part1:
【转】https://blog.csdn.net/weixin_40165004/article/details/89080968
Weka数据预处理(一)
对于数据挖掘而言,我们往往仅关注实质性的挖掘算法,如分类、聚类、关联规则等,而忽视待挖掘数据的质量,但是高质量的数据才能产生高质量的挖掘结果,否则只有"Garbage in garbage out"了。保证待数据数据质量的重要一步就是数据预处理(Data Pre-Processing),在实际操作中,数据准备阶段往往能占用整个挖掘过程6~8成的时间。本文就weka工具中的数据预处理方法作一下介绍。
Weka的数据预处理又叫数据过滤,他们可以在weka.filters中找到。根据过滤算法的性质,可以分为有监督的(SupervisedFilter)和无监督的(UnsupervisedFilter)。对于前者,过滤器需要设置一个类属性,要考虑数据集中类的属性及其分布,以确定最佳的容器的数量和规模;而后者类的属性可以不存在。同时,这些过滤算法又可归结为基于属性的(attribute)和基于实例的(instance)。基于属性的方法主要是用于处理列,例如,添加或删除列;而基于实例的方法主要是用于处理行,例如,添加或删除行。
数据过滤主要解决以下问题(老生常谈的):
数据的缺失值处理、标准化、规范化和离散化处理。
数据的缺失值处理:weka.filters.unsupervised.attribute.ReplaceMissingValues。对于数值属性,用平均值代替缺失值,对于nominal属性,用它的mode(出现最多的值)来代替缺失值。
标准化(standardize):类weka.filters.unsupervised.attribute.Standardize。标准化给定数据集中所有数值属性的值到一个0均值和单位方差的正态分布。
规范化(Nomalize):类weka.filters.unsupervised.attribute.Normalize。规范化给定数据集中的所有数值属性值,类属性除外。结果值默认在区间[0,1],但是利用缩放和平移参数,我们能将数值属性值规范到任何区间。如:但scale=2.0,translation=-1.0时,你能将属性值规范到区间[-1,+1]。
离散化(discretize):类weka.filters.supervised.attribute.Discretize和weka.filters.unsupervised.attribute.Discretize。分别进行监督和无监督的数值属性的离散化,用来离散数据集中的一些数值属性到分类属性。
part2:
【转】https://blog.csdn.net/u014381464/article/details/81101551
规范化:
针对数据库
规范化把关系满足的规范要求分为几级,满足要求最低的是第一范式(1NF),再来是第二范式、第三范式、BC范式和4NF、5NF等等,范数的等级越高,满足的约束集条件越严格。
针对数据
数据的规范化包括归一化标准化正则化,是一个统称(也有人把标准化作为统称)。
数据规范化是数据挖掘中的数据变换的一种方式,数据变换将数据变换或统一成适合于数据挖掘的形式,将被挖掘对象的属性数据按比例缩放,使其落入一个小的特定区间内,如[-1, 1]或[0, 1]
对属性值进行规范化常用于涉及神经网络和距离度量的分类算法和聚类算法当中。比如使用神经网络后向传播算法进行分类挖掘时,对训练元组中度量每个属性的输入值进行规范化有利于加快学习阶段的速度。对于基于距离度量相异度的方法,数据归一化能够让所有的属性具有相同的权值。
数据规范化的常用方法有三种:最小最大值规范化,z-score标准化和按小数定标规范化
标准化(standardization):
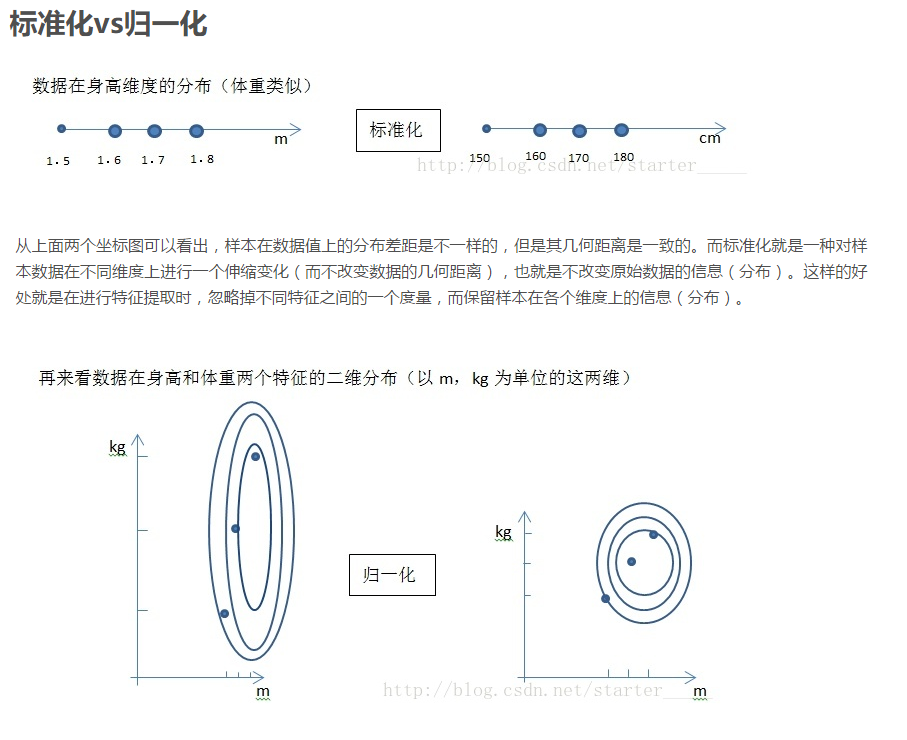
数据标准化是将数据按比例缩放,使其落入到一个小的区间内,标准化后的数据可正可负,但是一般绝对值不会太大,一般是z-score标准化方法:减去期望后除以标准差。
归一化(normalization):
把数值放缩到0到1的小区间中(归到数字信号处理范畴之内),一般方法是最小最大规范的方法:min-max normalization
part.3
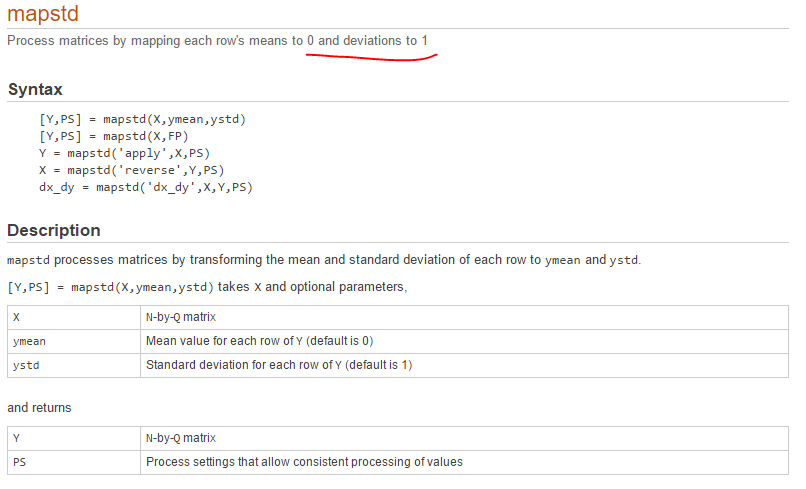
matlab上函数
part.4 公式


其他:
weka算法源代码获取方式:https://blog.csdn.net/renyiniki/article/details/79668870
1.首先官网上下载weka源码,有两种方式,一种是下载安装文件,安装后在安装目录中会有一个 weka-src.jar ,解压后即为源码,另一种是通过SVN下载: https://svn.cms.waikato.ac.nz/svn/weka/trunk/weka 机子上需要SVN工具如:TortoiseSVN
2.导入myeclipse
2.1 创建工作目录。新建一个weka目录。
2.2 准备源代码。在weka的安装目录中找到weka-src.jar,解压缩到刚才建的目录下。
2.3 创建项目。打开MyEclipse,File->New->Java Project,Project name填weka,选择create project from existing source,点击next,点击finish。
2.4 编译运行。选择刚创建的项目weka,run as Java Application,等待弹出对话框选择主类,weka.gui.main(输入main即可看到)。不一会,weka界面出现。