一、概念
关联(Association)
关联就是把两个或两个以上在意义上有密切联系的项组合在一起。
关联规则(AR,Assocaition Rules)
用于从大量数据中挖掘出有价值的数据项之间的相关关系。(购物篮分析)
协同过滤(CF,Collaborative Filtering)
协同过滤常常被用于分辨某位特定顾客可能感兴趣的东西,这些结论来自于对其他相似顾客对哪些产品感兴趣的分析。(推荐系统)
二、关联规则
1、相关数据指标
两个不相交的非空集合X、Y,如果X -> Y,就说X -> Y是一条关联规则。
强度:支持度(Support):support({X -> Y}) = 集合X与集合Y中的项在一条记录中同时出现的次数 / 数据记录的个数
自信度(Confidence):confidence({X -> Y})集合X与集合Y中的项在一条记录中同时出现的次数 / 集合X出现的次数
效度:提升度(Lift):度量规则是否可用的指标,描述的是相对于不用规则,使用规则可以提高多少,提升度大于1,规则有效
lift({X -> Y}) = confidence({X -> Y}) / support({X -> Y})
2、计算步骤
- 扫描数据集,统计一级候选集出现的次数
- 清除不满足条件的候选项集,得到一级项集
- 从一级项集中国,组合二级候选项集,统计数据集中它们出现的次数
- 清除不满足条件的候选项集,得到二级项集
- 从二级项集中,组合三级候选项集,统计数据集中他们出现的次数
- ……
- 将得到的项集作为结果返回
大致过程如下:
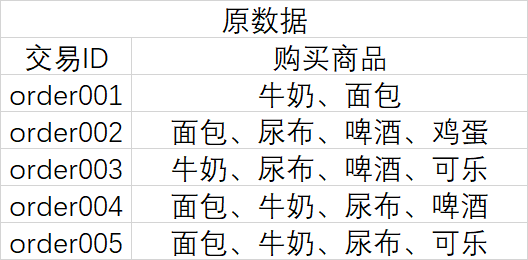
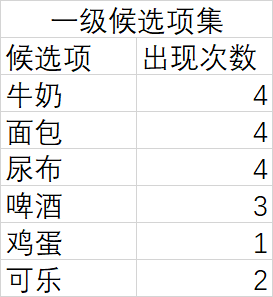
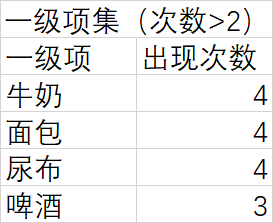




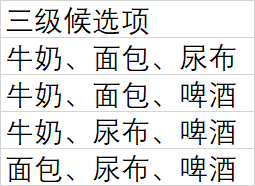
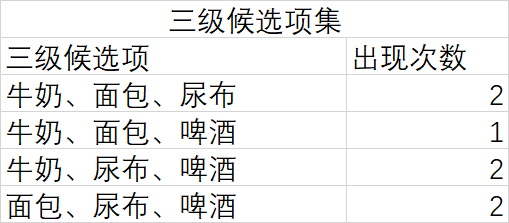
3、 使用python实现关联算法(apriori算法)
!apriori 包不支持DataFrame的数据格式,需要将数据转化为array数组
#导入如下格式的数据
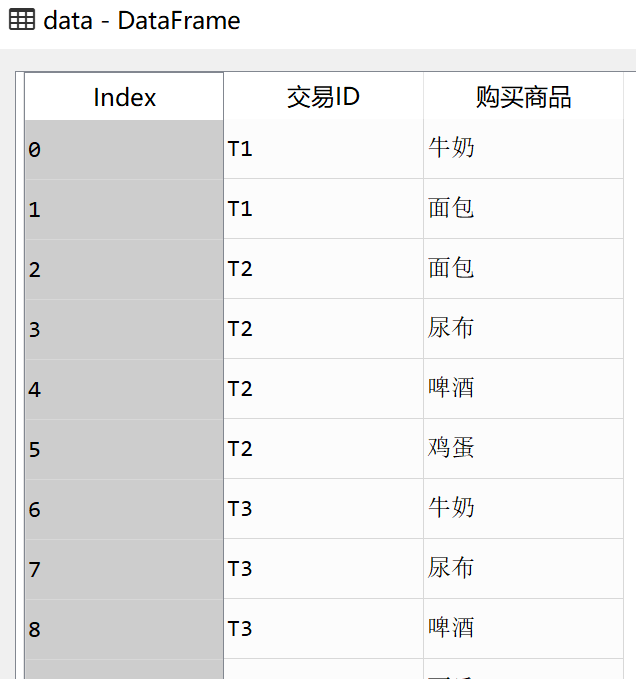
#变换数据格式,然后通过apriori方法进行处理
transform = data.groupby(by='交易ID').apply(lambda x: list(x.购买商品)).values result = list(apriori(transform))
输出result并观察,发现如下规律
#该数据格式包含各种项集和所对应的支持度、自信度、提升度 '''RelationRecord( items=frozenset({'可乐'}),
support=0.4, ordered_statistics=[OrderedStatistic(
items_base=frozenset(), items_add=frozenset({'可乐'}),
confidence=0.4,
lift=1.0
)
]
)''' #items = items_base + items_add
#遍历result,得到每个项集(X 与 Y ,并得到相对应的支持度、自信度和提升度
supports = [] confidences = [] lifts = [] bases = [] adds = [] for i in result: supports.append(i.support) confidences.append(i.ordered_statistics[0].confidence) lifts.append(i.ordered_statistics[0].lift) bases.append(list(i.ordered_statistics[0].items_base)) adds.append(list(i.ordered_statistics[0].items_add)) #将结果转化为容易处理的数据框 get_result = pd.DataFrame({ 'base': bases, 'add': adds, 'support': supports, 'confidence': confidences, 'lift': lifts})
#得到如下的数据框,其中有不同项集及其对应结果,可通过关联规则得到符合的关联项

三、 协同过滤
1、 相关数据指标
协同过滤简单来说就是利用某兴趣相投、拥有共同经验的群体的喜好来推荐用户感兴趣的信息。
协同过滤主要收集每个用户对使用过的物品的评价(打分或星级等)。
通过用户对各种商品评分的高低,得到用户的喜好并,根据相似喜好的用户历史数据,从而推荐一些信息
优点:
- 能够过滤机器难以自动分析的信息,如艺术品、音乐等
- 共用其他人的讲演,避免了内容分析的不完全或不精确,能够基于一些复杂的,难以表述的概念(如个人品味)进行过滤
- 有推荐新信息的能力,可以发现用户潜在的但自己尚未发现的兴趣偏好
- 推荐个性化、自动化程度高,能够有效的利用其他相似用户的回馈信息,加快个性化学习的速度
缺点:
- 新用户在开始时推荐质量较差
- 新项目的推荐难度大,因为推荐质量取决于历史数据集
2、 计算步骤
- 收集用户信息,必须数据基础:用户、商品、评分
- 根据以上数据得到用户评分向量和商品评分向量(用户评分尽量使用标准化评分,消除用户因打分习惯而导致的差异)
- 根据用户评分向量计算距离(如欧式距离)

- 计算用户相似度

- 两种方法计算相似邻居
- A)固定数量的邻居(K-neighborhoods)
- 不考虑邻居的距离差异,只取当前点最近的 K 个点作为其邻居
- B)基于相似度门槛的邻居(Threshold-based neighborhoods)
- 以当前点为中心,距离为 K 的区域内的所有点作为当前点的邻居

3、 使用python实现协同过滤算法
#导入如下数据,含用户ID,商品ID,用户评分
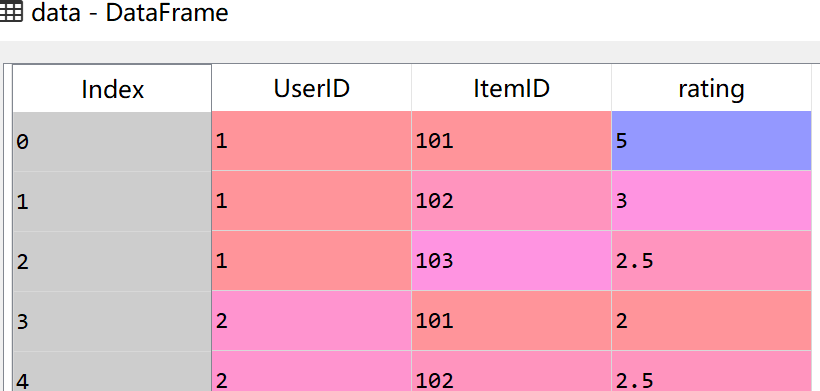
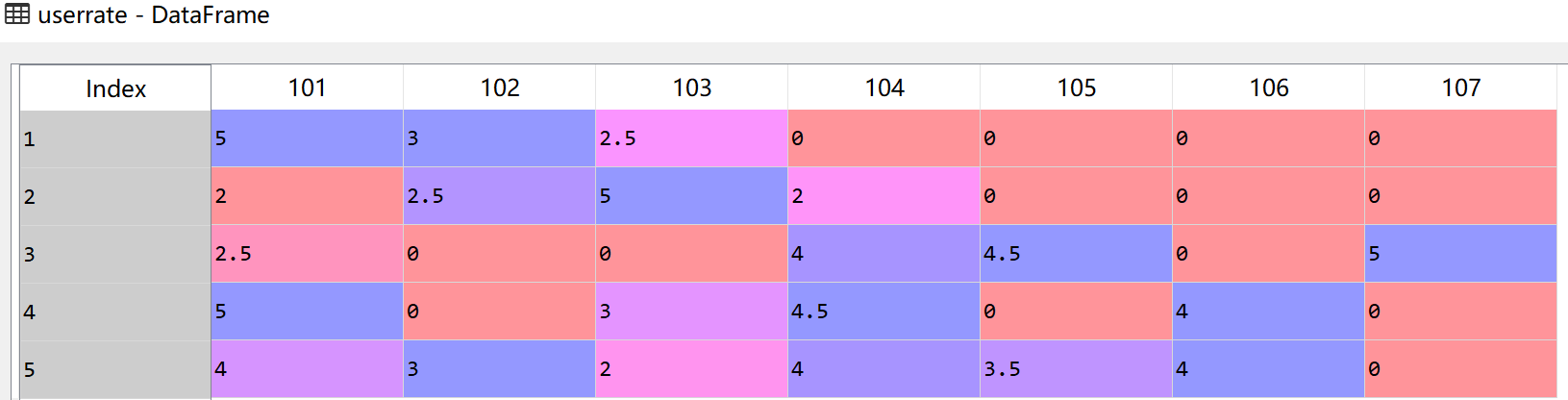
#通过交叉表及变换形式得到用户评分矩阵
userrate = data.pivot_table(index='UserID', columns='ItemID', aggfunc=sum, fill_value=0) #将透视表转为数据框,优化列名 userrate.columns = userrate.columns.droplevel(0) del userrate.columns.name
#计算每个用户之间的距离和相似度
#计算每个用户之间的距离 dist = pd.DataFrame(euclidean_distances(userrate)) dist.index = userrate.index dist.columns = userrate.index #计算每个用户之间的相似度 sim = 1/(1+dist)
#设置参数,获取相似用户
#设置邻居个数为3 用户ID为1 k = 3 userId = 1 #获取3个相似用户并得到其相似度 simUserIds = sim.sort_values(userId, ascending=False)[userId].index[1:k+1] simUser = sim.ix[simUserIds, userId]
#根据相似用户得到商品的推荐排序
#根据相似用户,计算出每个物品的评分 score = pd.DataFrame(np.dot(simUser, userrate.ix[simUserIds])) #对结果排序,得到最终的结果 result = userrate.columns[score.sort_values(0, ascending=False).index.values]