介绍
之前部门开发一个项目我们需要实现一个定时任务用于收集每天DUBBO接口、域名以及TOMCAT(核心应用)的访问量,这个后面的逻辑就是使用定时任务去ES接口抓取数据存储在数据库中然后前台进行展示。

点开以后的详情
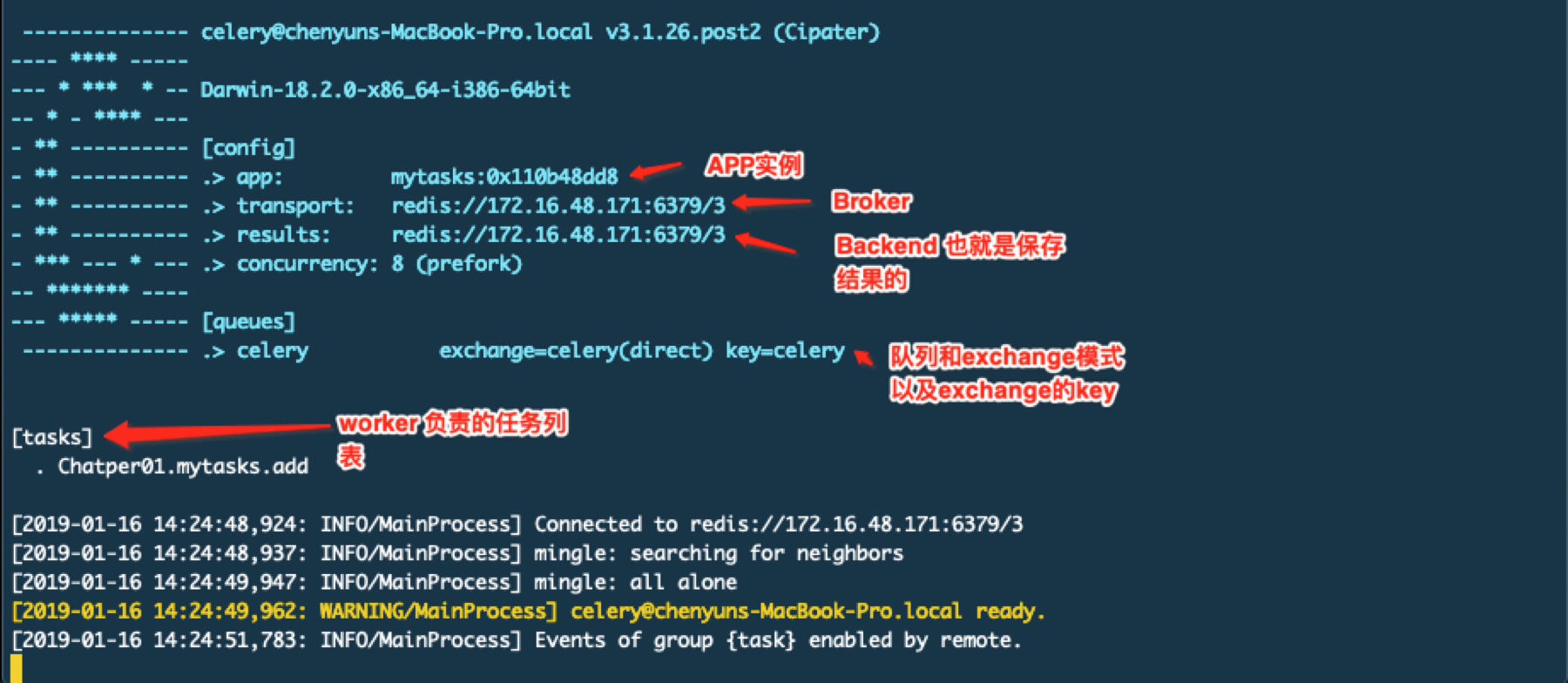
在这个项目中使用的定时任务是python-crontab这个东西,它很简单但是使用起来有些不方便,虽然程序后来也没有进行修改,但是还是想看看有没有更好的定时任务框架,后来就发现了Celery这个项目。下面我们看看Celery的架构,让大家有个整体认识:

下面先来认识一下它的一些组件以及这些组件或者叫做角色的是干什么的
Task:任务(Task)就是你要做的事情,例如一个注册流程里面有很多任务,给用户发验证邮件就是一个任务,这种耗时的任务就可以交给Celery去处理,还有一种任务是定时任务,比如每天定时统计网站的注册人数,这个也可以交给Celery周期性的处理。我们在tasks.py中写的就是worker要可以执行的任务。
Broker: 在Celery中这个角色相当于数据结构中的队列,介于生产者和消费者之间经纪人。例如一个Web系统中,生产者是主程序,它生产任务,将任务发送给 Broker,消费者是 Worker,是专门用于执行任务的后台服务。Celery本身不提供队列服务,一般用Redis或者RabbitMQ来实现队列服务。
Worker: Worker 就是那个一直在后台执行任务的人,也成为任务的消费者,它会实时地监控队列中有没有任务,如果有就立即取出来执行。
Beat: Beat 是一个定时任务调度器,它会根据配置定时将任务发送给 Broker,等待 Worker 来消费。
Backend: Backend 用于保存任务的执行结果,每个任务都有返回值,比如发送邮件的服务会告诉我们有没有发送成功,这个结果就是存在Backend中,当然我们并不总是要关心任务的执行结果。
Exchanges:交换器,用于把不同消息放到不同的消息队列中
Queues:消息队列
为什么需要这两个worker会监控特定的队列同时也有一个默认的交换器,通常会有多个worker处理不同任务,那如何区分不同消息属于哪个worker处理呢这就需要交换器和队列。通常不需要指定队列和交换器因为有一个自动路由功能,如果你需要配置更加复杂的路由就需要使用这两个。默认的queue/exchange/binding的键是celery,exchange的类型是direct
安装
我的环境是Python3.6
# 安装celery pip install celery # 因为我这里用到redis做后端所以需要安装redis,但是需要注意虽然我的celery版本是最新的,但是redis驱动你不能用最新的 # 否则任务执行会失败 pip install redis==2.10.6 # flower组件不是必须的,它是用来对celery进行监控的 pip install flower
Celery入门
第一个任务
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import time
from celery import Celery
# 第一个参数是当前模块名称
# celery -A mytasks worker --loglevel=info 通过这个运行的时候-A后面的参数要和模块名称一致,这样就启动了一个worker来执行任务
# broker是任务队列放在哪里 backend是任务执行结果放在哪里
app = Celery("mytasks", broker="redis://172.16.48.171:6379/3", backend="redis://172.16.48.171:6379/3")
# 这个装饰器让add变成一个异步任务
@app.task
def add(x, y):
return x + y
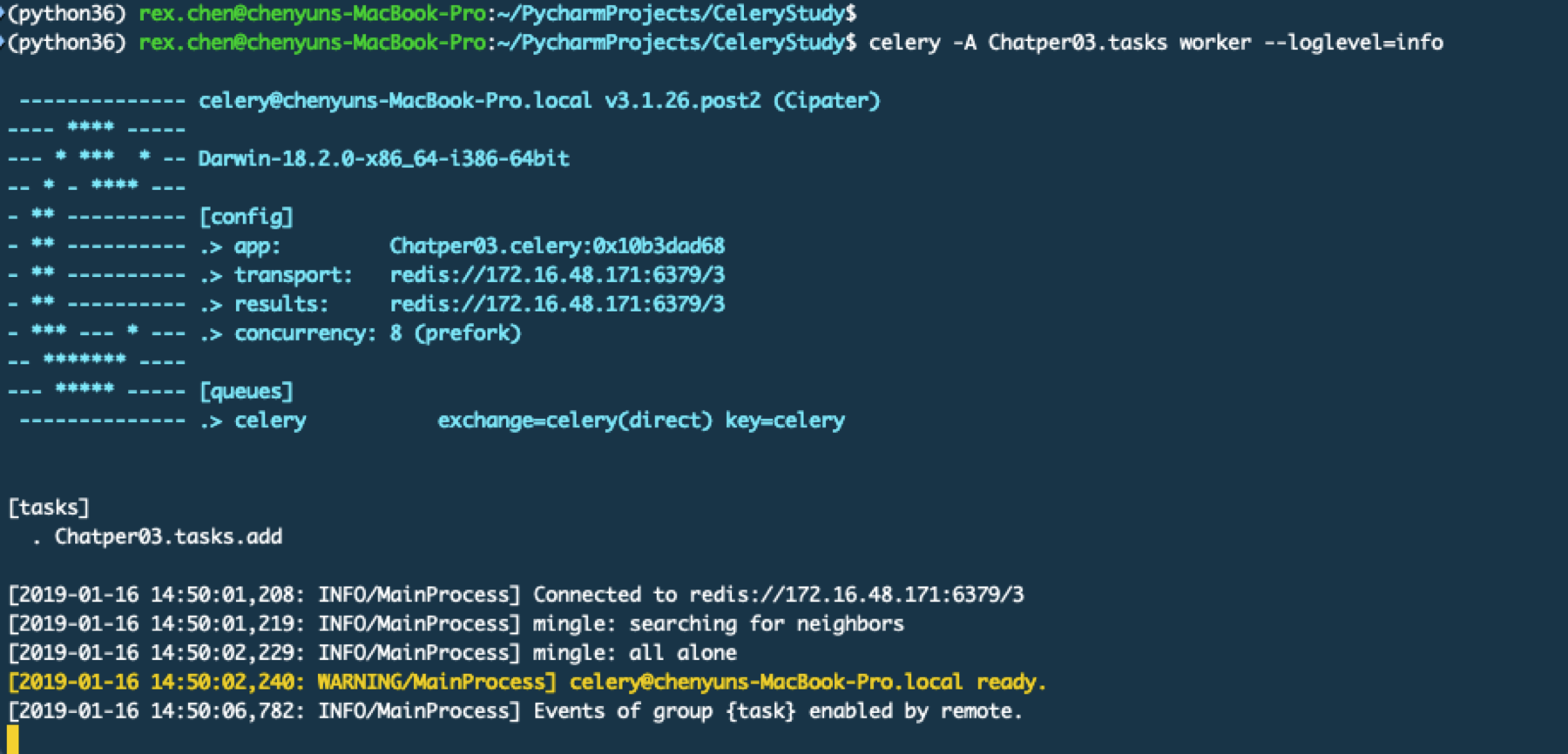
Celery在被使用之前一定要进行实例化,一个实例叫做一个Application也称作一个app,就像上面定义的app = Celery()。一个实例化的app是线程安全的。注意上面的目录结构,下面启动一个worker。-A参数是指定celery对象的位置,也就是celery实例的py文件,默认它会使用celery.py,如果使用了其他名字比如我们这里就用了mytasks.py,那么你就要指定具体的这个文件名称。下面我们启动任务
celery -A Chatper01.mytasks worker --loglevel=info

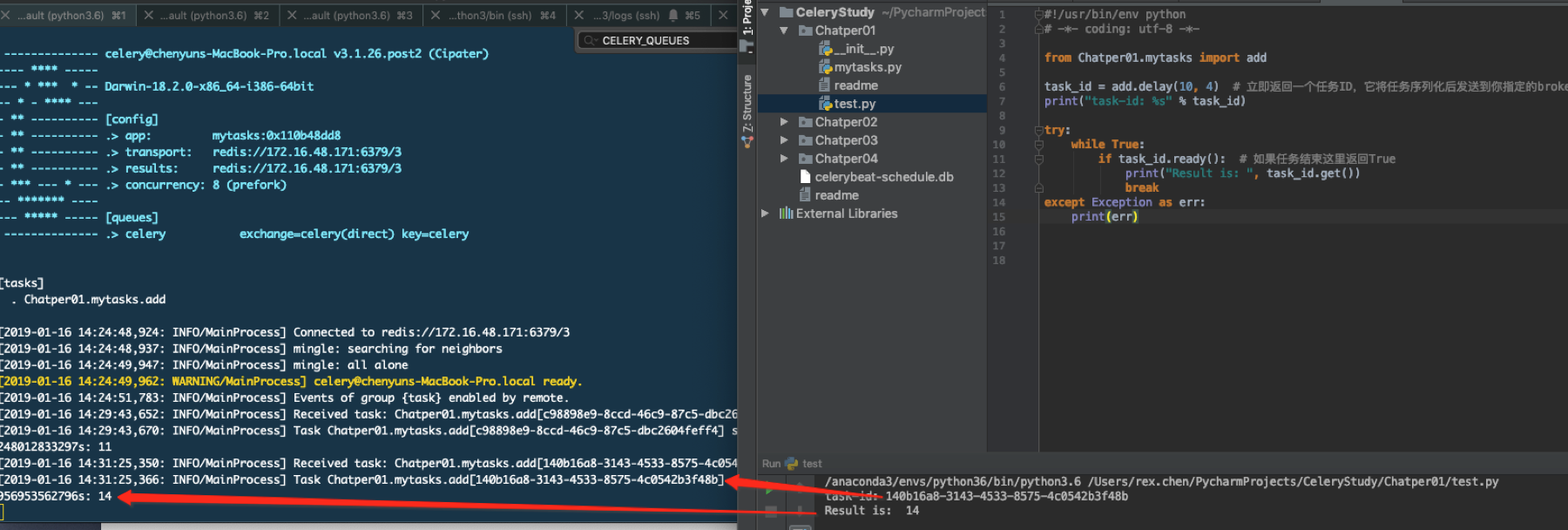
下面看看如何调度任务也就是执行任务


在代码中如何执行任务呢?
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from Chatper01.mytasks import add
task_id = add.delay(10, 4) # 立即返回一个任务ID,它将任务序列化后发送到你指定的broker
try:
while True:
if task_id.ready(): # 如果任务结束这里返回True
print("Result is: ", task_id.get())
break
except Exception as err:
print(err)
调用add.delay()函数后会返回一个AsyncReult的对象,通过这个对象可以获取如下内容:
| state | 返回任务状态 |
| task_id | 返回任务ID |
| result | 返回任务执行结果,等同于调用get()方法 |
| ready() | 判断任务是否完成 |
| info() | 获取任务信息 |
| wait(seconds) | 等待N秒后获取结果 |
| successful() | 判断任务是否成功 |
对比命令执行和代码执行的结果
命令行启动任务后如何结束呢?Ctrl+C。无论是启动的任务还是执行任务,只要是命令行启动的都可以这样来结束,官方文档也是这样说的。
调用一个任务一个任务其实就是发送一个消息到队列中,worker收到消息就会进行处理,也就是真正执行消息对应的函数。Worker如果没有确认这个消息被消费或者说确认那么这个消息将不会被移除
如何把任务代码拆出来呢?
目的是为了单独一个文件写task,一个文件做celery的初始化工作。
初始化celery
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import absolute_import
import sys
from celery import Celery
# 这里多了一个 include参数,这个就是引入你的具体任务的py文件
app = Celery("Chatper02", broker="redis://172.16.48.171:6379/3", backend="redis://172.16.48.171:6379/3",
include=["Chatper02.tasks"])
if __name__ == "__main__":
try:
app.start()
finally:
sys.exit()
在Celery初始化时候,最后一个参数这里用来include来实现载入task,这里要注意写的是tasks.py文件的路径。而且需要注意这里的第一个引用是使用了绝对引用在Python2中必须要这么写,但是在Python3中绝对引用是默认设置可以不用写。绝对路径导入后你就可以在代码里使用相对名称。
任务文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import absolute_import
from Chatper02.celery import app
@app.task
def add(x, y):
return x + y
这里就实现了配置和任务分离,启动方式和之前一样

如何做配置分离呢?
目的是单独一个文件写Celery的初始化配置信息,因为它的配置项还是不少的,虽然你可能用不了那么多因为默认设置基本够用,但是通常来讲结构上还是要做到相对规范。这里我还是先展示一下目录结构吧
配置文件 config.py 它其实就是一个Python文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
http://docs.celeryproject.org/en/latest/userguide/configuration.html#cache-backend-settings
https://blog.csdn.net/libing_thinking/article/details/78812472
"""
# 如果密码连接就是这样的 'redis://:password@host:port/db'
BROKER_URL = 'redis://172.16.48.171:6379/3'
# 是否自动重连,默认是 True
BROKER_CONNECTION_RETRY = True
# 重连最大次数,默认是100
BROKER_CONNECTION_MAX_RETRIES = 100
CELERY_RESULT_BACKEND = 'redis://172.16.48.171:6379/3'
# 导入task 如果不在这里就需要在 Celery(__name__, include=["Chatper03.tasks"])
CELERY_INCLUDE = "Chatper03.tasks"
# 任务序列化方式 Default: "json"
CELERY_TASK_SERIALIZER = 'json'
# 结果序列化方式 Default: json
CELERY_RESULT_SERIALIZER = 'json'
# 结果过期时间 默认1天,单位秒
CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24
# 指定任务接受的内容类型 Default: {'json'} (set, list, or tuple).
CELERY_ACCEPT_CONTENT = ['json']
# 设置时区 Default: "UTC".
# CELERY_TIMEZONE = 'Asia/Shanghai'
# 是否启用UTC时间
CELERY_ENABLE_UTC = True
初始化文件 celery.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import absolute_import
import sys
from celery import Celery
# 这里使用了 __name__ 来表示模块文件名称,可读性好
app = Celery(__name__)
# 加载配置
app.config_from_object("Chatper03.config")
if __name__ == "__main__":
try:
app.start()
finally:
sys.exit()
还有另外一种写法
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import absolute_import
import sys
from celery import Celery
import Chatper03.config
# 这里使用了 __name__ 来表示模块文件名称,可读性好
app = Celery(__name__)
# 加载配置
# app.config_from_object("Chatper03.config")
app.config_from_object(Chatper03.config)
if __name__ == "__main__":
try:
app.start()
finally:
sys.exit()
这个celery.py也就是app启动文件,这里通过app.config_from_object()载入配置,如果是通过真实的模块加载就提前需要导入就像第二种写法,如果是字符串形式就不需要导入就像第一种写法。
配置参数说明:http://docs.celeryproject.org/en/latest/userguide/configuration.html#cache-backend-settings
任务文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import absolute_import
from Chatper03.celery import app
@app.task
def add(x, y):
return x + y
启动方式还是和之前一样
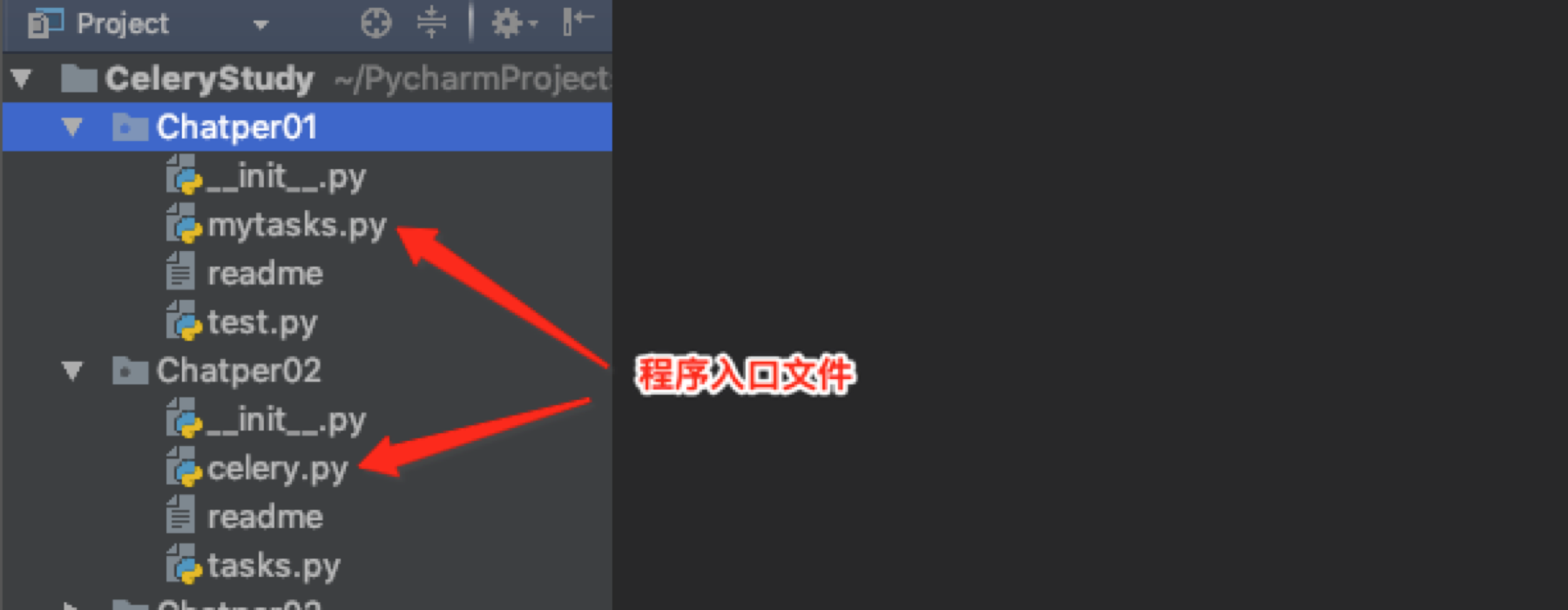
为什么要把程序入口文件叫做celery.py呢?
看下面这张图,例子1和例子2程序入口文件不同
我们启动任务2


是不是发现有区别呢?
如果你的入口文件叫做celery.py那么你就可以不指定任务文件,因为它会先加载celery的配置,然后注册任务。如果按照上例启动Chatper01你就不能省略.mytasks 因为这里有配置。说白了就是它默认找的文件就是celery.py,通过这个来初始化Celery,初始化Celery靠的是配置信息,如果你使用了其他名称就需要指定去哪里读取配置信息。
如何后台启动和关闭worker呢
celery multi start WORKER_NAME –A APP_NAME
启动需要给worker起一个名字,因为同一个APP也就是任务可以启动多个,启动多个的意义就在于分布式。

停止

定时任务
Celery 3.x版本的写法
入口文件celery.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import absolute_import
import sys
from celery import Celery
import Chatper04.config
# 这里使用率 __name__ 来表示模块文件名称,可读性好
app = Celery(__name__)
# 加载配置
app.config_from_object(Chatper04.config)
if __name__ == "__main__":
try:
app.start()
finally:
sys.exit()
配置文件config.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
http://docs.celeryproject.org/en/latest/userguide/configuration.html#cache-backend-settings
"""
# 如果密码连接就是这样的 'redis://:password@host:port/db'
BROKER_URL = 'redis://172.16.48.171:6379/3'
# 是否自动重连,默认是 True
BROKER_CONNECTION_RETRY = True
# 重连最大次数,默认是100
BROKER_CONNECTION_MAX_RETRIES = 100
CELERY_RESULT_BACKEND = 'redis://172.16.48.171:6379/3'
# 导入task 如果不在这里就需要在 Celery(__name__, include=["Chatper03.tasks"])
CELERY_INCLUDE = "Chatper04.tasks"
# 任务序列化方式 Default: "json"
CELERY_TASK_SERIALIZER = 'json'
# 结果序列化方式 Default: json
CELERY_RESULT_SERIALIZER = 'json'
# 结果过期时间 默认1天,单位秒
CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24
# 指定任务接受的内容类型 Default: {'json'} (set, list, or tuple).
CELERY_ACCEPT_CONTENT = ['json']
# 设置时区 Default: "UTC".
# CELERY_TIMEZONE = 'Asia/Beijing'
# 是否启用UTC时间
CELERY_ENABLE_UTC = True
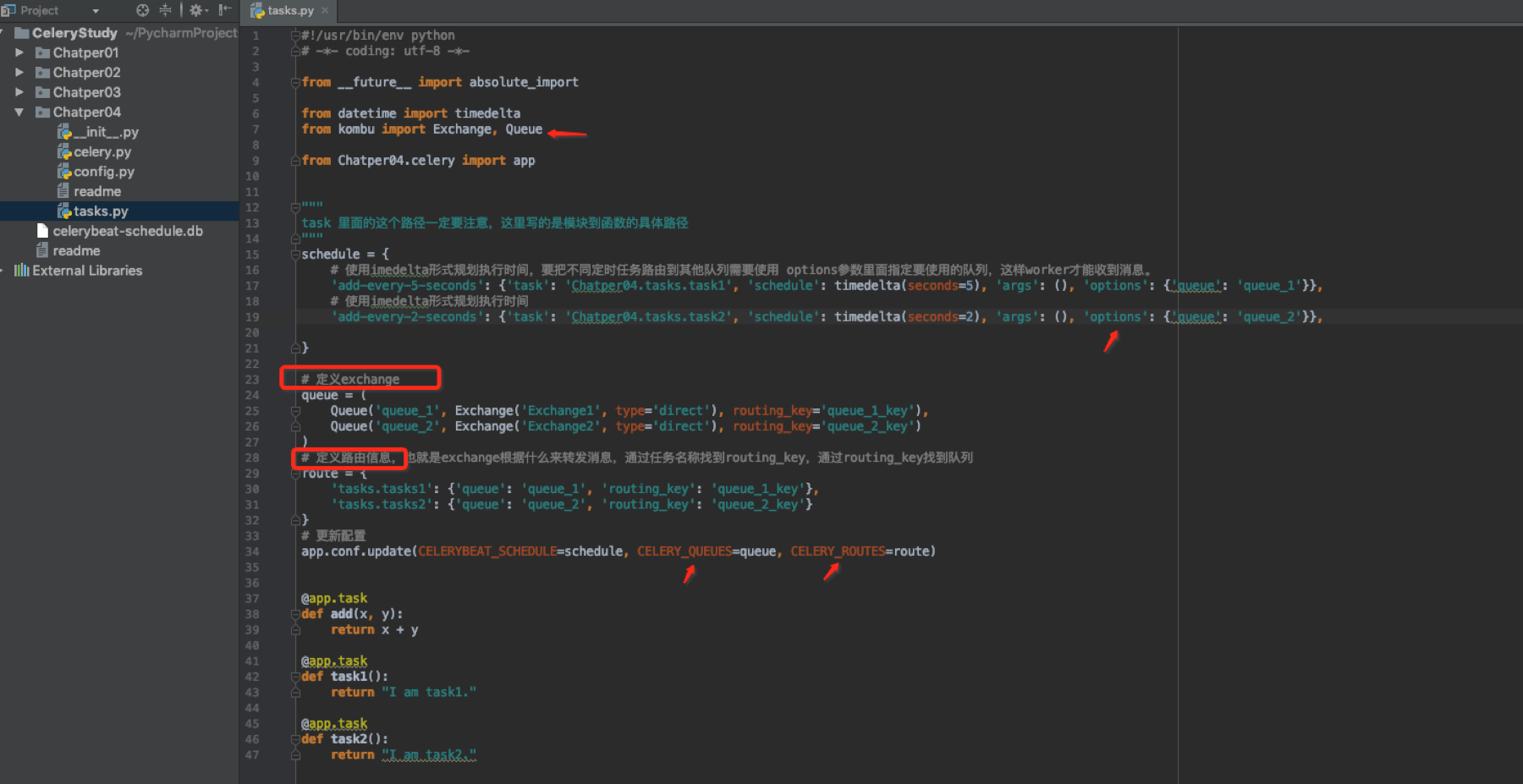
任务文件tasks.py
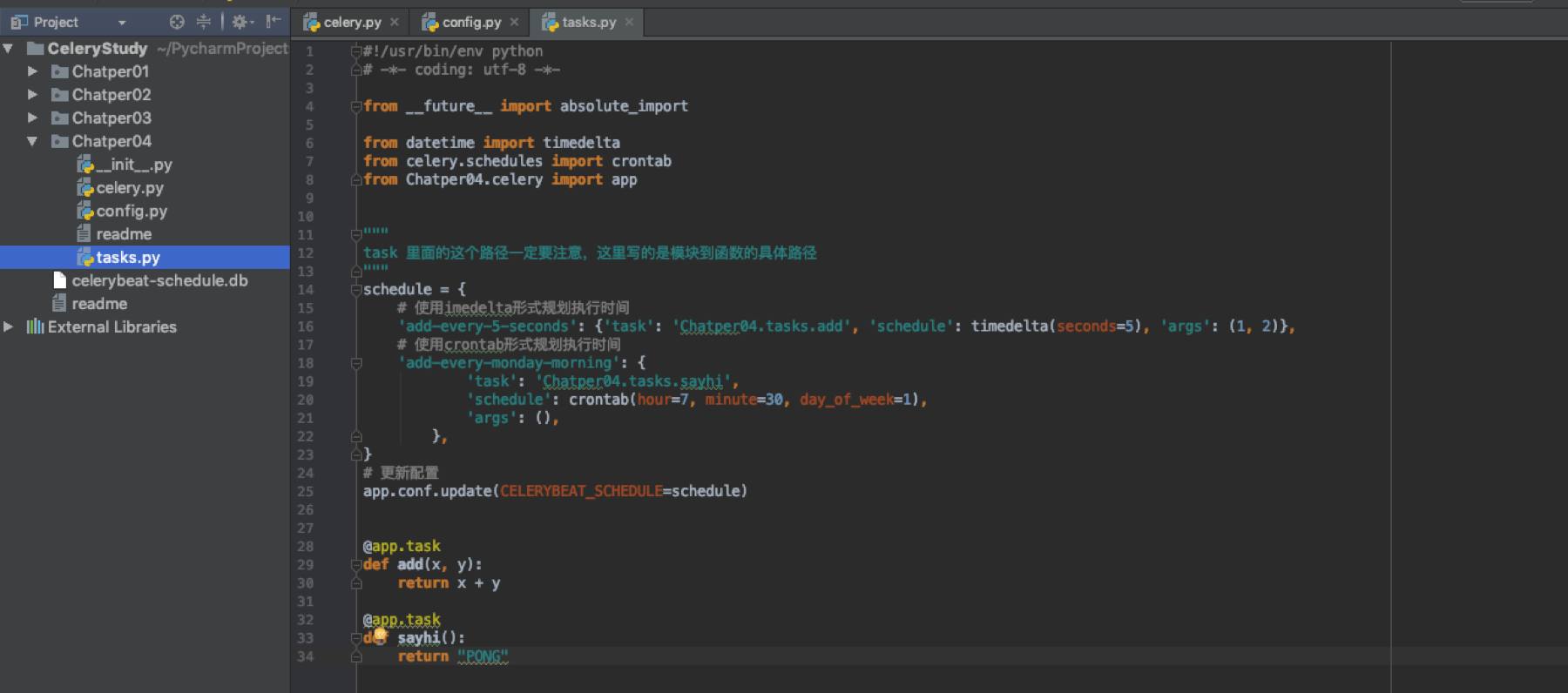
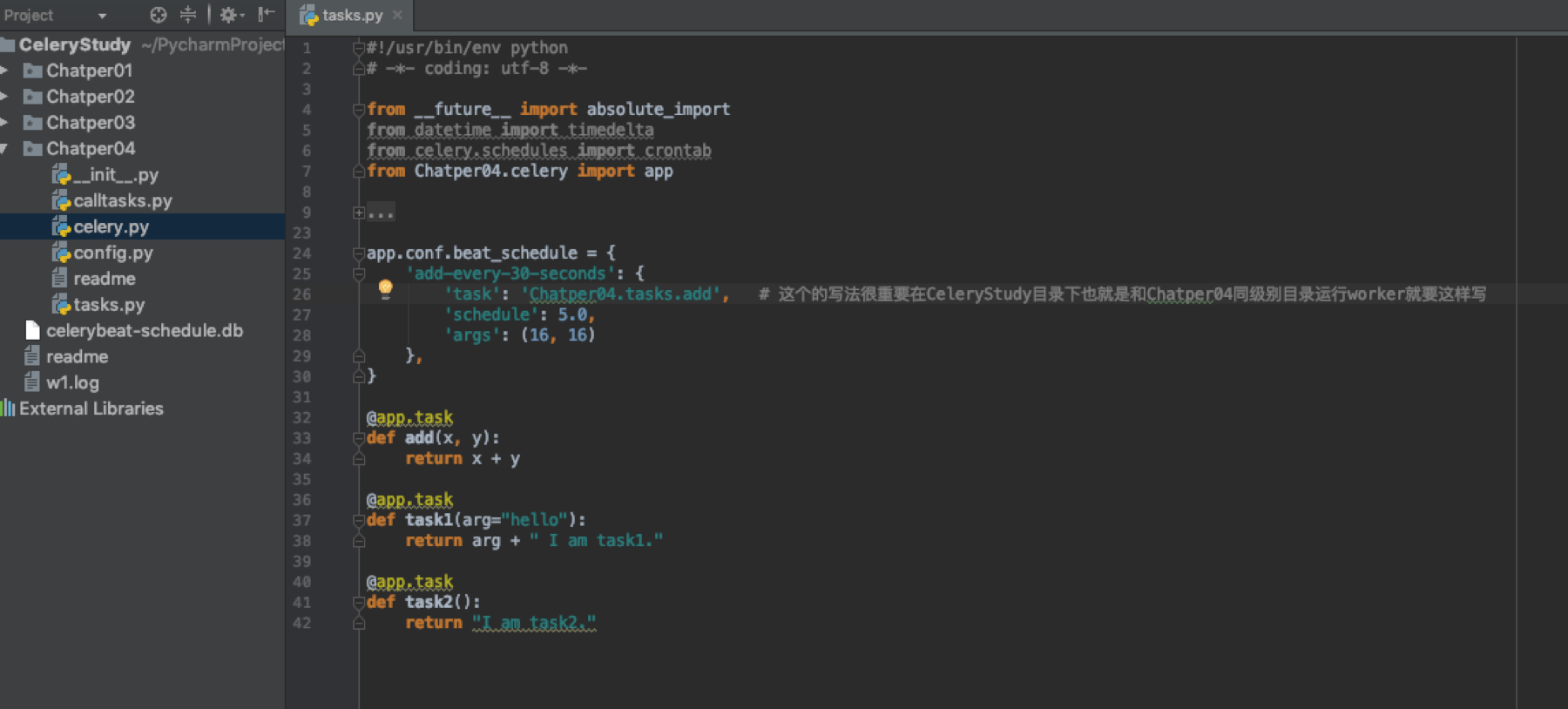
在配置中CELERYBEAT_SCHEDULE定义了beat定时服务的属性,当设置好了以后需要更新配置。
启动worker
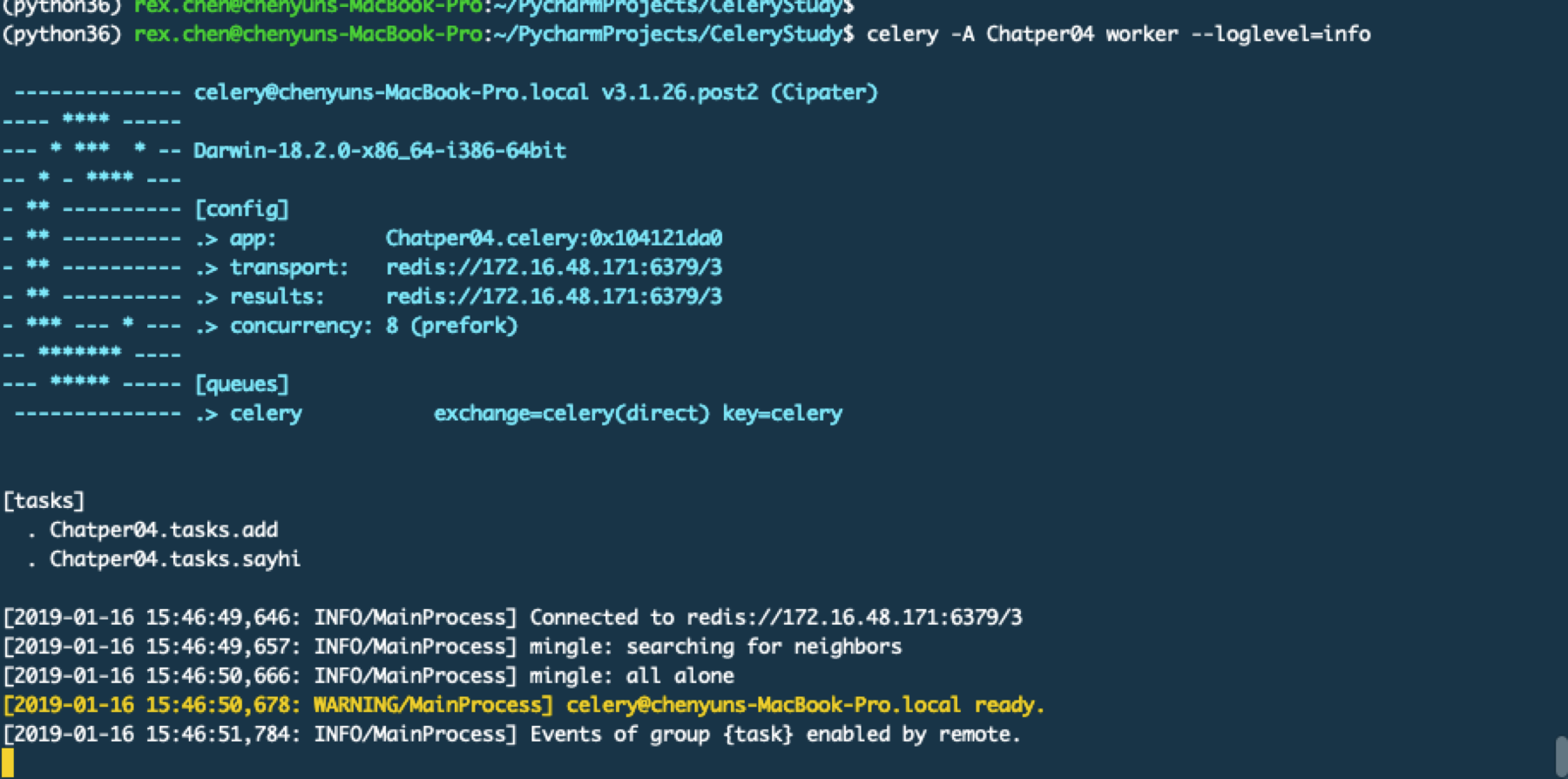
启动beat服务,它用于定期去执行指定的任务
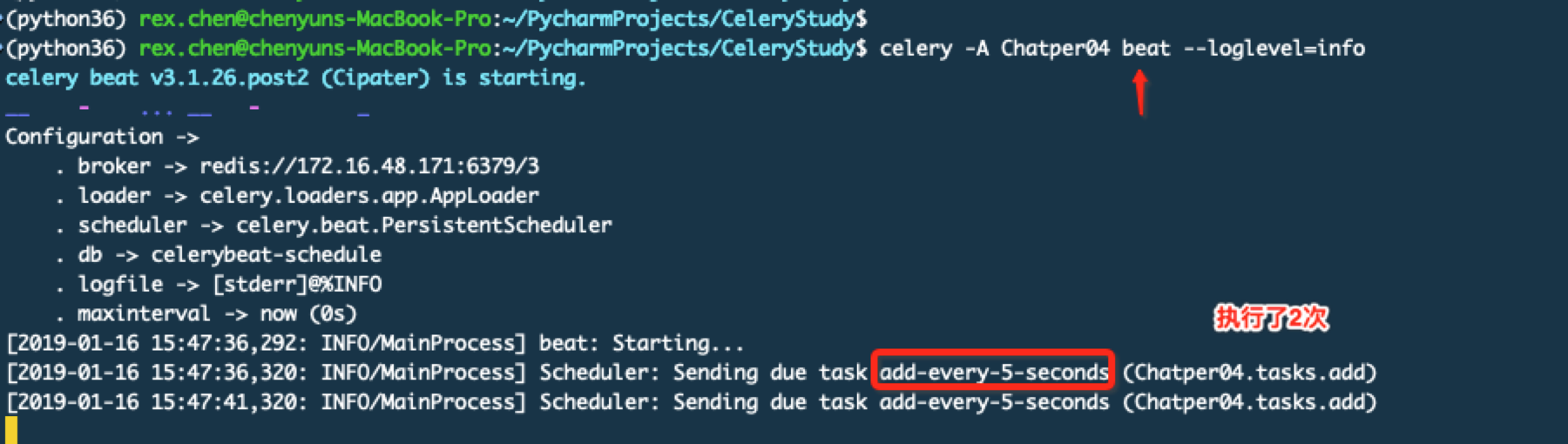
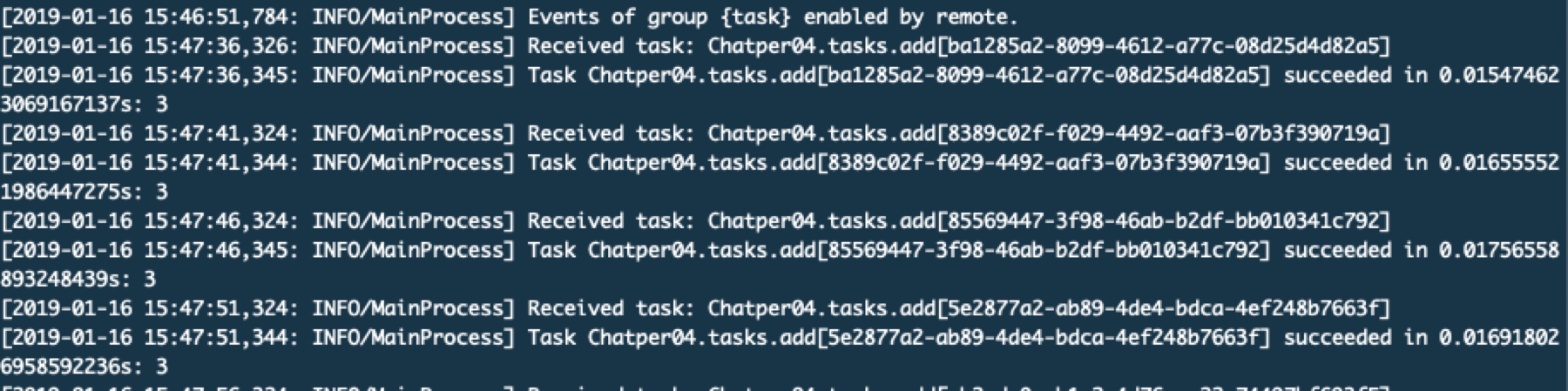
查看worker这边的日志输出
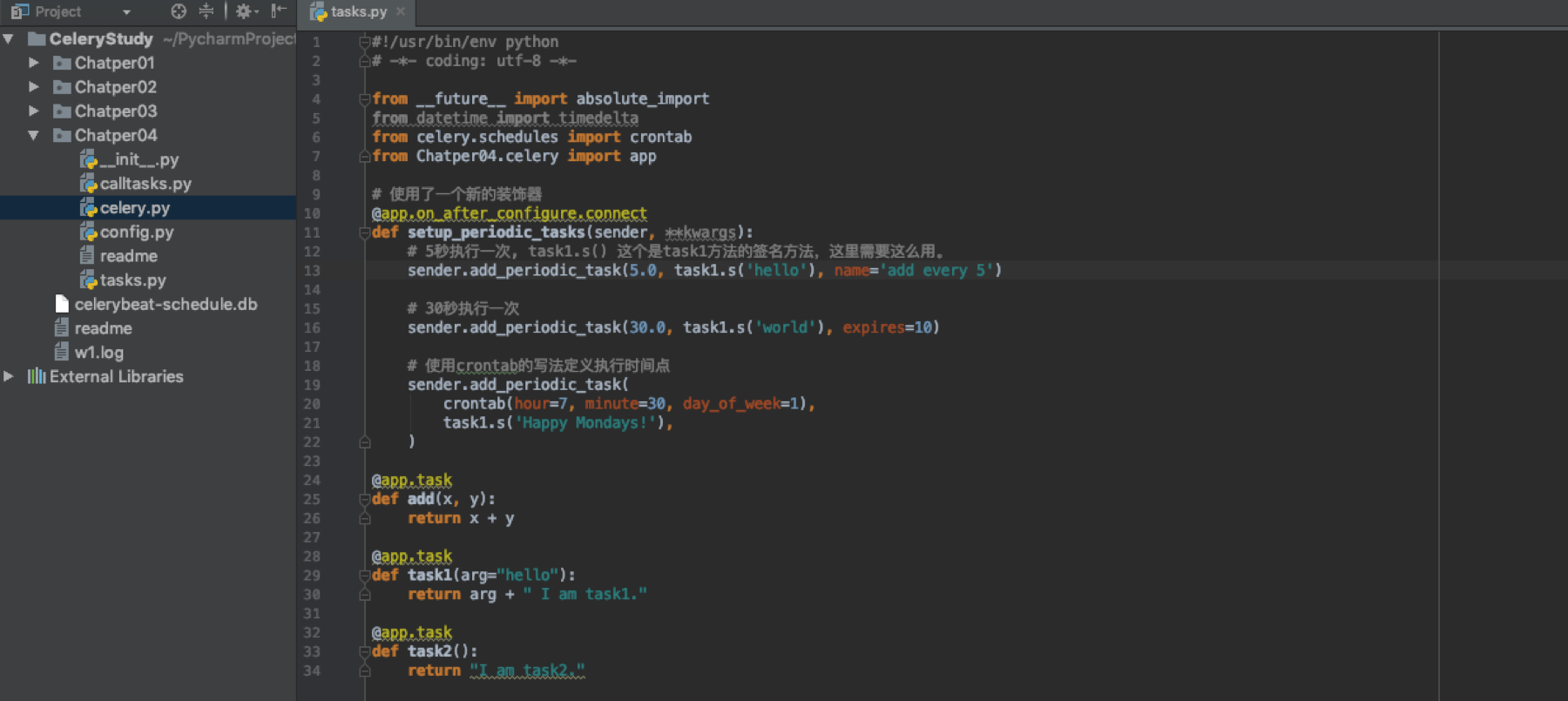
Celery 4.x版本的写法
在4.x中也可以使用上面的写法。下面唯一有变化的就是tasks.py文件
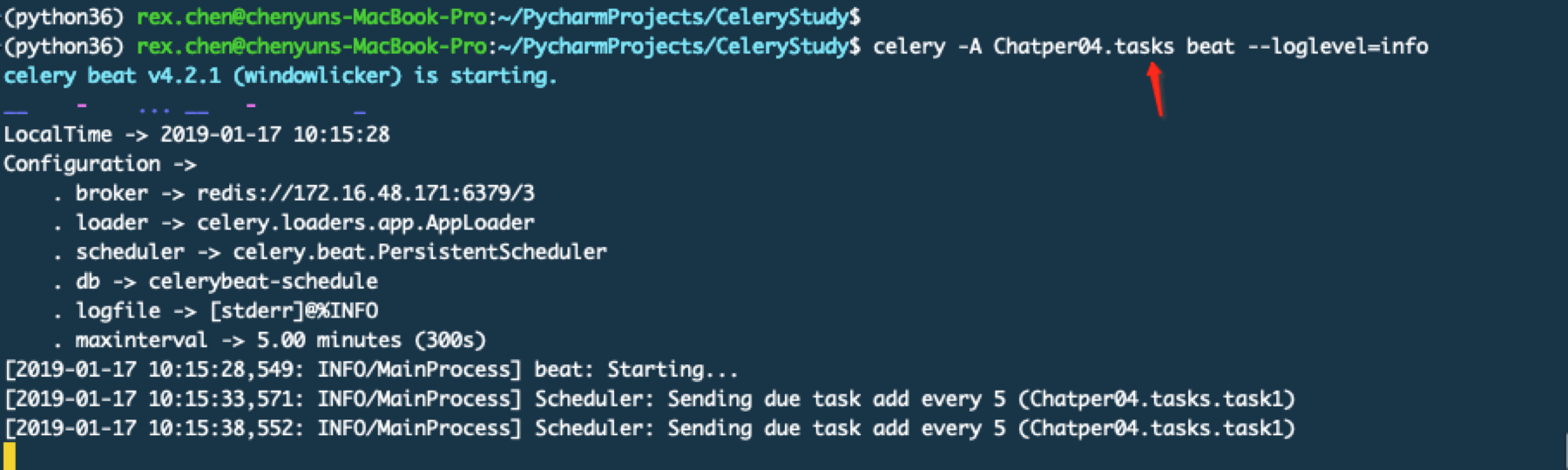
启动方式和之前以后,只是升级到最新4.2.1版本后启动界面有些变化
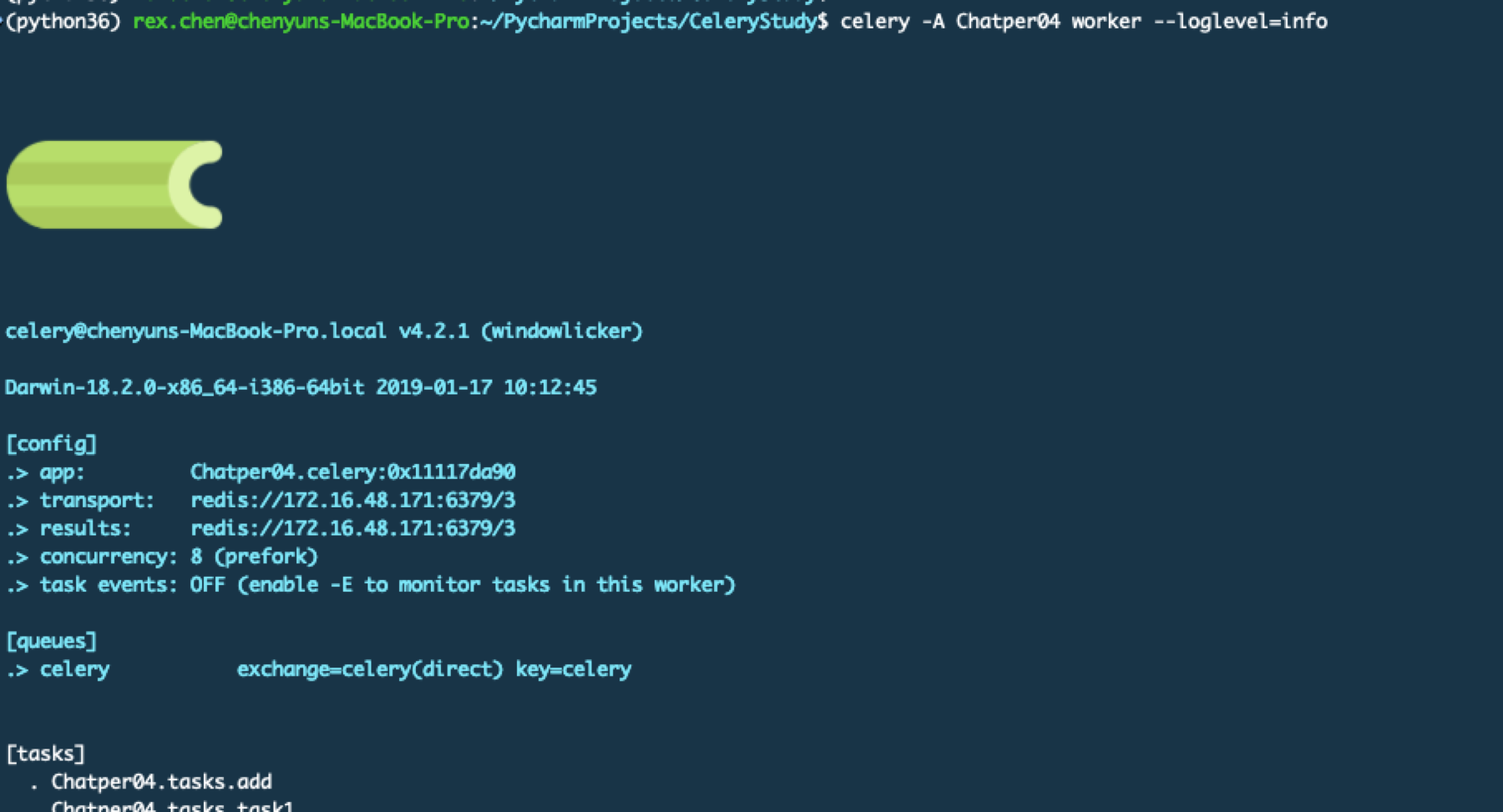
启动beat服务的命令还是一样的,这里要加上任务文件的名称
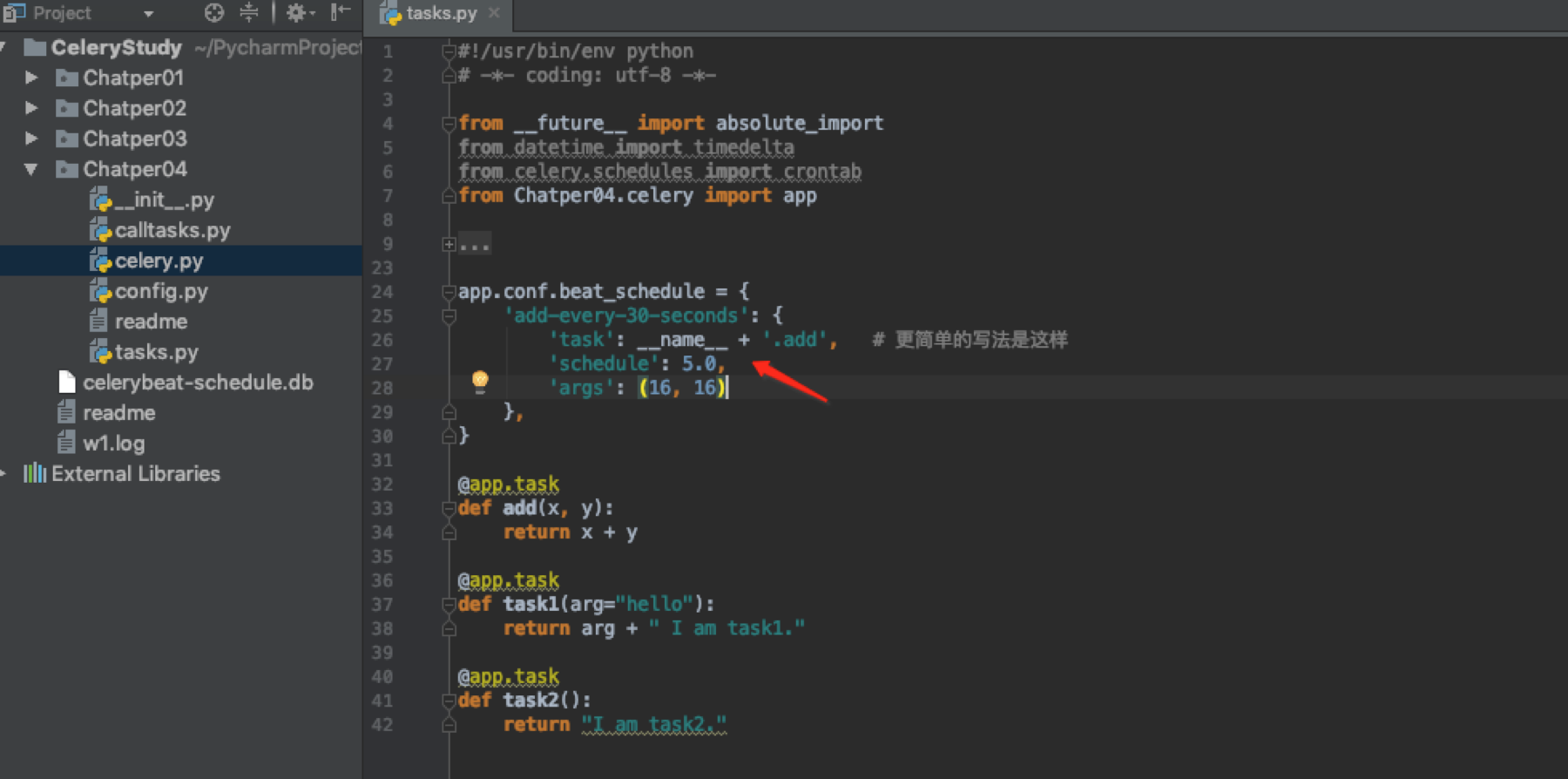
Celery 4.x的另外一种写法
执行work和beat的方法还是一样的
task装饰器的一些属性
bind属性
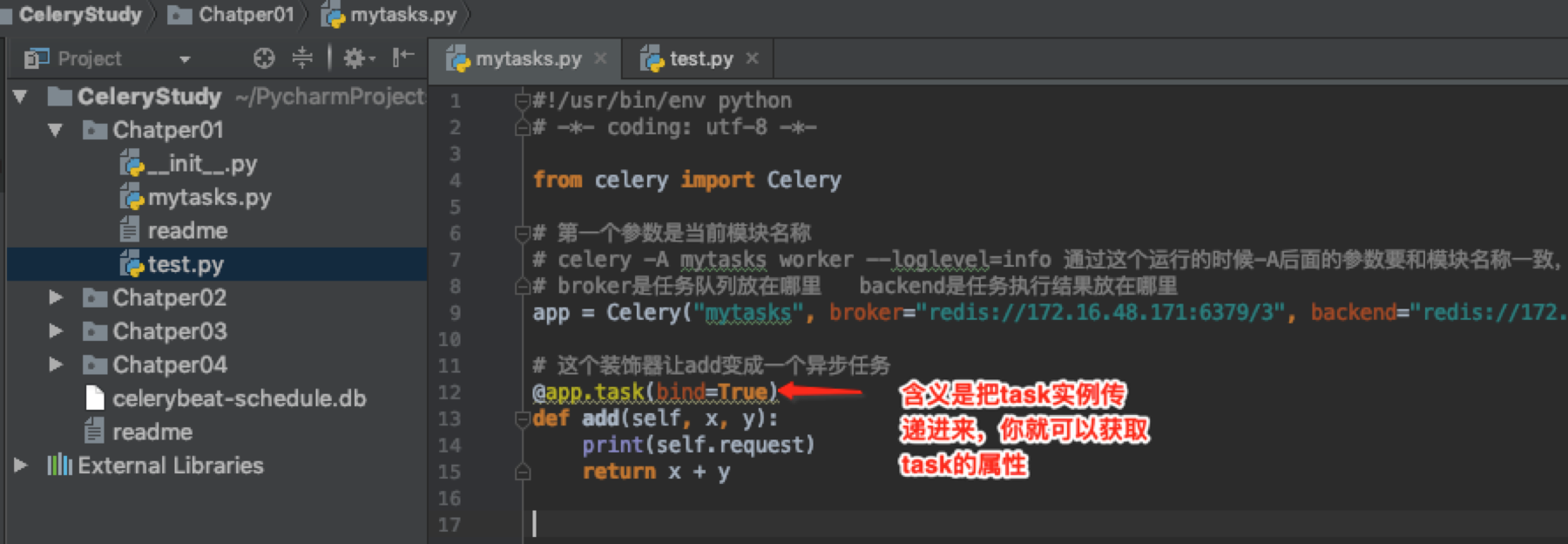

在程序里就可以通过.来获取比如self.request.task等。当bind=True时,被调用的函数传递进去的第一个参数就是task实例也就是这里的self。
base属性
定义基类,可以用词来定义回调函数
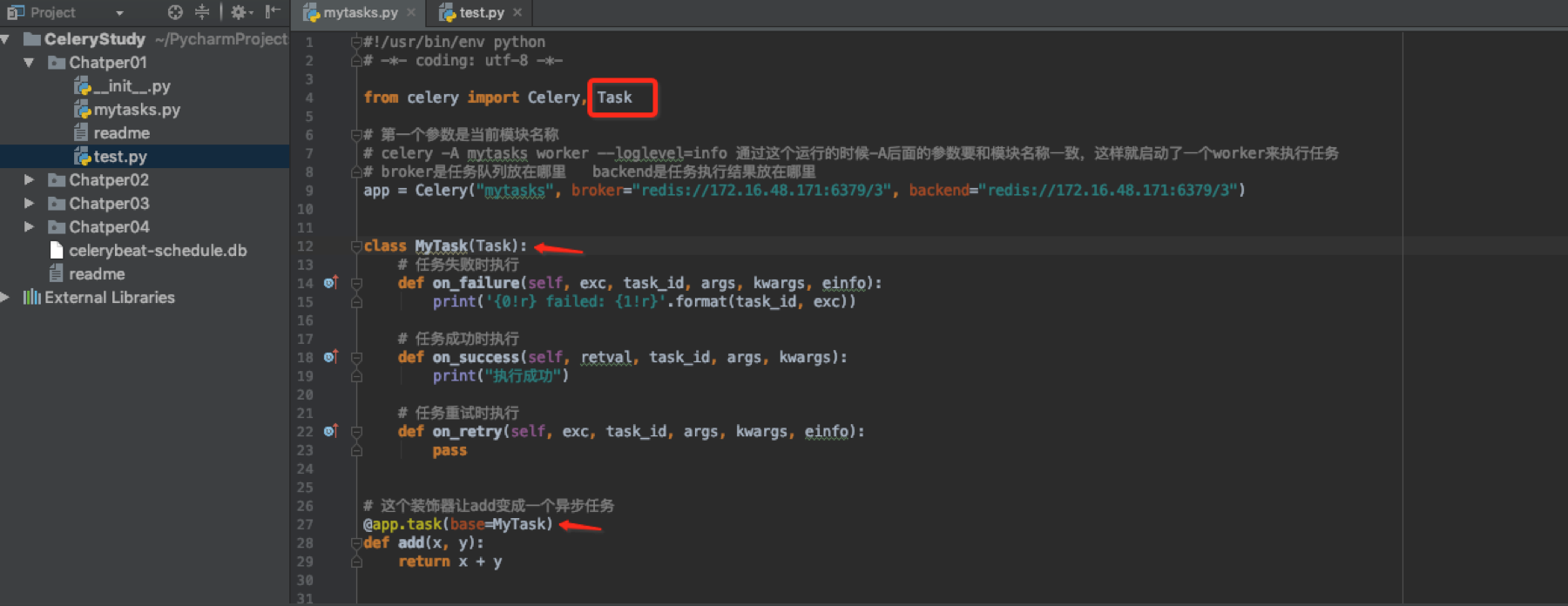
调用成功会有这样的动作

关于路由
producer发出调用请求(message包含所调用任务的相关信息)—>celery服务启动时,会产生一个或多个交换机(exchanges),对应的交换机 接收请求message—>交换机根据message内容,将message分发到一个或多个符合条件的队列(queue)—>每个队列上都有一个或多个worker在监听,在监听到符合条件的message到达后,worker负责进行任务处理,任务处理完被确认后,队列中的message将被删除。
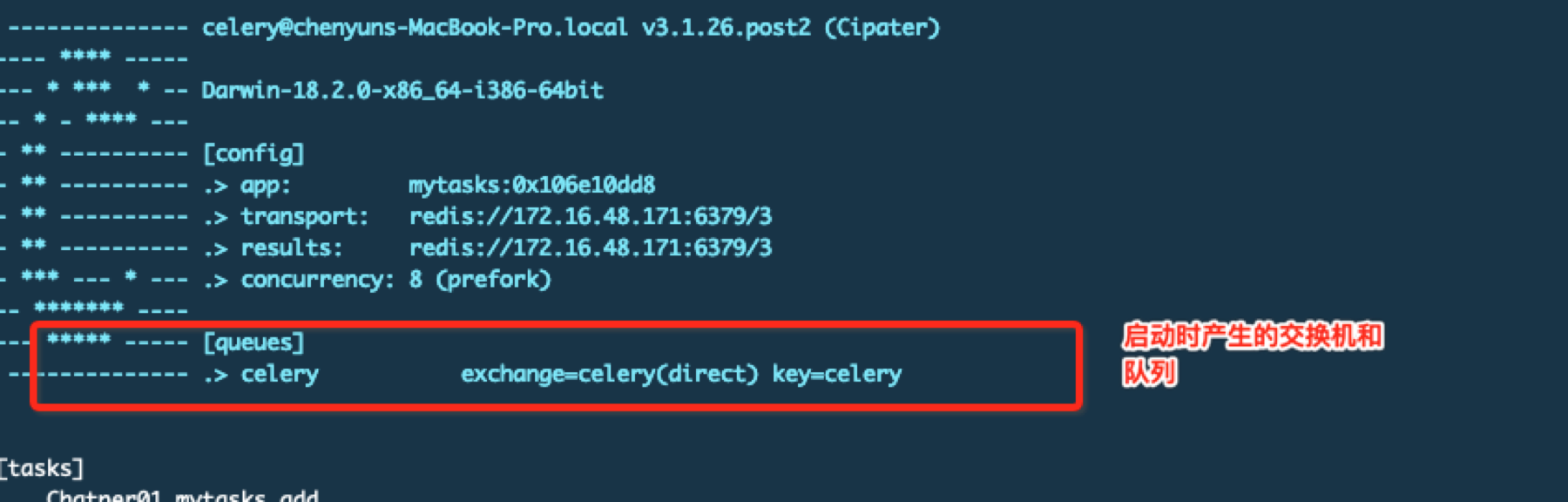
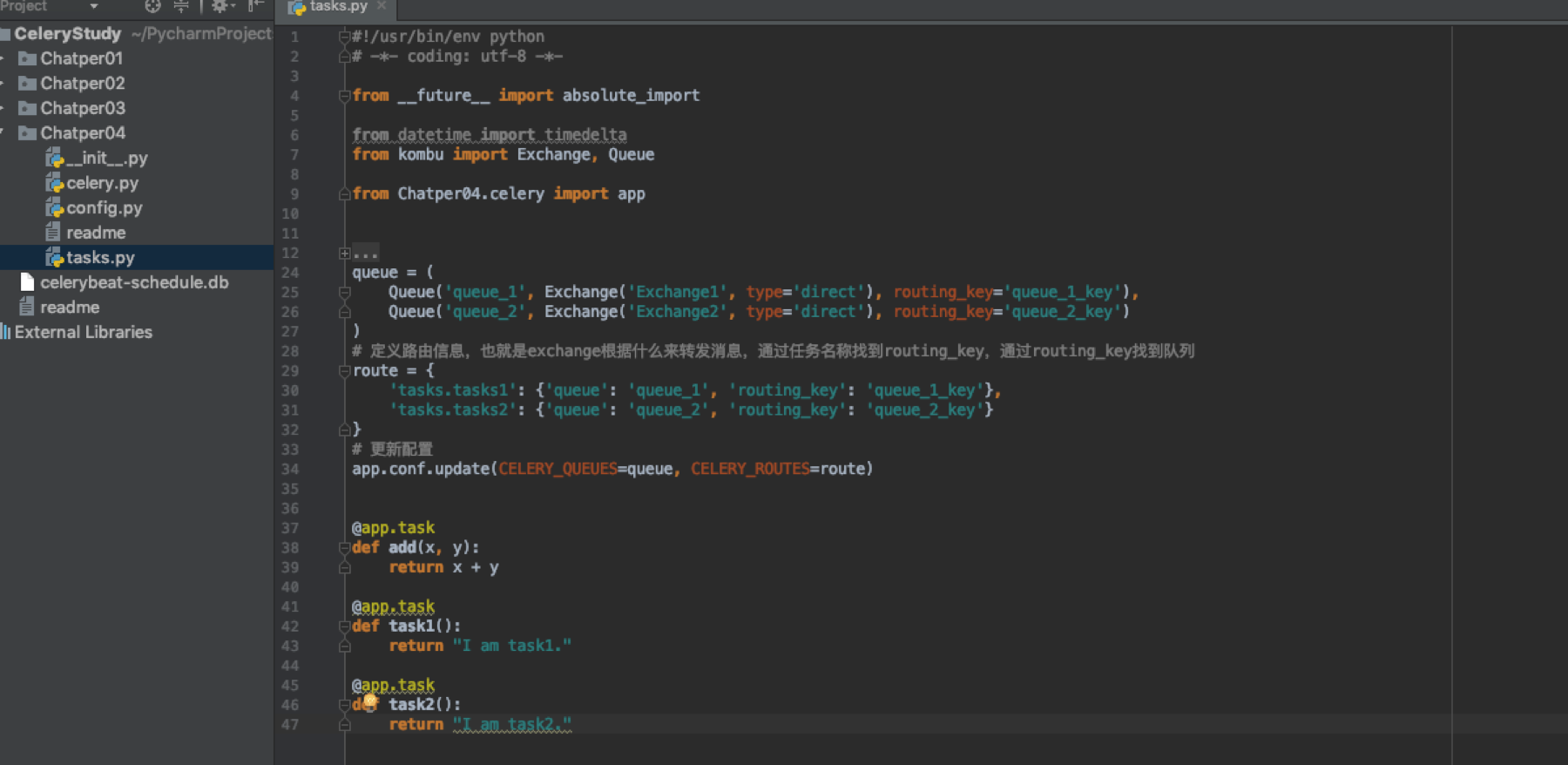
启动worker时它会监听在默认的队列是celery,键是celery。我们的worker就监听在这个默认的队列celery上,生产者调用任务时由于也都使用默认值所以exchange根据key来路由消息,就把消息路由到其对应的队里上,这样在这里监听的worker就会捕捉的该消息。我们修改一下之前的定时任务的tasks.py文件,其他不变,这些队列和路由信息也可以直接写到config.py中去。
分别打开2个终端运行worker
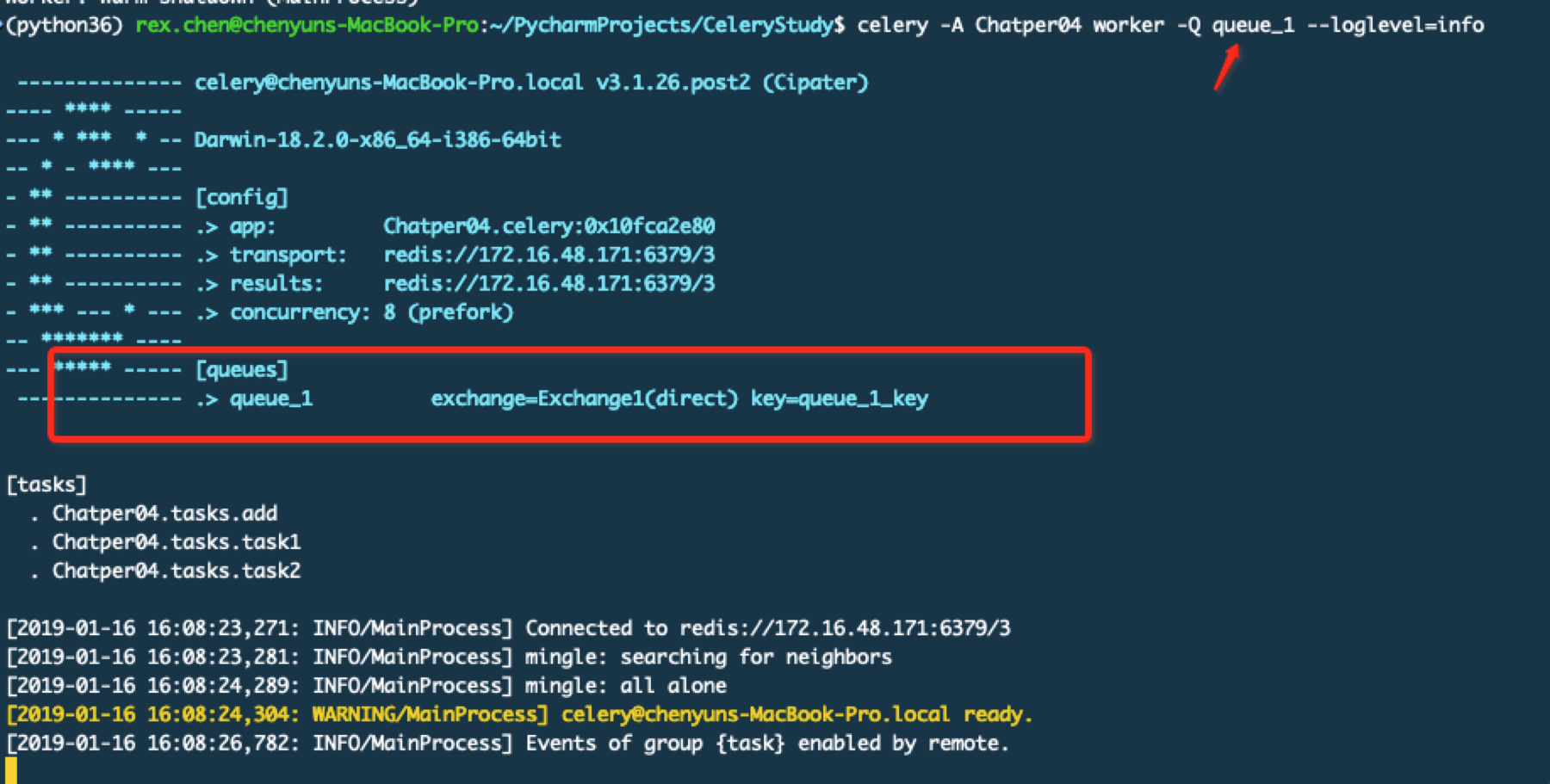
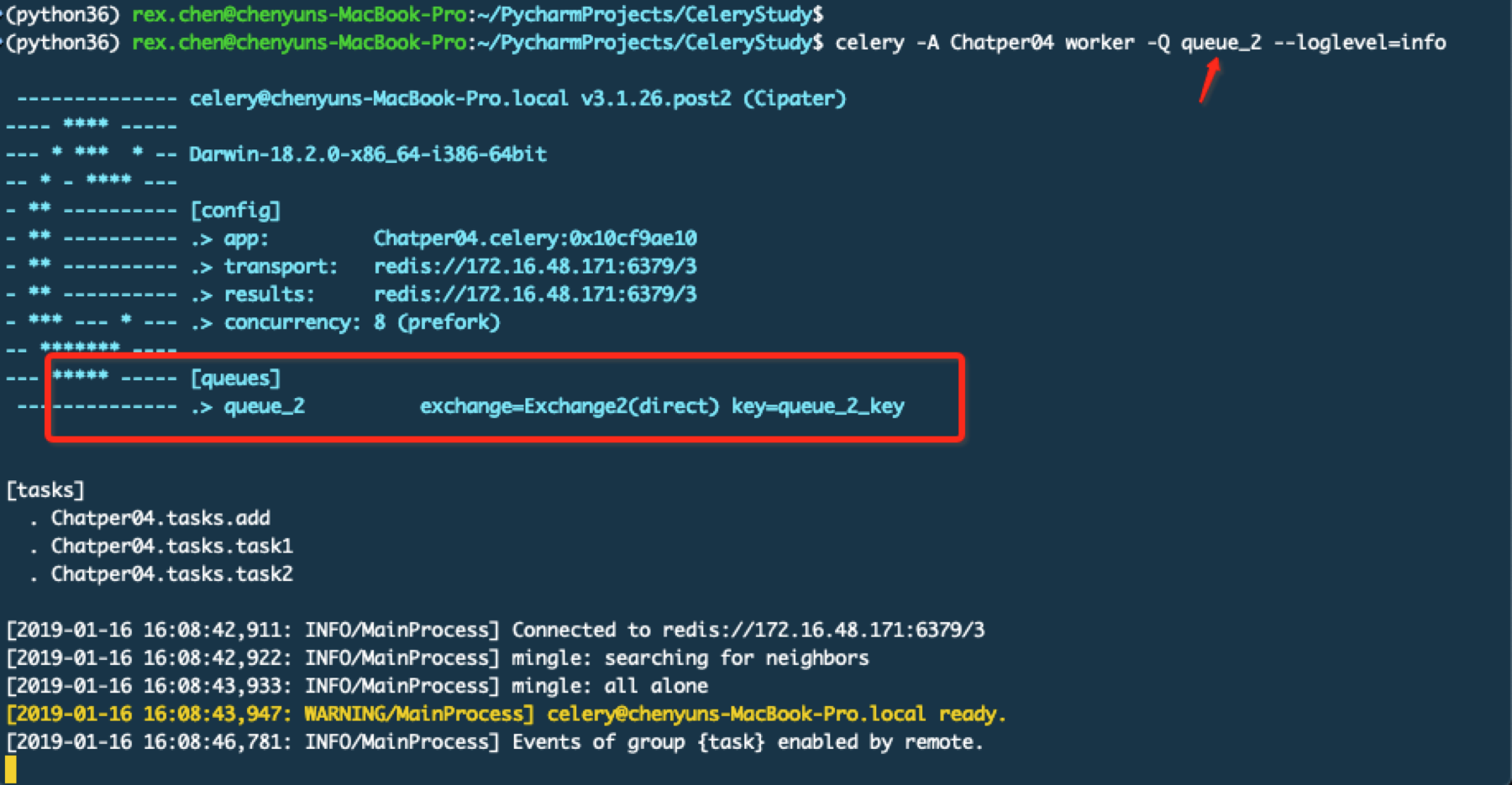
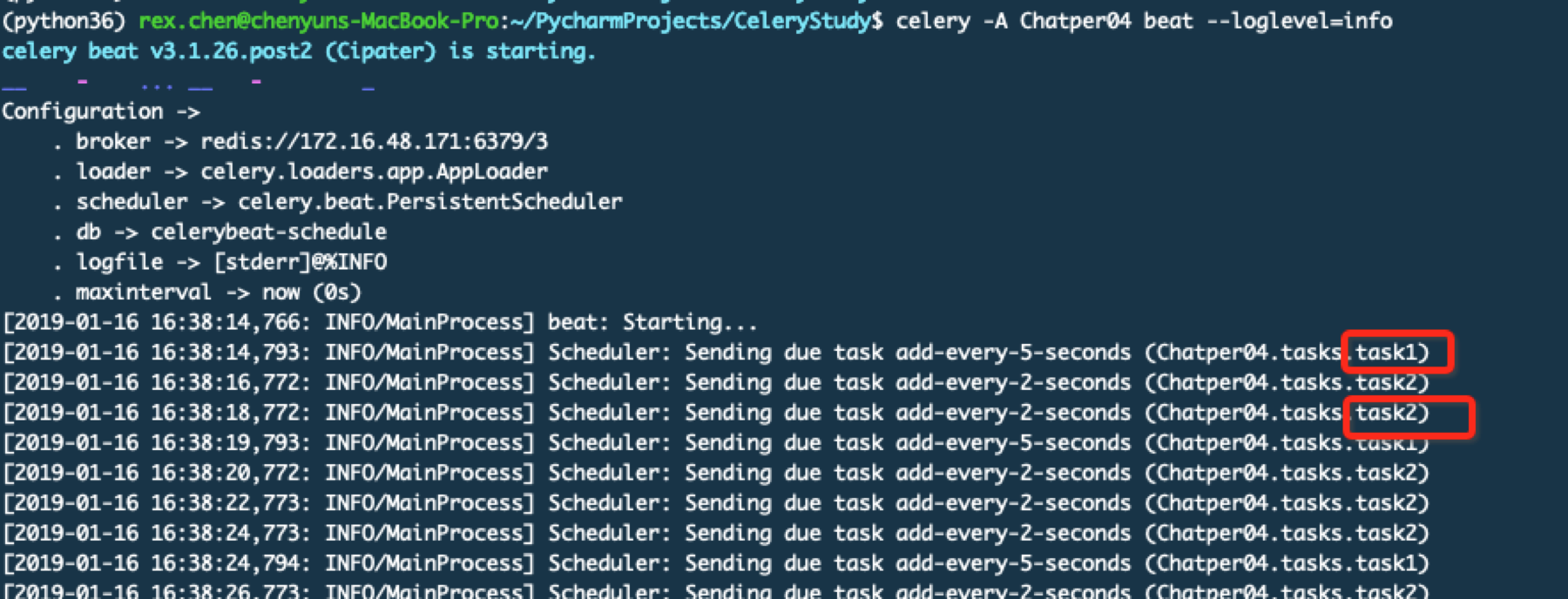
通过上面的截图可以看到不同的worker监听在不同的队列中,下面启动beat服务
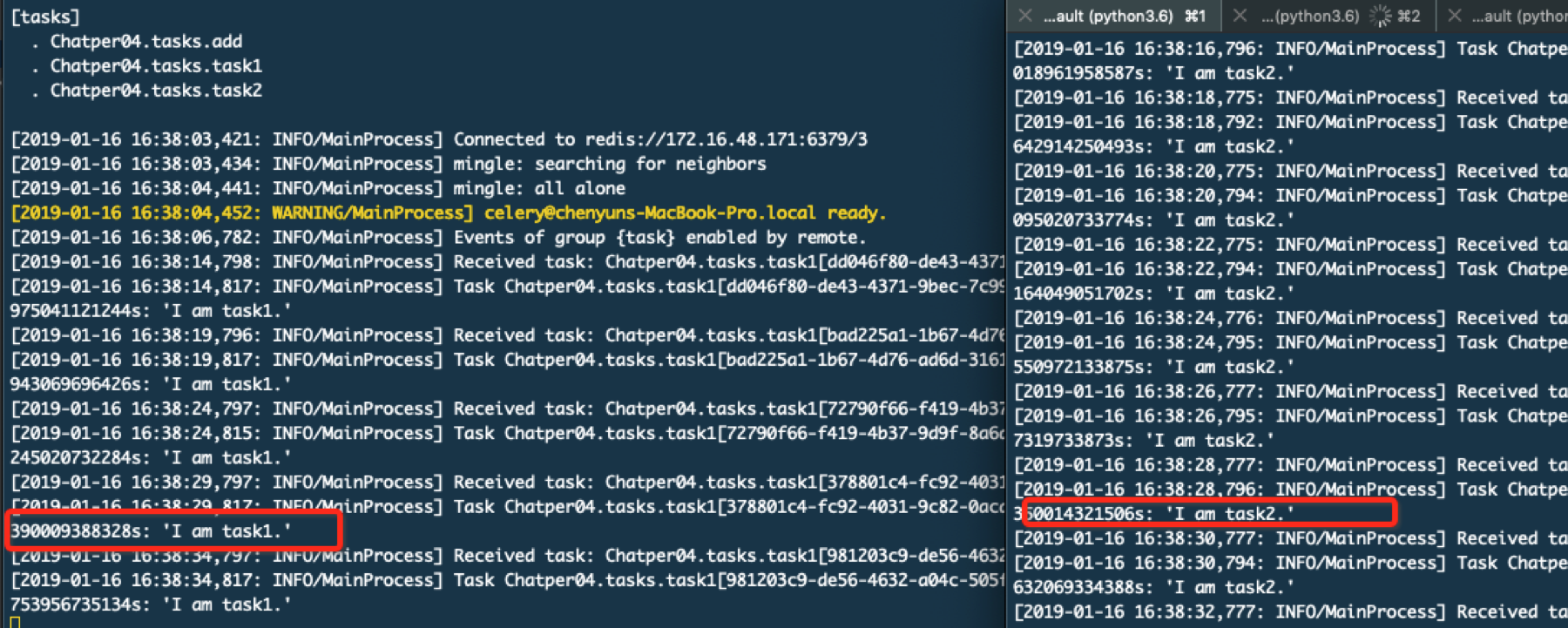
观察worker结果
在代码中如何调用呢?这种场景是注册任务,通过代码执行来触发执行具体任务,而不是通过定时任务的形式。tasks.py代码我们只去掉定时任务部分
执行的程序
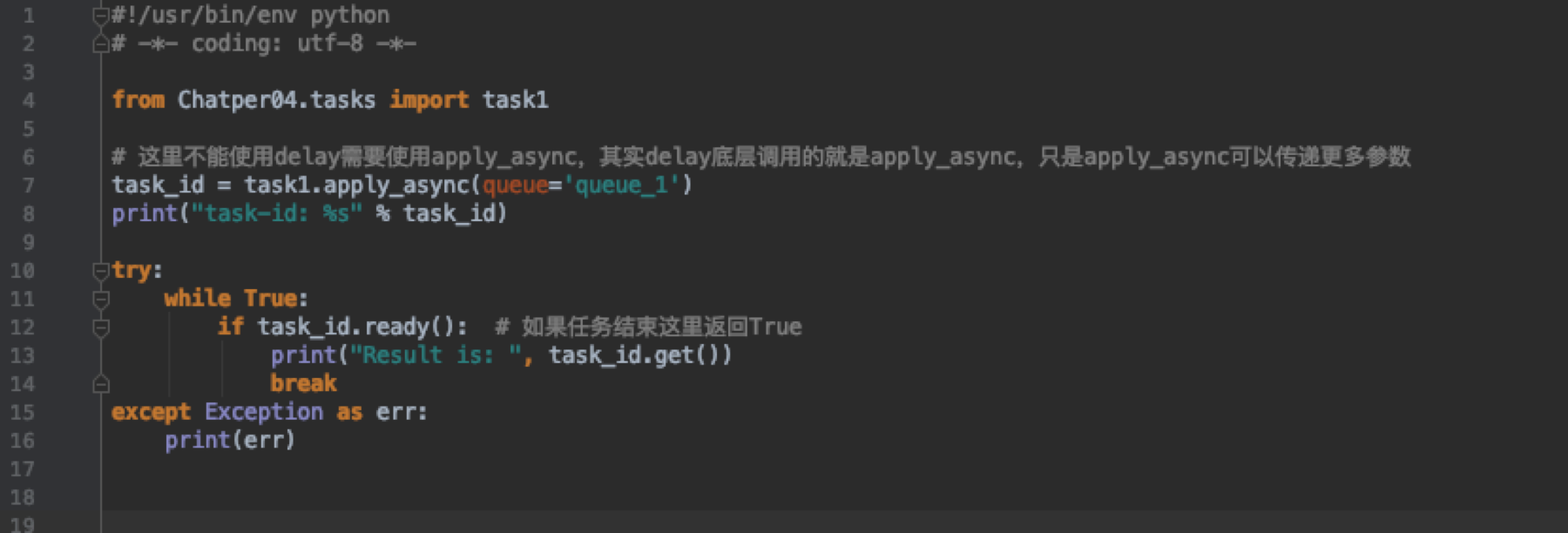
delay()方法是apply_sync()方法的别名,后者可以接受更多参数。
# countdown : 设置该任务等待一段时间再执行,单位为s;
# eta : 定义任务的开始时间;eta=time.time()+10;
# expires : 设置任务时间,任务在过期时间后还没有执行则被丢弃;
# retry : 如果任务失败后, 是否重试;使用true或false,默认为true
# shadow:重新指定任务的名字str,覆盖其在日志中使用的任务名称;
# retry_policy : 重试策略.
# max_retries : 最大重试次数, 默认为 3 次.
# interval_start : 重试等待的时间间隔秒数, 默认为 0 , 表示直接重试不等待.
# interval_step : 每次重试让重试间隔增加的秒数, 可以是数字或浮点数, 默认为 0.2
# interval_max : 重试间隔最大的秒数, 即 通过 interval_step 增大到多少秒之后, 就不在增加了, 可以是数字或者浮点数, 默认为 0.2 .
# routing_key:自定义路由键;
# queue:指定发送到哪个队列;
# exchange:指定发送到哪个交换机;
# priority:任务队列的优先级,0-9之间;
# serializer:任务序列化方法;通常不设置;
# compression:压缩方案,通常有zlib, bzip2
# headers:为任务添加额外的消息;
# link:任务成功执行后的回调方法;是一个signature对象;可以用作关联任务
task.apply_async((2,2),
compression='zlib',
serialize='json',
queue='priority.high',
routing_key='web.add',
priority=0,
exchange='web_exchange')