阅读声明:以下内容是结合网上材料及工作内容所写的个人理解,如有不当,欢迎大家指正~~~谢谢啦
一、ZooKeeper的选举机制、FailOver机制
我们知道ZooKeeper在分布式环境中协调服务,如果宕机,那么整体的协调服务失效,所以单台ZooKeeper存在单点故障问题,由此我们引入ZooKeeper的集群模式,搭建环境在博主的另一篇博文,谢谢大家。
选举机制:一句话,选出ZooKeeper集群中的领导者Leader。
假如当前有5台ZooKeeper服务启动,如下图所示。

ZooKeeper的选举机制有两个阶段:
①数据恢复阶段
在该阶段,当每台ZooKeeper启动时,会去持久化目录中寻找自身所拥有的最大事务Id。
事务Id:每发生一次事务操作(除了读操作以外),ZooKeeper集群都会为这个事务分配一个全局递增事务id,每个ZooKeeper之所以找到自身所拥有的最大事务id,是因为事务id越大,事务越新
②选举阶段
每个ZooKeeper会提交选举协议信息如下:
1)自身拥有的最大事务id
2)自身的选举Id(server.id)
3)逻辑时钟值,作用是确保每台zk服务器在同一个选举轮次中
4)自身的服务器状态
*:Looking 选举状态
*:Leader 领导状态
*:Follower 从属状态
*:Observer 观察者状态
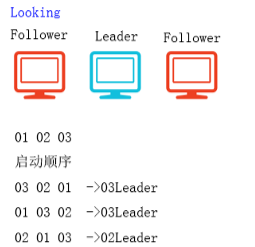
③ZooKeeper的PK原则(必须满足过半性原则)
1.优先比较最大事务id,谁大谁当leader
2.如果最大事务id相同,比较选举id,谁大谁当leader
例如:
③FailOver机制
当集群中的Leader宕机后,剩余节点Follower会选举出新的Leader
⑤过半性
ZooKeeper有过半性存活的特性,即集群中节点数量必须超过半数以上,才能正常提供服务和选举。
另外集群数量最好以奇数为准,否则可能出现“脑裂”。
二、ZAB协议与PAXOS算法
这里暂时还在研究中,后续会补充。