一、搭建一个本地伪集群
前面我们学习了搭建单台kafka实例的步骤,现在为了方便,我们直接在本机windows系统上搭建我们的伪集群来方便我们学习,步骤如下:
1、复制3份kafka实例

2、分别修改3个brocker的配置文件【server.properties】内容
PS:要把多个kafka实例组成集群,对应连接的zookeeper必须相同。【组建集群实际上只要zk地址配置一样就可以了】
PS:内网间一般不配置SSL账号密码,因为如果配置了那么性能会下降。
【kafka1】 #broker实例ID broker.id=0 #监听9092端口 listeners=PLAINTEXT://:9092 #数据存放路径 log.dirs=/kafka/kafka1/zhlogs #kafka连接zookeeper的地址 zookeeper.connect=localhost:2181 【kafka2】 #broker实例ID broker.id=1 #监听9093端口 listeners=PLAINTEXT://:9093 #数据存放路径 log.dirs=/kafka/kafka2/zhlogs #kafka连接zookeeper的地址 zookeeper.connect=localhost:2181 【kafka3】 #broker实例ID broker.id=2 #监听9094端口 listeners=PLAINTEXT://:9094 #数据存放路径 log.dirs=/kafka/kafka3/zhlogs #kafka连接zookeeper的地址 zookeeper.connect=localhost:2181
3、分别启动3个brocker实例


二、集群消费原理
log的partitions分布在kafka集群中不同的broker上,每个broker可以请求备份其他broker上partition上的数据。
针对每个partition,都有一个broker起到“leader”的作用,0个或多个其他的broker作为“follwers”的作用。
leader处理所有的针对这个partition的读写请求,而followers被动复制leader的结果,不提供读写【主要是为了保证多副本数据与消费的一致性】。如果这个leader失效了,其中的一个follower将会自动的变成新的leader。
PS:brocker之间是没有Leader和follower相关的概念的,只有到分区这个级别才有这个概念。
Producers
生产者将消息发送到topic中去,同时负责选择将message发送到topic的哪一个partition中。通过round-robin做简单的负载均衡。也可以根据消息中的某一个关键字来进行区分。
Consumers
消息传递模式
传统的消息传递模式有2种:队列模式和发布订阅模式。
- queue【队列模式】:多个consumer从服务器中读取数据,消息只会到达一个consumer。
- publish-subscribe【发布订阅模式】:消息会被广播给所有的consumer。
消费者组【consumer group】
Kafka基于这2种模式提供了一种consumer的抽象概念:consumer group。
- queue【队列模式】:所有的consumer都位于同一个consumer group下。
- publish-subscribe【发布订阅模式】:consumer位于不同consumer group下。
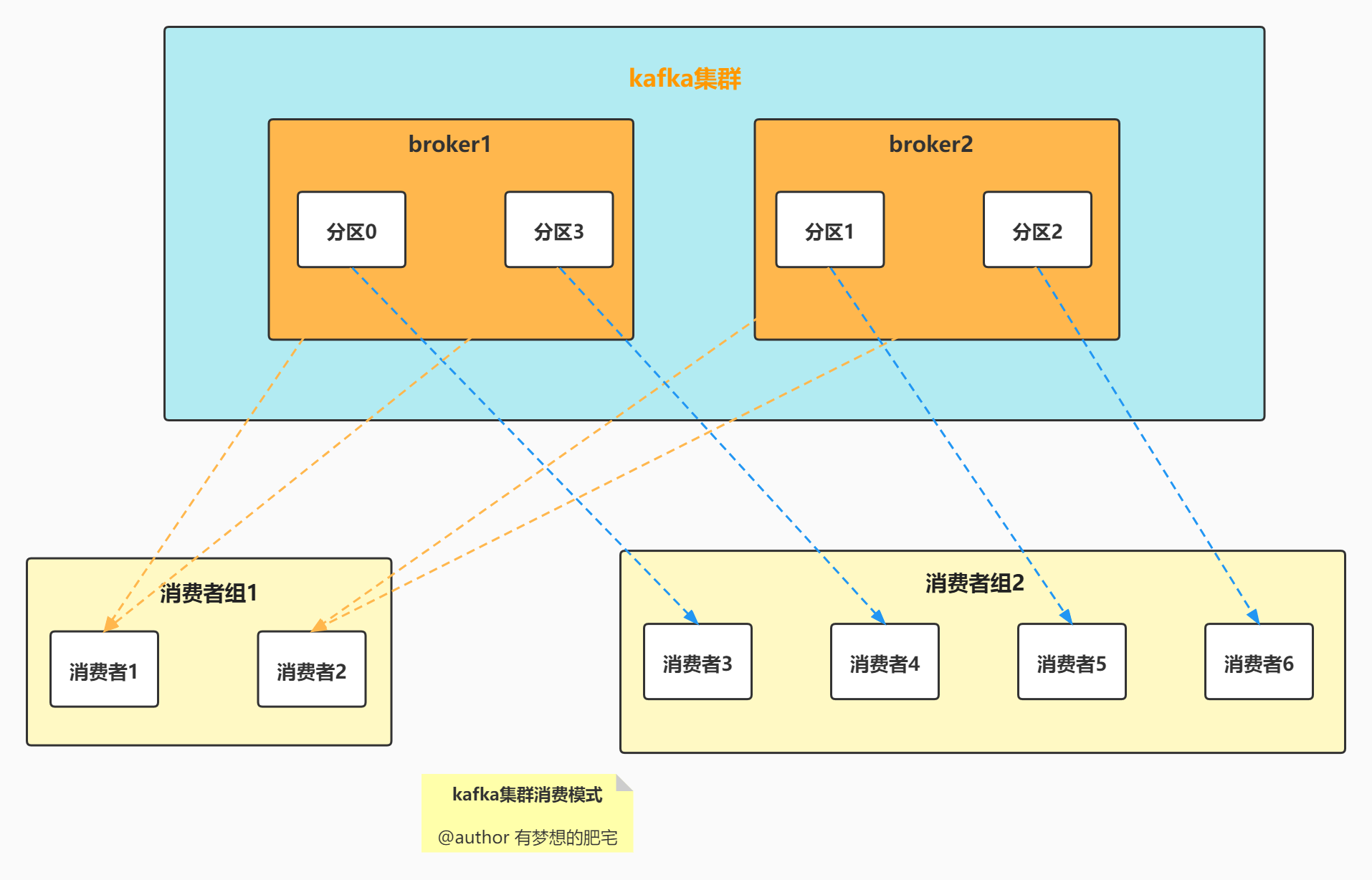
解析:
- 上图由2个broker组成的kafka集群,某个主题总共有4个partition【分区0~分区3】,分别位于不同的broker上。
- 这个集群由2个Consumer Group【消费者组】消费, A有2个消费者实例 ,B有4个。
- 通常一个topic会有几个consumer group,每个consumer group都是一个逻辑上的订阅者( logical subscriber )。
- 每个消费者组由多个消费者实例组成,从而达到可扩展和容灾的功能。
消费顺序:
一个partition同一个时刻在一个consumer group中只能有一个consumer instance【消费者实例】在消费,从而保证消费顺序。
PS:消费者组中的消费者实例的数量不能比一个Topic中的partition的数量多,否则多出来的 consumer消费不到消息。
PS:Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性。