之前使用逻辑回归算法得到的生还预测kaggle打分是0.75119分,emmm,可以说是比较差的一个分数了,下面进行调整。
-----------------------------------------------------------------------------------------------
1、判断拟合状态
由于过拟合和欠拟合两种情况下对于数据集的处理不同,所以首先需要判断现有模型是过拟合还是欠拟合。
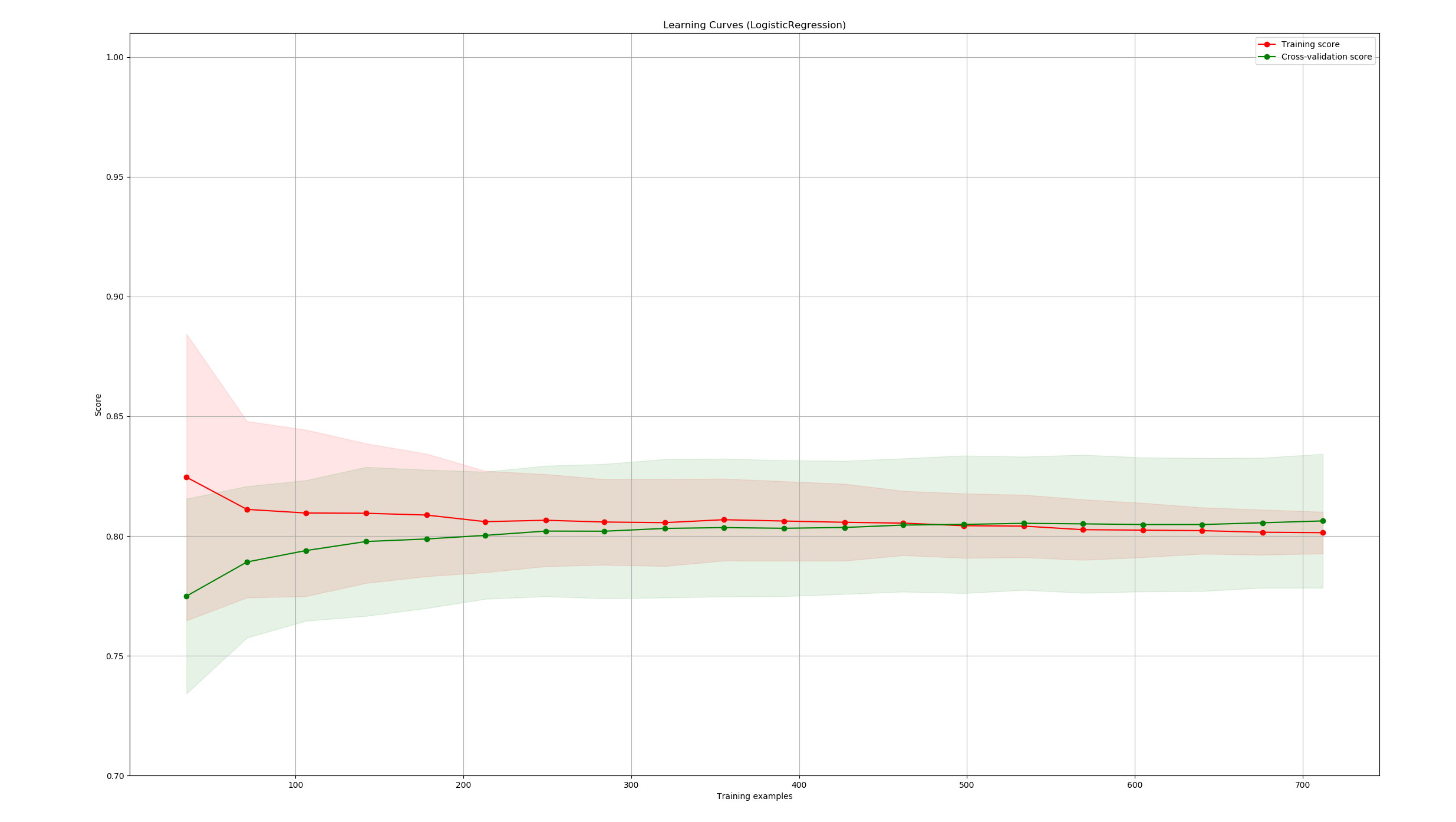
我们可以通过绘制学习曲线(learning curve)来进行判断(样本数为横坐标,准确率为纵坐标)
learning curve 官方文档 learning curve 官方示例代码
首先定义学习曲线的绘制函数:
from sklearn.learning_curve import learning_curve from sklearn import cross_validation #定义学习曲线绘制 def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1, train_sizes=np.linspace(.05, 1., 20), verbose=0, plot=True): plt.figure() plt.title(title) if ylim is not None: plt.ylim(*ylim) plt.xlabel("Training examples") plt.ylabel("Score") train_sizes, train_scores, test_scores = learning_curve( estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes) train_scores_mean = np.mean(train_scores, axis=1) train_scores_std = np.std(train_scores, axis=1) test_scores_mean = np.mean(test_scores, axis=1) test_scores_std = np.std(test_scores, axis=1) plt.grid() plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r") plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g") plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score") plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score") plt.legend(loc="best") return plt
根据已有模型,设置上面函数中的参数并调用:
#具体参数 estimator = lrModel title = 'Learning Curves (LogisticRegression)' X, y = data_train[inputcolumns], data_train[outpucolumns] cv = cross_validation.ShuffleSplit(891, n_iter=100, test_size=0.2, random_state=0) #调用 plot_learning_curve(estimator, title, X, y, ylim=(0.7, 1.01), cv=cv, n_jobs=4) plt.show()
得到如下的图形,属于欠拟合的状态,所以后续还需要做更多的特征工程:
2、特征工程
考虑到对数据集的处理,可以从以下的几个方向进行更深层的考虑:
1)未使用到的姓名、船票编号列是否能够加以利用
2)Parch和Sibsp两个变量分别代表同船的兄弟/姐妹和分母/小孩的个数,求和是否能够代表同船的家族大小(人数)
3)缺失年龄的随机森林拟合欠妥,是否有更好解决方法
经过更深入的观察,先对数据做以下处理(从易到难):
1)Parch和Sibsp求和得到家族人数
#将Parch 和 SibSp 变量求和得到家族大小 data['family_size'] = data['Parch'] + data['SibSp']
2)根据Ticket 分组,得到人均票价,再根据人均票价进行离散化
#根据Ticket进行分组,得到人均票价, 再根据票价区间进行离散化 data['Fare'] = data['Fare'] / data.groupby(by=['Ticket'])['Fare'].transform('count') data['Fare'].describe() def fare_level(s): if s <= 5 : #低价票 m = 0 elif s>5 and s<=20: #普通票 m = 1 elif s>20 and s<=40: #一等票 m = 2 else: m = 3 #特等票 return m data['Fare_level'] = data['Fare'].apply(fare_level)
3)将对结果影响最大的两个因素——sex 和 pclass 进行合并,生成一个新的变量
data['Sex_Pclass'] = data.Sex + "_" + data.Pclass.map(str) dummies_Sex_Pclass = pd.get_dummies(data['Sex_Pclass'], prefix= 'Sex_Pclass') data = pd.concat([data, dummies_Sex_Pclass], axis=1)
4)缺失年龄填补,这里使用线性回归和随机森林的均值
age_data = data[['Age','Fare_level', 'family_size', 'Pclass','Sex_Pclass_female_1', 'Sex_Pclass_female_2', 'Sex_Pclass_female_3', 'Sex_Pclass_male_1', 'Sex_Pclass_male_2', 'Sex_Pclass_male_3', 'embarked_C','embarked_Q','embarked_S']] fcolumns = ['Fare_level', 'family_size', 'Pclass', 'Sex_Pclass_female_1', 'Sex_Pclass_female_2', 'Sex_Pclass_female_3', 'Sex_Pclass_male_1', 'Sex_Pclass_male_2', 'Sex_Pclass_male_3', 'embarked_C','embarked_Q','embarked_S'] tcolumns = ['Age'] age_data_known = age_data[age_data.Age.notnull()] age_data_unknown = age_data[age_data.Age.isnull()] x = age_data_known[fcolumns]#特征变量 y = age_data_known[tcolumns]#目标变量 from sklearn.ensemble import RandomForestRegressor from sklearn.linear_model import LinearRegression from sklearn.model_selection import GridSearchCV #线性回归 lr = LinearRegression() lr_grid_pattern = {'fit_intercept': [True], 'normalize': [True]} lr_grid = GridSearchCV(lr, lr_grid_pattern, cv=10, n_jobs=1, verbose=1, scoring='neg_mean_squared_error') lr_grid.fit(age_data_known[fcolumns], age_data_known[tcolumns]) print('Age feature Best LR Params:' + str(lr_grid.best_params_)) print('Age feature Best LR Score:' + str(lr_grid.best_score_)) lr = lr_grid.predict(age_data_unknown[fcolumns]).tolist() lr = sum(lr, []) #随机森林回归 rfr = RandomForestRegressor() rfr_grid_pattern = {'max_depth': [3], 'max_features': [3]} rfr_grid = GridSearchCV(rfr, rfr_grid_pattern, cv=10, n_jobs=1, verbose=1, scoring='neg_mean_squared_error') rfr_grid.fit(age_data_known[fcolumns], age_data_known[tcolumns]) print('Age feature Best LR Params:' + str(rfr_grid.best_params_)) print('Age feature Best LR Score:' + str(rfr_grid.best_score_)) rfr = rfr_grid.predict(age_data_unknown[fcolumns]).tolist() #取二者均值 predictresult = pd.DataFrame() predictresult['lr'] = lr predictresult['rfr'] = rfr predictresult['result'] = (predictresult['lr'] + predictresult['rfr']) / 2 data.loc[data['Age'].isnull(), 'Age'] = predictresult['result']
5)根据年龄段,进行离散化
def age_level(s): if s <= 14 : #儿童 m = 0 elif s>14 and s<=35: #青年 m = 1 elif s>35 and s<=60: #中年 m = 2 else: m = 3 #老年 return m data['age_level'] = data['Age'].apply(age_level)
3、单个模型拟合
还是使用逻辑回归模型,对上述处理过的数据集进行拟合
data_train = data.drop(['Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked', 'Sex_Pclass'], axis=1, inplace=False) #data_train.columns #再次进行单个模型拟合 from sklearn import linear_model lrModel = linear_model.LogisticRegression(penalty='l1') inputcolumns = ['family_size', 'Fare_level', 'Sex_Pclass_female_1', 'Sex_Pclass_female_2', 'Sex_Pclass_female_3', 'Sex_Pclass_male_1', 'Sex_Pclass_male_2', 'Sex_Pclass_male_3', 'embarked_C', 'embarked_Q', 'embarked_S', 'age_level'] outpucolumns = ['Survived'] lrModel.fit(data_train[inputcolumns], data_train[outpucolumns]) lrModel.score(data_train[inputcolumns], data_train[outpucolumns])
-----------------------------------------------------------------------
对测试集做同样处理后,得到的预测结果上传kaggle,评分0.77,上升了0.02。 >_<
后续将再进行交叉验证和模型融合的优化