一、卷积
卷积神经网络(Convolutional Neural Networks)是一种在空间上共享参数的神经网络。使用数层卷积,而不是数层的矩阵相乘。在图像的处理过程中,每一张图片都可以看成一张“薄饼”,其中包括了图片的高度、宽度和深度(即颜色,用RGB表示)。
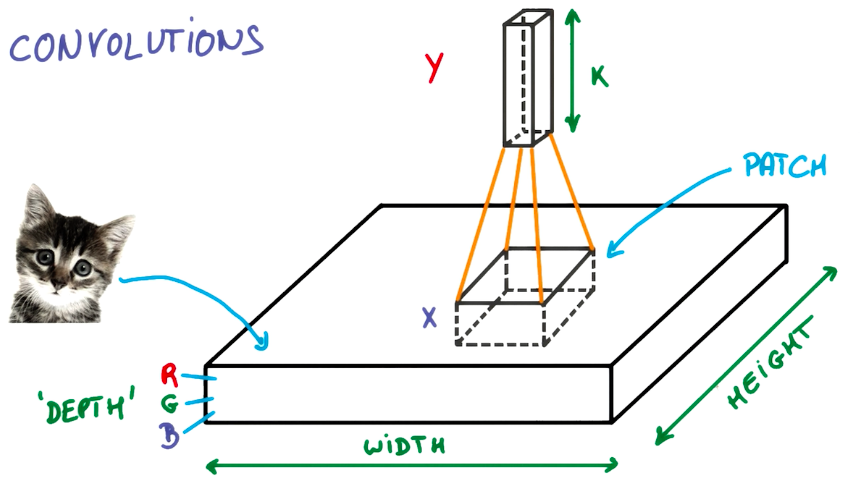
在不改变权重的情况下,把这个上方具有k个输出的小神经网络对应的小块滑遍整个图像,可以得到一个宽度、高度不同,而且深度也不同的新图像。
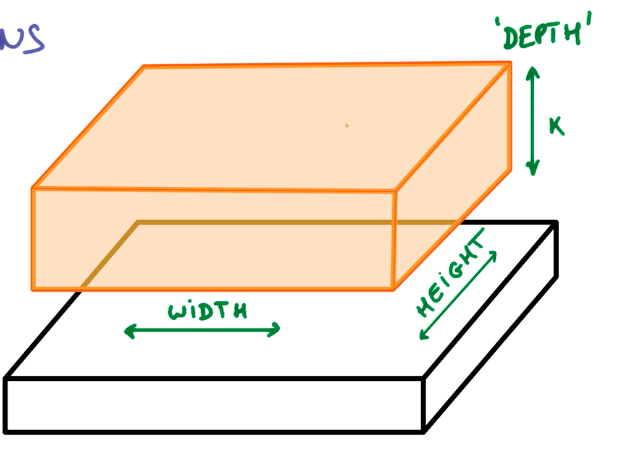
卷积时有很多种填充图像的方法,以下主要介绍两种,一种是相同填充,一种是有效填充。
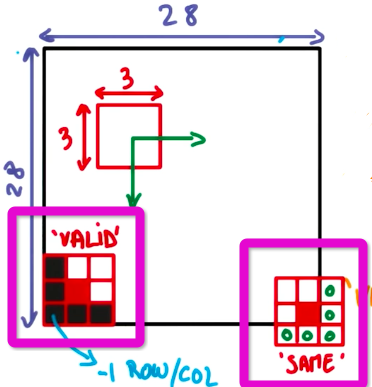
如图中紫色方框所示,左边是有效填充,右边是相同填充。在相同填充中,超出边界的部分使用补充0的办法,使得输入输出的图像尺寸相同。而在有效填充中,则不使用补充0的方法,不能超出边界,因此往往输入的尺寸大于输出的尺寸。
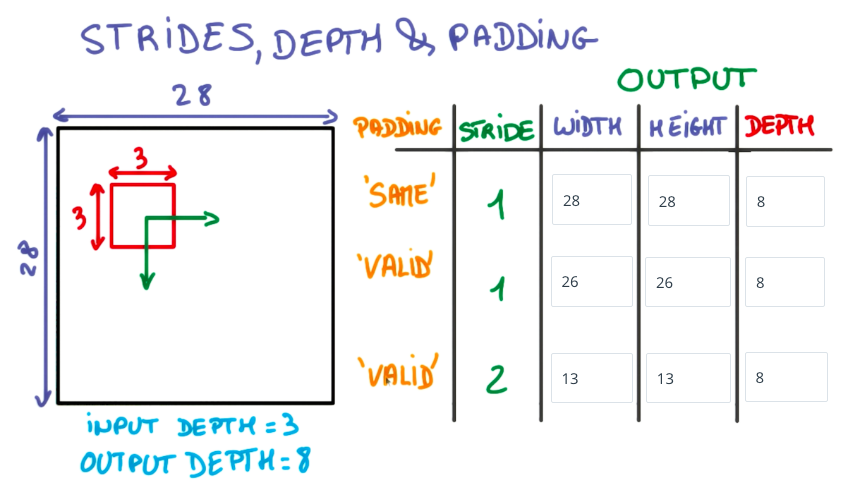
下图展示了以3x3的网格在28x28的图像上,使用不同步长、填充方法填充所得到的输出图像的尺寸:
下面借助两个动图来理解一下卷积的过程:
第一种是以3x3的网格在5x5的图像上进行有效填充的卷积过程:
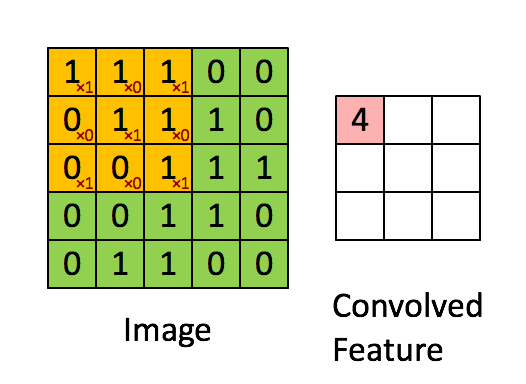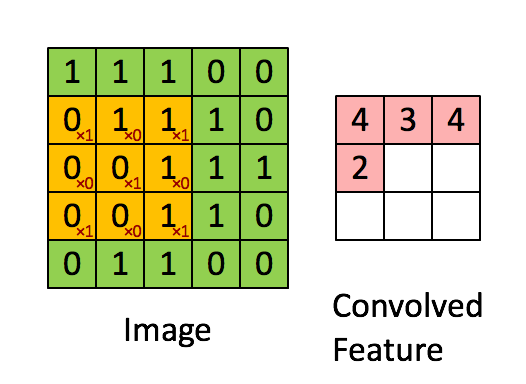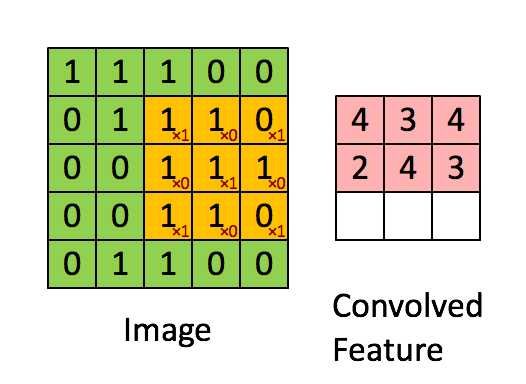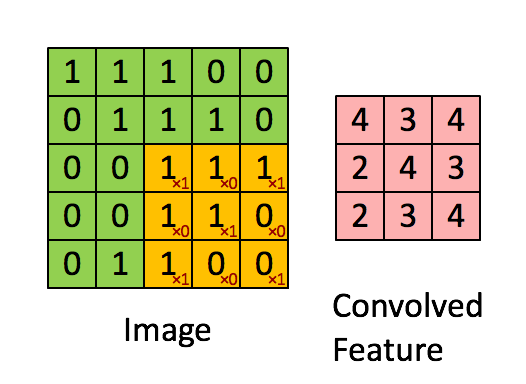
第二种是使用3x3的网格在5x5图像上进行相同填充的卷积过程,动图在:http://cs231n.github.io/convolutional-networks/
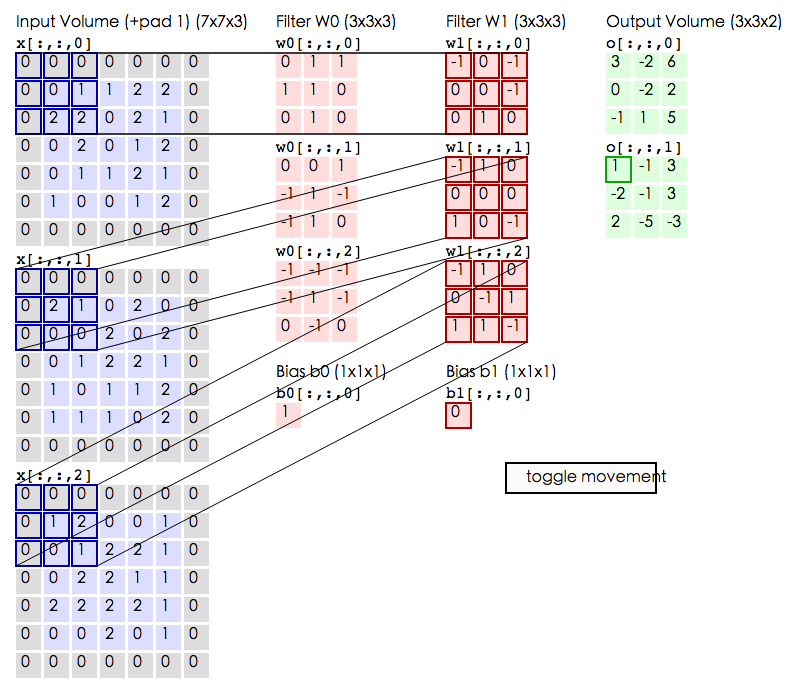
回顾整个过程,就是一层一层地增加网络深度,最终得到一个又深又窄的表示,然后把其连接到全连接层,然后训练分类器。

二、局部连接与权重共享
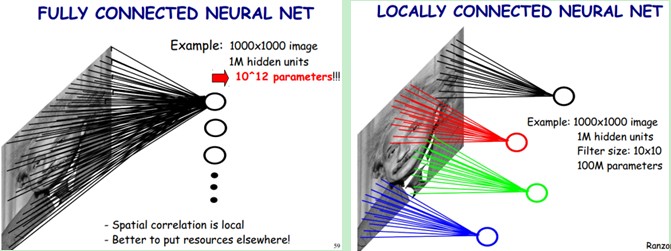
总体而言,局部连接和权重共享都是减少参数的办法,使得特征提取更为有效。
上图中左半部分,是全连接神经网络的示例。图中是一个1000x1000的图像,下一隐藏层有$10^6$个神经元,那么就会有1000x1000x$10^6$=$10^{12}$个参数。
上图右半部分,是局部连接神经网络的示例。图中依然是一个1000x1000的图像,下一隐藏层有$10^6$个神经元,但是使用了一个10x10的卷积核,连接到了10x10的局部图像,那么则会有10x10x$10^6$=$10^8$个参数。
可见局部连接可以很大幅度减少参数的数量。
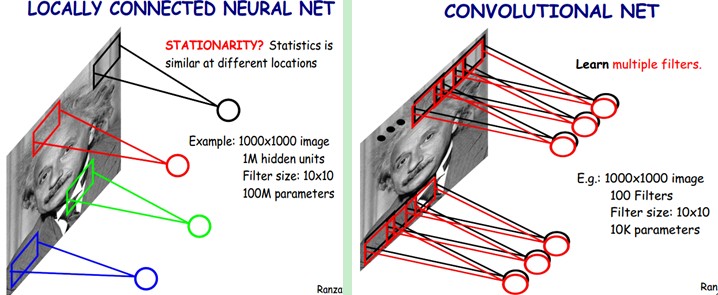
在实际应用中,有一些情况比较特殊,涉及到了统计不变性的问题。比如我们想识别图像中的动物类别,那么动物在图片中的位置(左上角、中间或是右下角)是不重要的,这叫平移不变性;再比如说,在识别数字的过程中,数字的颜色并不影响结果;又或者说,在语言处理中,一些词汇在句子中的位置并不影响其代表的含义。当两种输入可以获得同样的信息,那么我们就应该共享权重而且利用这些输入来共同训练权重。
在上图中的左半部分,是未使用权重共享的局部连接神经网络的示例。
在上图中的右半部分,则使用了权重共享。图中是一个1000x1000的图像,有100个10x10的卷积核,最终会有100x10x10=10k个参数。使用局部连接和权重共享都大大地减小了参数数量。而共享权重使得统计不变性问题得到了有效解决。
三、池化
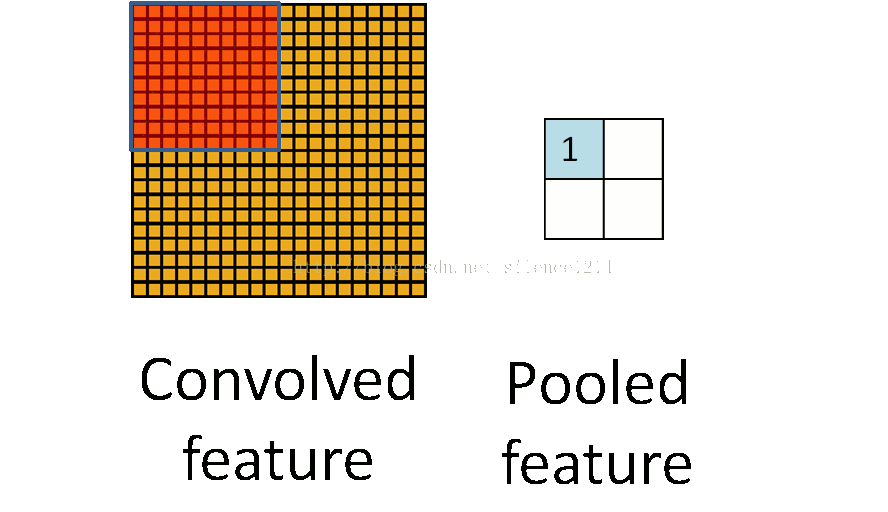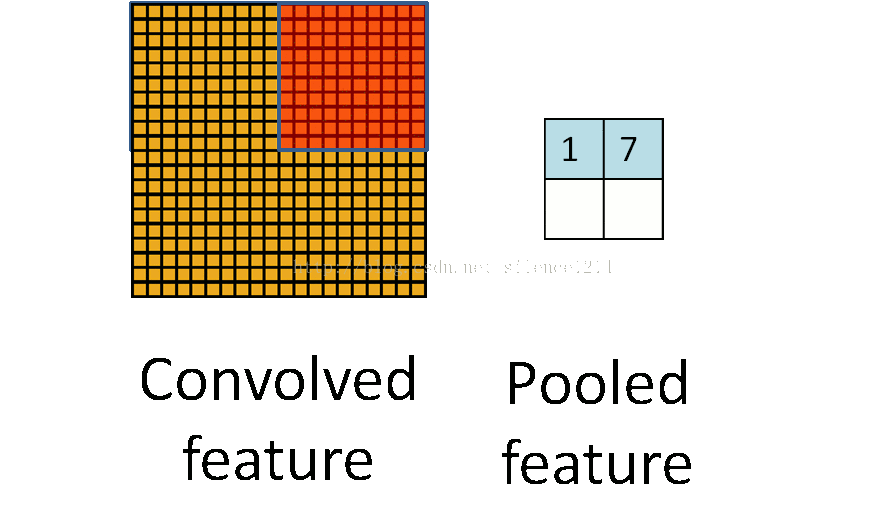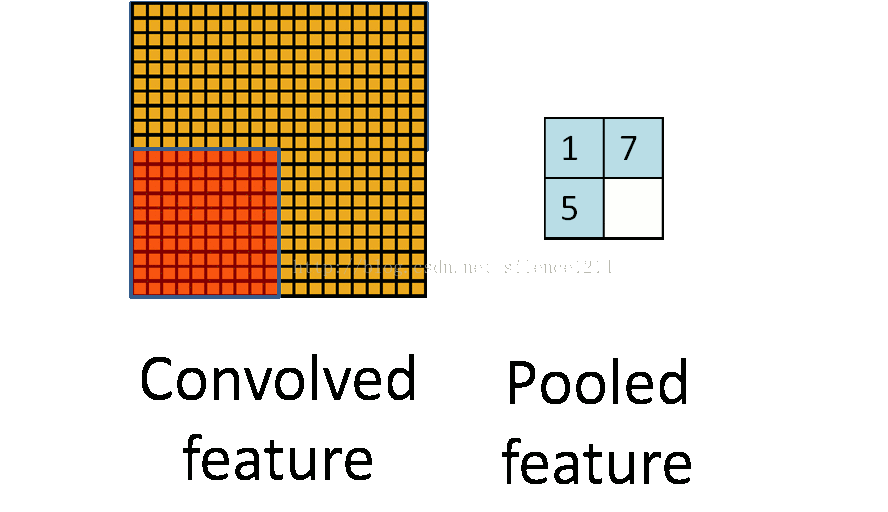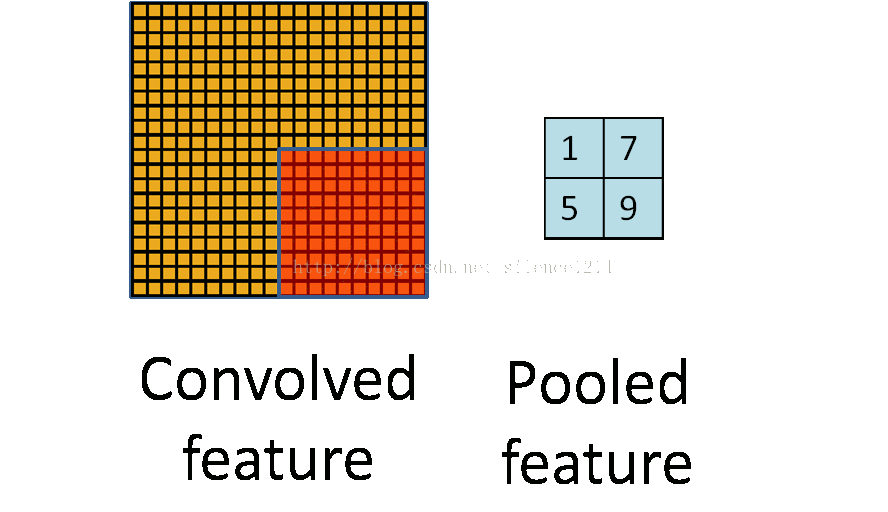
通过卷积后,为了引入不变性,同时防止过拟合问题或欠拟合问题、降低计算量,我们常进行池化处理。池化过程如上图所示。因此池化过后,通常图像的宽度和高度会变成原来的1/2。
其中包括了Max pooling 、 Mean pooling和Stochastic pooling三种池化方法。
两种较为常用的是:Max pooling和Mean pooling。Max pooling是选择kernel范围之内的最大值;Mean pooling则是选择kernel范围之内的平均值。
四、LeNet-5中的卷积与池化分析
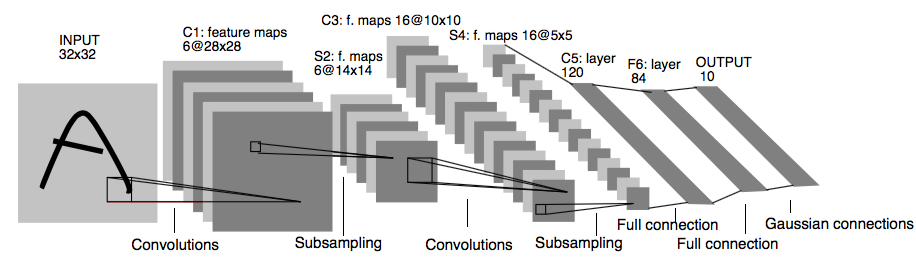
在LeNet-5中,输入层是32x32的尺寸。
在第一次卷积中,使用了6个卷积核,得到了C1:6张28x28的特征图。
然后进行下采样,得到S2:特征图宽、高变为原来的1/2,即28/2=14,特征图尺寸变为14x14,特征图张数不变。
再进行第二次卷积,使用了16个卷积核,得到了C3:16张10x10的特征图。
然后进行下采样,得到S4:特征图宽、高变为原来的1/2,即10/2=5,特征图尺寸变为5x5,特征图张数不变。
之后进入卷积层C5,120张1x1全连接后的特征图,与S4全连接。
本文图片及内容均参考或来自如下资料:
[1]Udacity的Deep Learning课程:https://cn.udacity.com/course/deep-learning--ud730
[2]Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Deep Convolutional Neural Networks[J]. Advances in Neural Information Processing Systems, 2012, 25(2):2012.
[3]Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11):2278-2324.
[5]http://www.jeyzhang.com/cnn-learning-notes-1.html
[6]http://blog.csdn.net/stdcoutzyx/article/details/41596663
[7]CS231n: Convolutional Neural Networks for Visual Recognition
[8]http://ibillxia.github.io/blog/2013/04/06/Convolutional-Neural-Networks/
本文是个人的学习笔记,水平有限,如有疏漏,敬请指出,不胜感谢。