目的:
将数据集中相似的数据记录成不同的、更小的数据。
适用范围:
必须提前知道有多少个分区。 比如按天、按月、年等等。
结构:
数据是通过分区器进行分区的。 所以需要自定义分区器(partitioner)函数来确定每条记录应该被分在那个分区。
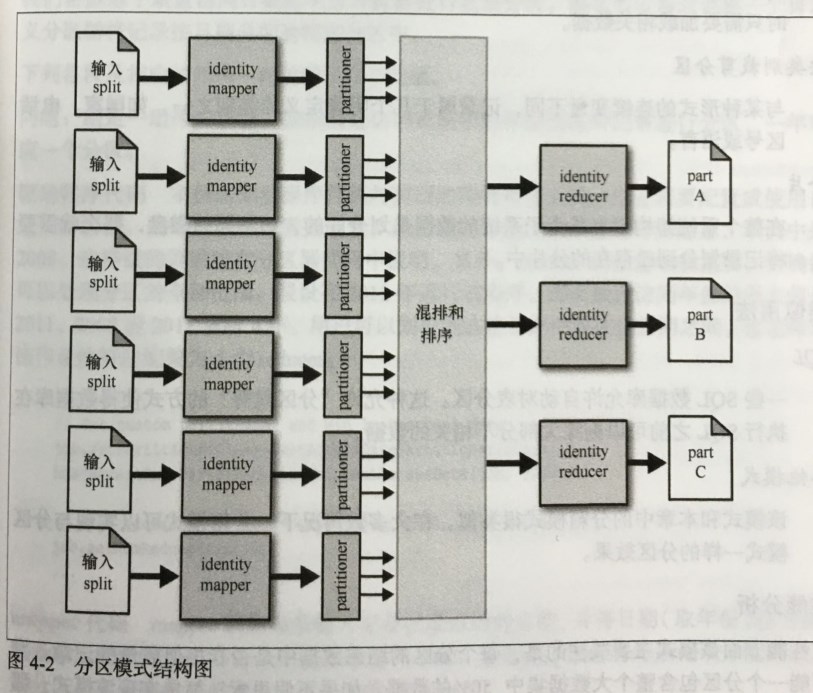
结果:
每个分区将对应一个输出的 part 文件。
由于每个类别都将被写入到一个大文件中,因此采用基于块压缩的 SequenceFile 存储数据是一种很好的方式,同事该方法也被证明是 Hadoop 中最有效、最易于使用的数据格式。
已知应用:
按连续值剪裁分区
例如:日期或者数值区间
按类别剪裁分区
例如:国家区域、电话区号、语言形式等等。
分片:
如果整个系统中有某个子系统的数据是已经划分好的。 如不同的磁盘,那么就需要将记录划分到已存在的分片中。
性能分析:
热点问题, 热点将是一个大问题,需要单独考虑。 如: 4T 文件需要重新分区 分四组 (4个reduce)方便统计。那么其中一组占3T 这将引发 单点 reduce 的热点问题和数据倾斜。 可以考虑二次分区。或是其中一组进行打散 变为 (3组 1T + N组 3T 的随机分区。 ) 而这样做并不影响对分区以后的处理, 唯一的影响是将来分析时,需要将分区的文件全部引入即可。
分区示例:
作业需要配置成使用自定义分区器,同时分区器也要重写。
Mapper.mapper() :
获取每条输入记录后的 分区属性。 并将分区属性作为Key。 然后整条记录作为 V 。 在 Reduce 阶段此 K 将被忽略。 (因为木有用了嘛)
Partitioner.getPartitioner():
分区检 mapper 输出的每个 K/V ,并确定将 键值对写入那个分区。 这样每个已经编号的分区数据将被相应的reduce 复制。 此外 分区器实现了 Configurable 接口。 在任务初始化阶段配置分区器时将调用 setConf 方法。 在作业配置阶段,驱动程序负责调用 LastAccessDatePartitioner.setMinLastAccessDate()方法获取该值。
Reduce.reduce() 只输出即可。 输出循环的 V。