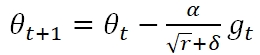AdaGrad全称是Adaptive Gradient Algorithm,是标准Gradient Descent的又一个派生算法。标准Gradient Descent的更新公式为:
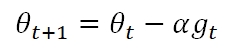
其中Learning Rate α对于Cost Function的各个feature都一样,但同一个α几乎不可能在各个feature上都表现完美,通常为了收敛,会选择较小的α。
而AdaGrad的主要思想是:在各个维度上使用不同的learning rate,从而加快函数收敛的速度。其公式为:
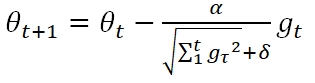
gt是t时刻目标函数的梯度,可以看到,依旧为各个feature设置了统一的α,但是通过历史梯度累计RMS作为分母来调节该learning rate。δ是一个很小的数例如10-7,仅仅为了分母不为0。
如果我们将等式右侧第二项看做一个整体。则标准Gradient Descent是,对t时刻梯度大的feature更新步子大,对t时刻梯度小的feature更新步子小。可以说Gradient Descent是衡量绝对大小的,但AdaGrad则不同,采取了“相对大与相对小”。使用当前时刻的梯度与历史梯度的RMS相比较,如果梯度变缓了,说明快要收敛了,那么步子调整的小一些;而如果梯度突然变大了,那证明参数需要大幅度更新了。
单AdaGrad算法虽然在凸函数(Convex Functions)上表现较好,但在非凸函数上却可能有局限。在深度学习训练中,Cost Function有可能会是很复杂的空间结构,有可能在某些平缓的结构上使用了很小的steps,但在某一时刻却有希望增大步伐。但上式的分母表示,优化的更新步伐和t时刻之前的所有时刻的梯度都相关,所以很有可能当算法希望增大步伐时,更新幅度已经衰减到很小,从而导致优化过程被困在某个局部最优点。
基于此,多大的Hinton教授提出了RMSProp,将AdaGrad和EMA结合起来。将上式分母的部分做成滑动的窗口,通过参数ρ来控制窗口的大小。从而,梯度的“相对大小”参照物,会丢弃遥远的历史,只与相邻窗口内的结构进行比较,来决定更新步幅的大小。梯度的EMA等于:
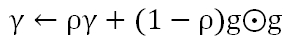
参数更新公式为: