus Operator 专门开发的一种 Kubernetes 定制化资源类型。
Alertmanager
除了 Prometheus 和 ServiceMonitor,Alertmanager 是 Operator 开发的第三种 Kubernetes 定制化资源。我们可以把 Alertmanager 看作是一种特殊的 Deployment,它的用途就是专门部署 Alertmanager 组件。
三、安装Prometheus Operator
Prometheus Operator简化了在 Kubernetes 上部署并管理和运行 Prometheus 和 Alertmanager 集群。
1、all-kubernetes-cluster-node load images:

2、在部署节点执行如下:
(1)、装备 prometheus-operator 安装包并运行服务:
wget https://codeload.github.com/coreos/prometheus-operator/tar.gz/v0.18.0 -O prometheus-operator-0.18.0.tar.gz tar -zxvf prometheus-operator-0.18.0.tar.gz cd prometheus-operator-0.18.0 kubectl apply -f bundle.yaml clusterrolebinding "prometheus-operator" configured clusterrole "prometheus-operator" configured serviceaccount "prometheus-operator" created deployment "prometheus-operator" created
(2)、在master节点,创建etcd endpoint:
export NODE_IPS="192.168.210.161 192.168.210.162 192.168.210.163" for ip in ${NODE_IPS};do ETCDCTL_API=3 etcdctl --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/etcd/ssl/etcd.pem --key=/etc/etcd/ssl/etcd-key.pem endpoint health;done
(3)、回到部署节点,创建prometheus-operator
cd contrib/kube-prometheus
hack/cluster-monitoring/deploy
#移除:
hack/cluster-monitoring/teardown
namespace "monitoring" created clusterrolebinding "prometheus-operator" created clusterrole "prometheus-operator" created serviceaccount "prometheus-operator" created service "prometheus-operator" created deployment "prometheus-operator" created Waiting for Operator to register custom resource definitions...done! clusterrolebinding "node-exporter" created clusterrole "node-exporter" created daemonset "node-exporter" created serviceaccount "node-exporter" created service "node-exporter" created clusterrolebinding "kube-state-metrics" created clusterrole "kube-state-metrics" created deployment "kube-state-metrics" created rolebinding "kube-state-metrics" created role "kube-state-metrics-resizer" created serviceaccount "kube-state-metrics" created service "kube-state-metrics" created secret "grafana-credentials" created secret "grafana-credentials" created configmap "grafana-dashboard-definitions-0" created configmap "grafana-dashboards" created configmap "grafana-datasources" created deployment "grafana" created service "grafana" created configmap "prometheus-k8s-rules" created serviceaccount "prometheus-k8s" created servicemonitor "alertmanager" created servicemonitor "kube-apiserver" created servicemonitor "kube-controller-manager" created servicemonitor "kube-scheduler" created servicemonitor "kube-state-metrics" created servicemonitor "kubelet" created servicemonitor "node-exporter" created servicemonitor "prometheus-operator" created servicemonitor "prometheus" created service "prometheus-k8s" created prometheus "k8s" created role "prometheus-k8s" created role "prometheus-k8s" created role "prometheus-k8s" created clusterrole "prometheus-k8s" created rolebinding "prometheus-k8s" created rolebinding "prometheus-k8s" created rolebinding "prometheus-k8s" created clusterrolebinding "prometheus-k8s" created secret "alertmanager-main" created service "alertmanager-main" created alertmanager "main" created
kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE alertmanager-main-0 2/2 Running 0 15h alertmanager-main-1 2/2 Running 0 15h alertmanager-main-2 2/2 Running 0 15h grafana-567fcdf7b7-44ldd 1/1 Running 0 15h kube-state-metrics-76b4dc5ffb-2vbh9 4/4 Running 0 15h node-exporter-9wm8c 2/2 Running 0 15h node-exporter-kf6mq 2/2 Running 0 15h node-exporter-xtm4r 2/2 Running 0 15h prometheus-k8s-0 2/2 Running 0 15h prometheus-k8s-1 2/2 Running 0 15h prometheus-operator-7466f6887f-9nsk8 1/1 Running 0 15h
kubectl -n monitoring get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE alertmanager-main NodePort 10.244.69.39 <none> 9093:30903/TCP 15h alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 15h grafana NodePort 10.244.86.54 <none> 3000:30902/TCP 15h kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 15h node-exporter ClusterIP None <none> 9100/TCP 15h prometheus-k8s NodePort 10.244.226.104 <none> 9090:30900/TCP 15h prometheus-operated ClusterIP None <none> 9090/TCP 15h prometheus-operator ClusterIP 10.244.9.203 <none> 8080/TCP 15h
kubectl -n monitoring get endpoints
NAME ENDPOINTS AGE alertmanager-main 10.244.2.10:9093,10.244.35.4:9093,10.244.91.5:9093 15h alertmanager-operated 10.244.2.10:9093,10.244.35.4:9093,10.244.91.5:9093 + 3 more... 15h grafana 10.244.2.8:3000 15h kube-state-metrics 10.244.2.9:9443,10.244.2.9:8443 15h node-exporter 192.168.100.102:9100,192.168.100.103:9100,192.168.100.105:9100 15h prometheus-k8s 10.244.2.11:9090,10.244.35.5:9090 15h prometheus-operated 10.244.2.11:9090,10.244.35.5:9090 15h prometheus-operator 10.244.35.3:8080 15h
kubectl -n monitoring get servicemonitors
NAME AGE alertmanager 15h kube-apiserver 15h kube-controller-manager 15h kube-scheduler 15h kube-state-metrics 15h kubelet 15h node-exporter 15h prometheus 15h prometheus-operator 15h
kubectl get customresourcedefinitions
NAME AGE
alertmanagers.monitoring.coreos.com 11d
prometheuses.monitoring.coreos.com 11d
servicemonitors.monitoring.coreos.com 11d
注:在部署过程中我将镜像地址都更改为从本地镜像仓库进行拉取,但是有pod依然会从远端拉取镜像,如下
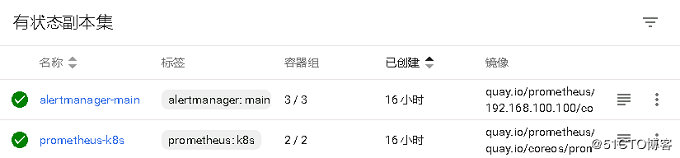
这里我是无法拉取alertmanager的镜像,解决方法就是先将该镜像拉取到本地,然后打包分发至各节点:
# docker save 23744b2d645c -o alertmanager-v0.14.0.tar.gz # ansible node -m copy -a 'src=alertmanager-v0.14.0.tar.gz dest=/root' # ansible node -a 'docker load -i /root/alertmanager-v0.14.0.tar.gz' 192.168.100.104 | SUCCESS | rc=0 >> Loaded image ID: sha256:23744b2d645c0574015adfba4a90283b79251aee3169dbe67f335d8465a8a63f 192.168.100.103 | SUCCESS | rc=0 >> Loaded image ID: sha256:23744b2d645c0574015adfba4a90283b79251aee3169dbe67f335d8465a8a63f # ansible node -a 'docker images quay.io/prometheus/alertmanager' 192.168.100.103 | SUCCESS | rc=0 >> REPOSITORY TAG IMAGE ID CREATED SIZE quay.io/prometheus/alertmanager v0.14.0 23744b2d645c 7 weeks ago 31.9MB 192.168.100.104 | SUCCESS | rc=0 >> REPOSITORY TAG IMAGE ID CREATED SIZE quay.io/prometheus/alertmanager v0.14.0 23744b2d645c 7 weeks ago 31.9MB
四、添加 etcd 监控
Prometheus Operator有 etcd 仪表盘,但是需要额外的配置才能完全监控显示。官方文档:Monitoring external etcd
1、master节点上执行,在 namespace 中创建secrets
# kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/kubernetes/ssl/ca.pem --from-file=/etc/etcd/ssl/etcd.pem --from-file=/etc/etcd/ssl/etcd-key.pem secret "etcd-certs" created # kubectl -n monitoring get secrets etcd-certs NAME TYPE DATA AGE etcd-certs Opaque 3 16h
注:这里的证书是在部署 etcd 集群时创建,请更改为自己证书存放的路径。
2、使Prometheus Operator接入secret
# vim manifests/prometheus/prometheus-k8s.yaml apiVersion: monitoring.coreos.com/v1 kind: Prometheus metadata: name: k8s labels: prometheus: k8s spec: replicas: 2 secrets: - etcd-certs version: v2.2.1
sed -i '/replicas:/a secrets: - etcd-certs' manifests/prometheus/prometheus-k8s.yaml kubectl -n monitoring replace -f manifests/prometheus/prometheus-k8s.yaml prometheus "k8s" replaced
注:这里只需加入如下项即可:
secrets: - etcd-certs
3、创建Service、Endpoints和ServiceMonitor服务
# vim manifests/prometheus/prometheus-etcd.yaml apiVersion: v1 kind: Service metadata: name: etcd-k8s labels: k8s-app: etcd spec: type: ClusterIP clusterIP: None ports: - name: api port: 2379 protocol: TCP --- apiVersion: v1 kind: Endpoints metadata: name: etcd-k8s labels: k8s-app: etcd subsets: - addresses: - ip: 192.168.210.161 nodeName: 192.168.210.161 - ip: 192.168.210.162 nodeName: 192.168.210.162 - ip: 192.168.210.163 nodeName: 192.168.210.163 ports: - name: api port: 2379 protocol: TCP --- apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: etcd-k8s labels: k8s-app: etcd-k8s spec: jobLabel: k8s-app endpoints: - port: api interval: 30s scheme: https tlsConfig: caFile: /etc/prometheus/secrets/etcd-certs/ca.pem certFile: /etc/prometheus/secrets/etcd-certs/etcd.pem keyFile: /etc/prometheus/secrets/etcd-certs/etcd-key.pem #use insecureSkipVerify only if you cannot use a Subject Alternative Name insecureSkipVerify: true selector: matchLabels: k8s-app: etcd namespaceSelector: matchNames: - monitoring
# kubectl create -f manifests/prometheus/prometheus-etcd.yaml
注1:请将 etcd 的ip地址和 etcd 的节点名更改为自行配置的ip和节点名。
注2:在 tlsconfig 下边的三项只需更改最后的ca.pem、etcd.pem、etcd-key.pem为自己相应的证书名即可。如实在不了解,可登陆进 prometheus-k8s 的pod进行查看:
# kubectl exec -ti -n monitoring prometheus-k8s-0 /bin/sh Defaulting container name to prometheus. Use 'kubectl describe pod/prometheus-k8s-0 -n monitoring' to see all of the containers in this pod. /prometheus $ ls /etc/prometheus/secrets/etcd-certs/ ca.pem etcd-key.pem etcd.pem
五、登陆监控平台参看
Prometheus Operator 部署完成后会对外暴露三个端口:30900为Prometheus端口、30902为grafana端口、30903为alertmanager端口。
Prometheus显示如下,如何一切正常,所有target都应该是up的。

Alertmanager显示如下:

kubectl get pod -n monitoring kubectl get svc -n monitoring kubectl -n monitoring get endpoints kubectl -n monitoring get servicemonitors kubectl get customresourcedefinitions
Grafana 是通过 Dashboard 展示数据的,在 Dashboard 中需要定义:
1)展示 Prometheus 的哪些多维数据?需要给出具体的查询语言表达式。
2)用什么形式展示,比如二维线性图,仪表图,各种坐标的含义等。
可见,要做出一个 Dashboard 也不是件容易的事情。幸运的是,我们可以借助开源社区的力量,直接使用现成的 Dashboard。
访问 https://grafana.com/dashboards?dataSource=prometheus&search=docker,将会看到很多用于监控 Docker 的 Dashboard。
Grafana的监控项显示如下
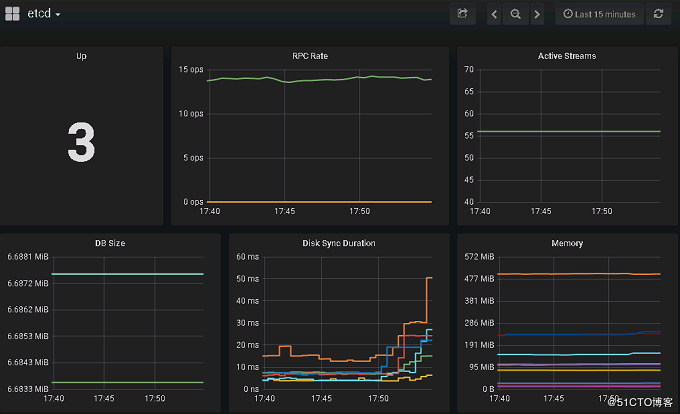
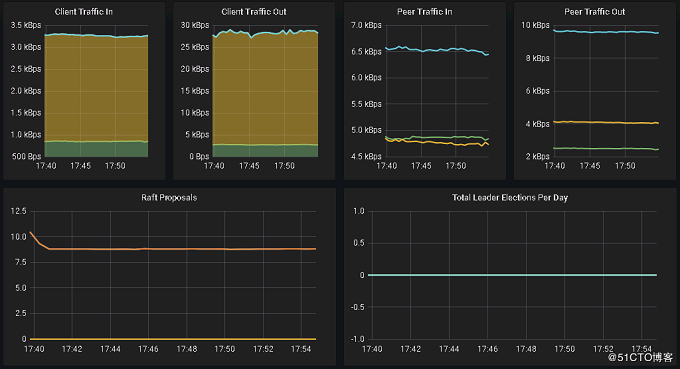
etcd相关监控项显示如下
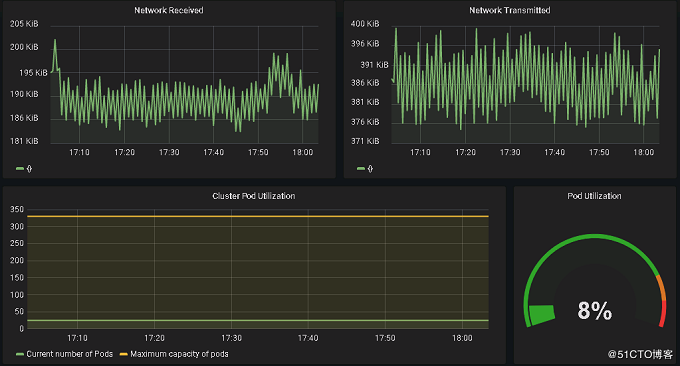
kubernetes集群显示如下

节点监控显示如下
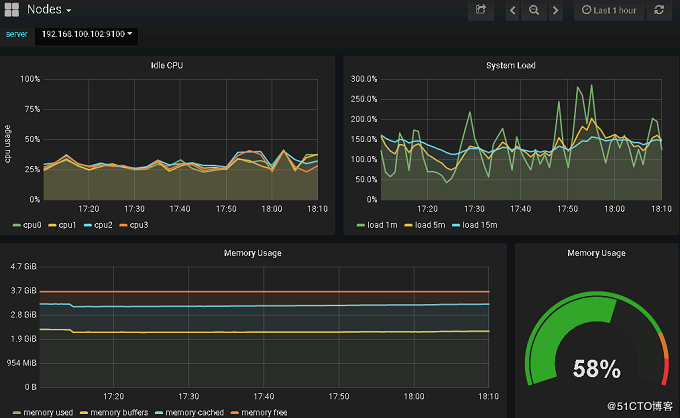
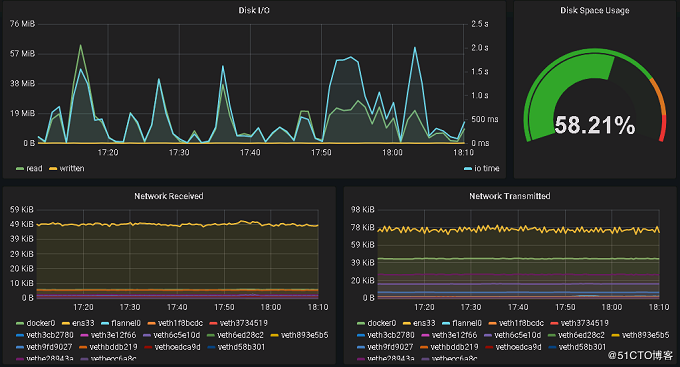
总结:
Weave Scope 可以展示集群和应用的完整视图。其出色的交互性让用户能够轻松对容器化应用进行实时监控和问题诊断。
Heapster 是 Kubernetes 原生的集群监控方案。预定义的 Dashboard 能够从 Cluster 和 Pods 两个层次监控 Kubernetes。
Prometheus Operator 可能是目前功能最全面的 Kubernetes 开源监控方案。除了能够监控 Node 和 Pod,还支持集群的各种管理组件,比如 API Server、Scheduler、Controller Manager 等。
Kubernetes 监控是一个快速发展的领域。随着 Kubernetes 的普及,一定会涌现出更多的优秀方案。