需求:在从银行数据库中取出 几十万数据时,需要对 每行数据进行相关操作,通过pandas的dataframe发现数据处理过慢,于是 对数据进行 分段后 通过 线程进行处理;
如下给出 测试版代码,通过 list 分段模拟 pandas 的 dataframe ;
1.使用 threading模块
1 # -*- coding: utf-8 -*- 2 # (C) Guangcai Ren <renguangcai@jiaaocap.com> 3 # All rights reserved 4 # create time '2019/6/26 14:41' 5 import math 6 import random 7 import time 8 from threading import Thread 9 10 _result_list = [] 11 12 13 def split_df(): 14 # 线程列表 15 thread_list = [] 16 # 需要处理的数据 17 _l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 18 # 每个线程处理的数据大小 19 split_count = 2 20 # 需要的线程个数 21 times = math.ceil(len(_l) / split_count) 22 count = 0 23 for item in range(times): 24 _list = _l[count: count + split_count] 25 # 线程相关处理 26 thread = Thread(target=work, args=(item, _list,)) 27 thread_list.append(thread) 28 # 在子线程中运行任务 29 thread.start() 30 count += split_count 31 32 # 线程同步,等待子线程结束任务,主线程再结束 33 for _item in thread_list: 34 _item.join() 35 36 37 def work(df, _list): 38 """ 线程执行的任务,让程序随机sleep几秒 39 40 :param df: 41 :param _list: 42 :return: 43 """ 44 sleep_time = random.randint(1, 5) 45 print(f'count is {df},sleep {sleep_time},list is {_list}') 46 time.sleep(sleep_time) 47 _result_list.append(df) 48 49 50 def use(): 51 split_df() 52 53 54 if __name__ == '__main__': 55 y = use() 56 print(len(_result_list), _result_list)
响应结果如下:
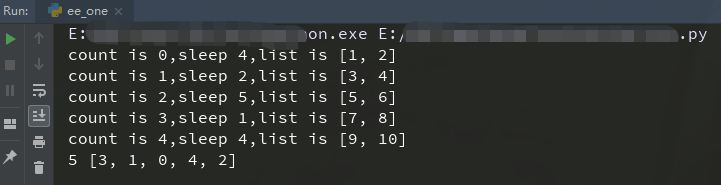
注意点:
脚本中的 _result_list 在项目中 要 放在 函数中,不能直接放在 路由类中,否则会造成 多次请求 数据 污染;
定义线程任务时 thread = Thread(target=work, args=(item, _list,)) 代码中的 work函数 和 参数 要分开,否则 多线程无效
注意线程数不能过多
2.使用ThreadPoolExecutor.map
# -*- coding: utf-8 -*- # (C) Guangcai Ren <renguangcai@jiaaocap.com> # All rights reserved # create time '2019/6/26 14:41' import math import random import time from concurrent.futures import ThreadPoolExecutor def split_list(): # 线程列表 new_list = [] count_list = [] # 需要处理的数据 _l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] # 每个线程处理的数据大小 split_count = 2 # 需要的线程个数 times = math.ceil(len(_l) / split_count) count = 0 for item in range(times): _list = _l[count: count + split_count] new_list.append(_list) count_list.append(count) count += split_count return new_list, count_list def work(df, _list): """ 线程执行的任务,让程序随机sleep几秒 :param df: :param _list: :return: """ sleep_time = random.randint(1, 5) print(f'count is {df},sleep {sleep_time},list is {_list}') time.sleep(sleep_time) return sleep_time, df, _list def use(): pool = ThreadPoolExecutor(max_workers=5) new_list, count_list = split_list() # map返回一个迭代器,其中的回调函数的参数 最好是可以迭代的数据类型,如list;如果有 多个参数 则 多个参数的 数据长度相同; # 如: pool.map(work,[[1,2],[3,4]],[0,1]]) 中 [1,2]对应0 ;[3,4]对应1 ;其实内部执行的函数为 work([1,2],0) ; work([3,4],1) # map返回的结果 是 有序结果;是根据迭代函数执行顺序返回的结果 # 使用map的优点是 每次调用回调函数的结果不用手动的放入结果list中 results = pool.map(work, new_list, count_list) print(type(results)) # 如下2行 会等待线程任务执行结束后 再执行其他代码 for ret in results: print(ret) print('thread execute end!') if __name__ == '__main__': use()
响应为:

3.使用 ThreadPoolExecutor.submit
1 # -*- coding: utf-8 -*- 2 # (C) Guangcai Ren <renguangcai@jiaaocap.com> 3 # All rights reserved 4 # create time '2019/6/26 14:41' 5 import math 6 import random 7 import time 8 from concurrent.futures import ThreadPoolExecutor 9 10 # 线程池list 11 pool_list = [] 12 13 14 def split_df(pool): 15 # 需要处理的数据 16 _l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 17 # 每个线程处理的数据大小 18 split_count = 2 19 # 需要的线程个数 20 times = math.ceil(len(_l) / split_count) 21 count = 0 22 for item in range(times): 23 _list = _l[count: count + split_count] 24 # 线程相关处理 25 # submit方法提交可回调的函数,并返回一个future实例;future对象包含相关属性 26 # 如: done(函数是否执行完成),result(函数执行结果),running(函数是否正在运行) 27 # 从而 可以在submit 后的代码中 查看 相关任务运行情况 28 # 此方法 执行数据的结果是无序的,如果需要得到有序的结果,需要 for循环 每个future实例(线程池),如 此脚本代码 29 f = pool.submit(work, item, _list) 30 pool_list.append(f) 31 count += split_count 32 33 34 def work(df, _list): 35 """ 线程执行的任务,让程序随机sleep几秒 36 37 :param df: 38 :param _list: 39 :return: 40 """ 41 sleep_time = random.randint(1, 5) 42 print(f'count is {df},sleep {sleep_time},list is {_list}') 43 time.sleep(sleep_time) 44 return sleep_time, df, _list 45 46 47 def use(): 48 pool = ThreadPoolExecutor(max_workers=5) 49 split_df(pool) 50 _result_list = [] 51 for item in pool_list: 52 result_tuple = item.result() 53 _result_list.append(result_tuple[1]) 54 return _result_list 55 56 57 if __name__ == '__main__': 58 _result_list = use() 59 print(len(_result_list), _result_list)
结果如下:
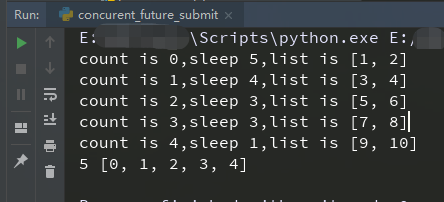
个人比较喜欢使用 第二中方法,代码写的少,返回的是有序结果,回调函数结果自动管理在generator中,直接for循环 map的结果即可;不用担心在 项目中多次请求数据污染问题
相关连接: