一、概述
背景:我们的数据库一般都会并发执行多个事务,多个事务可能会并发的对相同的一批数据进行增删改查操作,可能就会导致我们说的脏写、脏读、不可重复读、幻读这些问题。
本质:数据库的多事务并发问题
应对措施:
- 事务隔离机制
- 锁机制
- MVCC多版本并发控制隔离机制
二、事务及其ACID属性
ACID是什么?
事务是由一组SQL语句组成的逻辑处理单元,事务具有以下4个属性,通常简称为事务的ACID属性。
- 原子性(Atomicity) :事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
- 一致性(Consistent) :在事务开始和完成时,数据都必须保持一致状态。
- 隔离性(Isolation) :数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
- 持久性(Durable) :事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
PS:原子性和一致性类似,原子性主要针对于操作,一致性主要针对数据。
并发事务处理带来的问题
脏写/更新丢失(Lost Update)
当多个事务选择同一行进行操作,并基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题。
一句话总结:最后的更新覆盖了由其他事务所做的更新。
-- 库存扣减时,库存在代码里算好然后直接执行sql语句【举个例子原来库存是10】 -- A事务【count = 10 - 1 = 9】: update t_gds_stock set stock_count = 9; -- B事务【count = 10 - 5 = 5】: update t_gds_stock set stock_count = 5; -- 执行完毕后,库存为5,而正确的库存应该为10 - 1 - 5 = 4
PS:涉及到类似减库存的这种操作,不要在java代码里面做,而是用数据库来控制。
脏读(Dirty Reads)
一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致的状态;这时另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”数据,并作进一步的处理,就会产生对未提交数据的依赖关系,这种现象被称为“脏读”。此时,如果B事务回滚,A读取的数据就无效了,这不符合一致性要求。
一句话总结:事务A读取到了事务B已经修改但尚未提交的数据,还在这个数据基础上做了操作。
-- 库存扣减时,下单异常库存回滚 -- 第1步 A事务进行库存扣减后【未commit】: update t_gds_stock set stock_count = 9; -- 第2步 B事务读取到A事务更新后的库存,并运算 update t_gds_stock set stock_count = 9 - 5; -- 第3步 A事务异常并回滚 A:roll back; -- 执行完毕后,库存为4,而正确的库存应该为10 - 5 = 5
不可重读(Non-Repeatable Reads)
一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了!这种现象就叫做“不可重复读”。
一句话总结:事务A内部的相同查询语句在不同时刻读出的结果不一致,不符合隔离性。
-- B、C事务正在修改库存,而A事务在一个事务内多次查询库存的结果不一样 -- 第1步 A事务进行库存查询【查询结果:10】: select stock_count from t_gds_stock; -- 第2步 B事务修改库存 update t_gds_stock set stock_count = 10 - 5; -- 第3步 A事务执行同样的语句【查询结果:5】: select stock_count from t_gds_stock; -- 第4步 C事务修改库存 update t_gds_stock set stock_count = 5 - 3; -- 第5步 A事务执行同样的语句【查询结果:2】: select stock_count from t_gds_stock; -- 执行完毕后,A事务一脸懵圈,到底应该用哪个库存呀,相当不好写代码呀!
PS:我们至少需要保证在同一个事务内,同一个数据多次查询的结果是一致的,而真正去操作数据库的时候再用最新的真实数据来更新,这样我们的代码才好控制逻辑【最终一致】
幻读(Phantom Reads)
一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读”。
一句话总结:事务A读取到了事务B提交的新增数据,不符合隔离性。
-- A事务进行库存分仓查询,此时B事务新增了一条记录,A事务再次查询的时候查出了B事务新增的数据 -- 第1步 A事务进行库存查询【查询结果:3条记录】: select * from t_gds_stock; -- 第2步 B事务新增数据 insert into t_gds_stock VALUES (4,'新增的商品',SYSDATE()); -- 第3步 A事务再次进行库存查询【查询结果:4条记录】: select * from t_gds_stock; -- 执行完毕后,A事务一脸懵圈,怎么回事跟刚才的查询结果不一样,有点慌啊...
事务隔离级别
MySQL默认事务级别:repeatable-read【可重复读】
“脏读”、“不可重复读”和“幻读”,其实都是数据库读一致性问题,需要由数据库提供一定的事务隔离机制来解决。
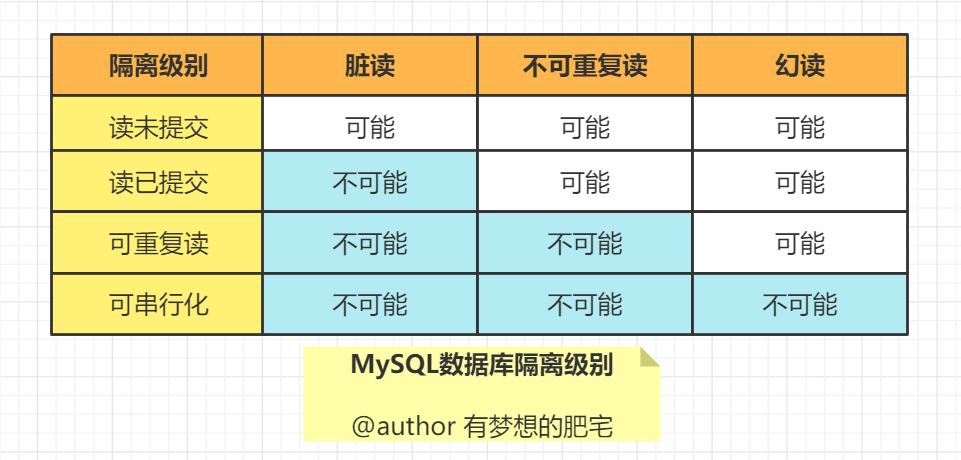
PS:数据库的事务隔离越严格,并发影响越小,但性能开销也就越大。
-- 查看当前数据库的事务隔离级别【8.0+版本】【下面2条语句都可以查】 select @@transaction_isolation; show variables like 'transaction_isolation'; -- 设置read uncommitted级别: set session transaction isolation level read uncommitted; -- 设置read committed级别: set session transaction isolation level read committed; -- 设置repeatable read级别: set session transaction isolation level repeatable read; -- 设置serializable级别: set session transaction isolation level serializable;
PS:Mysql默认的事务隔离级别是可重复读,用Spring开发程序时,如果不设置隔离级别默认用Mysql设置的隔离级别,如果Spring设置了就用已经设置的隔离级别。
三、数据库锁
定义:锁是计算机协调多个进程或线程并发访问某一资源的机制。
锁的分类
从性能上分:乐观锁和悲观锁
-- 乐观锁【用一个字段version来标示版本号,更新的时候需要带上并对比】 update t_gds_stock set stock_count = 5 where version = 1; -- 悲观锁【for update语句】 -- 1、开启事务 begin; -- 2、for update 语句【此时会上锁,其他事务要操作的时候,就会暂时阻塞】 select stock_count from t_gds_stock for update;
从对数据库操作的类型分:读锁和写锁
- 读锁(共享锁,S锁(Shared)):针对同一份数据,多个读操作可以同时进行而不会互相影响【别的事务可以读,不可以写】
- 写锁(排它锁,X锁(eXclusive)):当前写操作没有完成前,它会阻断其他写锁和读锁。【不让别的事务读写】
PS:读锁和写锁都属于悲观锁。
从对数据操作的粒度分:表锁和行锁
表锁
定义:每次操作锁住整张表。
特点:开销小,加锁快,不会出现死锁,锁定粒度大,发生锁冲突的概率最高,并发度最低。
PS: 一般用在整表数据迁移时,不让业务进行数据变更的场景。
-- 手动增加表锁【lock table t_user read/write; 】 lock table t_user read; -- 查看表上加过的锁 show open tables; -- 删除表锁 unlock tables;
行锁
定义:每次操作锁住一行数据。
特点:开销大,加锁慢,会出现死锁,锁定粒度最小,发生锁冲突的概率最低,并发度最高。
PS: InnoDB与MyISAM的最大不同有两点:
- InnoDB支持事务
- InnoDB支持行级锁
小结
表锁:InnoDB与MyISAM都有
行锁:InnoDB有,MyISAM没有
MyISAM
- 在执行查询语句SELECT前,会自动给涉及的所有表加读锁,在执行update、insert、delete操作会自动给涉及的表加写锁。【读写都加锁】
InnoDB
- 在执行查询语句SELECT时(非串行隔离级别),不会加锁。
- 但是update、insert、delete操作会加行锁。
简而言之,就是读锁会阻塞写,但是不会阻塞读。而写锁则会把读和写都阻塞。
四、间隙锁(Gap Lock)
定义:间隙锁,锁的就是两个值之间的空隙。
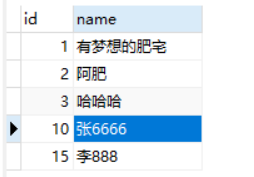
如上图,间隙区间有:(3,10)、(10,15)、(15,+无穷)
场景分析
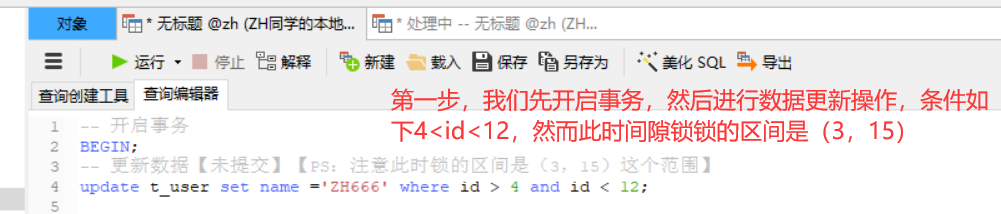
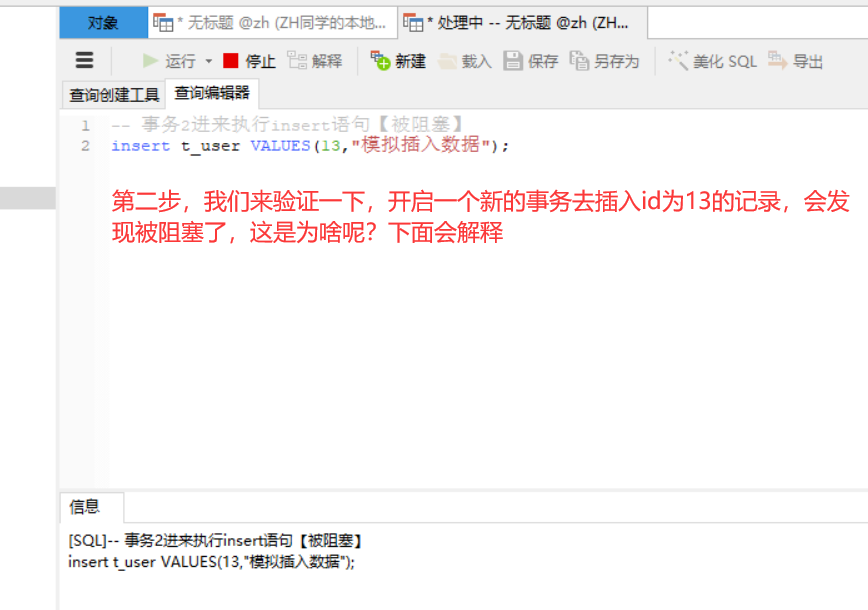
案例解析
在事务1下面执行
-- 开启事务 BEGIN; -- 更新数据【未提交】【PS:注意此时锁的区间是(3,15)这个范围】 update t_user set name ='ZH666' where id > 4 and id < 12;
则其他Session没法在这个范围所包含的所有行记录(包括间隙行记录)以及行记录所在的间隙里插入或修改任何数据,即id在(3,15)区间都无法新增修改数据。
PS:间隙锁是在可重复读隔离级别下才会生效。
五、使用锁时的一些注意事项
无索引行锁会升级为表锁
锁主要是加在索引上,如果对非索引字段更新,行锁可能会变表锁。
-- 事务1:【name字段没有加索引】 begin; update t_user set name ='有梦想的肥宅' where name='ZH'; -- 事务2 对表的任一操作都会被阻塞【写操作】
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁。
PS:作为条件时该索引不能失效,否则都会从行锁升级为表锁。
事务级别尽量不要设置可串行化
事务在可串行化级别下,连select语句也会枷锁,效率非常低,一般我们用默认的级别【可重复读】就够了,在更新数据的时候再用sql的真实值去更新就好了。
尽可能的避免join语句
一定要尽可能的避免join语句,首先join语句非常难优化,一般的互联网公司也是禁止这样玩的。
一旦使用了Join语句,性能上面非常难以优化,且后期如果需要分库分表也会有很大的问题。
一些锁的优化建议
- 尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁
- 合理设计索引,尽量缩小锁的范围
- 尽可能减少检索条件范围,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度,涉及事务加锁的sql尽量放在事务最后执行
- 尽可能低级别事务隔离
六、小问答
Q:为什么行锁开销大,加锁慢,而表锁则相反呢?
表锁只需要通过简单的lock语句就可以对一张表上锁了,而行锁还需要定位到对应的行才可以进行上锁。
Q:如何手动开启事务?【默认是自动commit的】
-- 1、显式声明开启事务 begin; -- 2、输入需要执行的sql语句 update t_user set name ='有梦想的肥宅' where name='ZH'; -- 3、提交事务 commit;