【摘要】 本文提出了一种通过引入内存数据库层,建立两层多分区分布式数据库架构。此方案用于解决海量高并发系统的数据存储和访问问题,尤其适用于电子商务等数据模型复杂且业务复杂的互联网站。
这些年互联网站发展迅猛,为应对海量数据下的高并发访问,产生了各种分布式架构设计思想,例如Key-Value引擎,数据分区等。而对于电子商务类网站,海量数据问题还有一个重要特点,就是数据结构化及数据之间的关联,淘宝如此,阿里巴巴也是如此,这是与社区、视频、 博客等互联网站的显著差异。
1. NoSQL 是灵丹妙药吗?
NoSQL、Key-Value引擎如BigTable、Cassendra等在很多大型网站被采用,很好的解决了海量数据存储和访问问题。而对于电子商务类网站,Key-Value和NoSQL并不是解决此问题的灵丹妙药。最多它们仅能用于一些数据模型较为简单的应用。
原因有两个方面:
1)数据模型复杂
淘宝和阿里巴巴的会员、宝贝、供求、订单等核心实体数据模型复杂,属性个数几十到上百个。例如:会员(Member)就包含基本信息、联系、工商、账户等多个域的信息;另外,核心实体之间,外围实体与核心实体之间还存在复杂的关联。
2)业务复杂:
模型的复杂源于业务和逻辑的复杂。电子商务网站大量查询场景是结构化查询,例如:
在淘宝上查询“卖家在江浙沪,价格在50-200元的男士T恤”,
在阿里巴巴上“列出某个会员所有待发货的订单”
这类查询(当然,阿里巴)主要针对多个非主键字段, 即便对于BigTable、Cassandra 这样的基于Column的Key-Value数据库,其简单的Query API还无法胜任此类需求。 因此在阿里巴巴和淘宝,Oracle、MySQL 等关系数据库将仍然扮演重要角色。
2. MySQL 集群
引入K-V引擎等非关系数据库无非是要解决海量数据在高并发环境下的高效读写问题,最大程度在可靠的持久化(Durable)与高访问性能 (Performance) 之间选择一个平衡点。在高度结构化系统中,同样的考虑驱使我们需要考虑另外的解决方案。
目前一种通行的做法是 MySQL 读写分离式集群,1个或少数Master写,多数Slave读,Master与Slave进行变更数据的同步。首先,这种方案经过大量的实践,可靠且可行。
然而,直接向DB执行写操作,仍然比较耗时(参见表1,表2),数据复制,也可能存在不一致延时的情形。是否还有更快的方案?
3. 内存型关系数据库
可靠的持久化指数据存储到磁盘等设备上。图1展示了传统磁盘数据库的基本访问模式。
图1
抛开持久化的可靠性,即数据可以先不存储到磁盘上(Disk),内存存储的性能远高于磁盘存储。下表展示了针对Oracle和Altibase所做的性能对比,后者在插入和查询上性能是Oracle的5-7倍。
|
数据库 |
测试结果 |
TPS |
|
Oracle |
203秒 |
246条/秒 |
|
Altibase |
28.32秒 |
1785条/秒 |
表1. Oracle、Altibase性能对比 -插入5万条 【7】
|
数据库 |
测试结果 |
TPS |
|
Oracle |
885秒 |
112条/秒 |
|
Altibase |
170秒 |
588条/秒 |
表2 Oracle、Altibase性能对比 –关联查询10万条【7】
由此可见:Pm >>> Pd
(Pm - 内存数据库读写性能, Pd - 磁盘数据库读写性能)
结合前面分析的模型复杂性和业务复杂性原因,关系数据库(RDBMS)必须采用。因此,这两点考虑可以推导出另一个解决思路:内存型关系数据库。
|
磁盘型关系数据库 |
Key-Value引擎 |
内存型关系数据库 |
|
|
功能 -结构化操作和查询等 |
Y |
N |
Y |
|
性能 |
低 |
高 |
高 |
表3. DB选型对比分析
这个方案里,我们可以将内存先看做一种“磁盘”,读写操作都针对内存数据库进行,不再直接与磁盘数据库交互,这较好的避免了单纯MySQL 读写分离架构存在的时间延迟和一致性问题。如下图所示:
图2
4. 内存数据库的持久化
数据最终还是要存储到磁盘(Disk)上,内存数据库中的数据变化需要复制到与磁盘数据库上。这时,从内存向磁盘复制数据的过程可以看作原始写操作的异步操作,显然,异步操作使得前端的写操作显得更快。如下图所示:

图3
在事务型(OLTP)系统中,内存数据库中在启动时需要和磁盘数据库保持一致。 因此,内存数据库需要有相同的库表定义;并且在第一启动时,将所需库表数据加载到内存数据库中。
5. 内存数据库集群化
目前,经典的MySQL集群,通过读写分离,水平切分,实现海量数据存储。为应对海量数据存储,内存数据库同样需要做集群。垂直和水平切分策略,可用性策略与MySQL集群架构设计基本相同。如下图所示,其中 Ameoba 是分布式数据库代理,它进行数据路由等控制。
唯一的不同是,由于内存数据库的高性能,可以不再进行读写分离设计。

图4
6. 混合分区(Hybrid Shard)
接第4节的分析,内存数据最终仍需要持久化到磁盘。这里需要一种混合分区(Hybrid Shard)来解决。即原来一个MySQL节点承担的一个水平分区,将由一个内存数据库节点和一个MySQL节点共同组成。
H-Shard = MDB + MySQL.
这种数据库架构将形成由两级数据库(2LDB),混合分区构成的集群。的如下图所示:

图5
7. 内存数据库选型
常见的内存数据库产品包括商业版和免费版两类。商业版如:Altibase,Timesten,Berkley DB等。他们在电信,金融,证券等高性能计算应用中运用较为广泛。商业版功能强大,然而,价格比较昂贵,不适合目前“廉价PC+免费软件”的架构搭建思想。
笔者曾就职与中国移动系统提供商,其中计费、运营等系统就运用Timesten提供高性能运算,但还主要用于高频度小数据计算,如计费批价,优惠计算,信控等,采用单节点模式使用。
开源领域产品主要有H2,HsqlDB,Derby等。在混合分区架构中,内存数据库将承担OLTP的职责,因此除了读写性能外,功能的完备,事务等都需要作为优先评估的因素。
8. 新架构的挑战
通过引入内存数据库作为中间持久层,再加入分布式架构以支撑海量数据访问,这种架构设计颇具挑战。最先而易见的情况就是新架构的复杂度,正如大规模MySQL集群架构诞生初始一样。
我们以 H2 ,一个开源的高性能内存数据库为例说明:
1) 整合 Ameoba 与 H2
Ameoba 是分布式数据库代理,它与 MySQL 整合已经在阿里巴巴核心业务中成功运用。如果仅将数据库节点看作一个存储,MySQL Node 和 H2 Node 并无本质区别。JDBC驱动,DB切分,路由,皆由Ameoba 统一负责。
2) 异步持久化
每个逻辑混合分区= H2 + MySQL,谁来完成H2 中的数据变更异步写入 MySQL?
比较好的方案是内存数据库提供实时增量的复制器(Replicator) ,例如:基于联机日志复制的双机热备机制。AltiBase 等产品就提供了此功能。
3)高可用性
内存数据库一旦崩溃,数据不复存在。因此首先要做到数据快速异步写入MySQL作持久化存储。同时要有健壮的容错和Failover机制,保证一个H2节点崩溃,同一逻辑分区中的替补H2节点立即顶替工作。
一种方案是分布式数据库代理如 Ameoba 来解决,例如:每个Shard,H2至少设2个节点,采用Primary-Secondary模式,如图6所示:
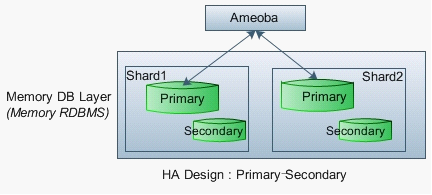
图6
另一种方案是前面提到的内存数据库实时复制功能。
虽然有些内存DB如H2自身能支持内存,磁盘两级存储,但其自身提供的磁盘存储和访问方案可靠性不如 MySQL。因此,使用内存式Primary-Secondary 模式更为可行。
4)分布式事务
数据库切分架构带来分布式事务问题,对一些事务要求较高的场景,这颇具挑战。Ameoba 目前还在解决中。Ameoba + H2组合面临同样的挑战。
目前一种比较一致意见和做法就是冷处理——尽量不用事务。 一致性问题根据业务的特点,采用数据订正来解决;个别业务使用补偿事务。因为目前大部分应用,即便是核心业务,对事务的要求也不高。
9. 进一步思考
1) 多种数据切分模式
在一个大型互联网站,不同的应用和数据需要做不同的处理。在总体垂直切分模式基础上,选择数据量大的功能进行水平切分,例如:供求、订单、交易记录。
2)数据缓存(Data Cache)
虽然内存数据库层(MDB)能更高效支撑交易型数据库,特别是应对结构化应用及复杂查询服务,但对高频度的查询(Query)和实体查找(Find),Key-Value缓存仍然是一项必要的设计。Cache能提供更高的查询速度,并减少对MDB的访问压力,特别是读写密集的高并发场景。因为这个架构中,内存数据库仍然作为一种存储Store,而不是Cache。
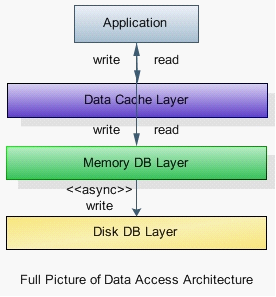
图7
上图展示了,MDB层之上还需要DCL层来提供高性能缓存服务。
10. 总结
本文提出了一种通过引入内存数据库层,并建立两层,多分区的分布式数据库架构。此方案用于解决海量高并发系统的高性能数据存储和访问问题,尤其是电子商务类等业务复杂的互联网站。其核心思想是:
1)高性能:是通过内存数据库提供高性能关系数据库存取服务,这是此架构的最主要目标;
2)持久化:通过两级数据库及异步写完成持久化;
3)海量数据支撑:通过垂直和水平分区实现海量数据的支撑;
4)高可用性:在Ameoba基础上,通过主备节点进一步实现MDB的高可用性;二级磁盘数据库可以实现数据的快速恢复。
源地址:http://laf.freel.cn/nosql/designofmemorydatabase.html
