概览
慕课网python开发简单爬虫课程(https://www.imooc.com/learn/563)学习笔记,项目实践代码见 https://github.com/L-rookie/python_spider.git
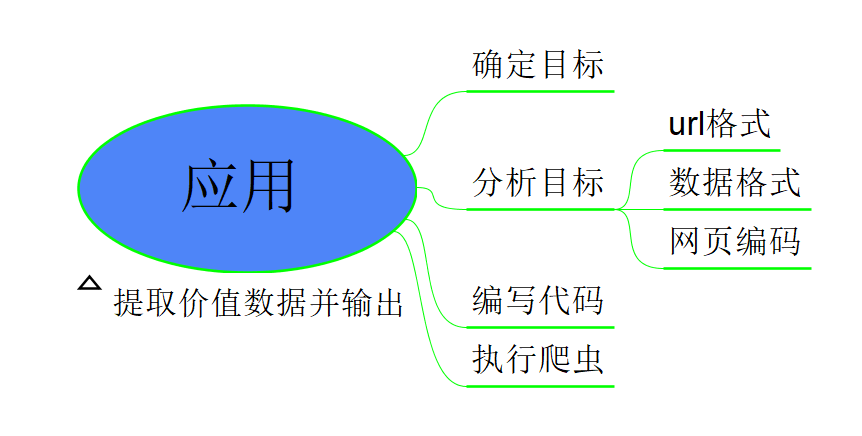
项目需求
提取价值数据并输出
应用过程
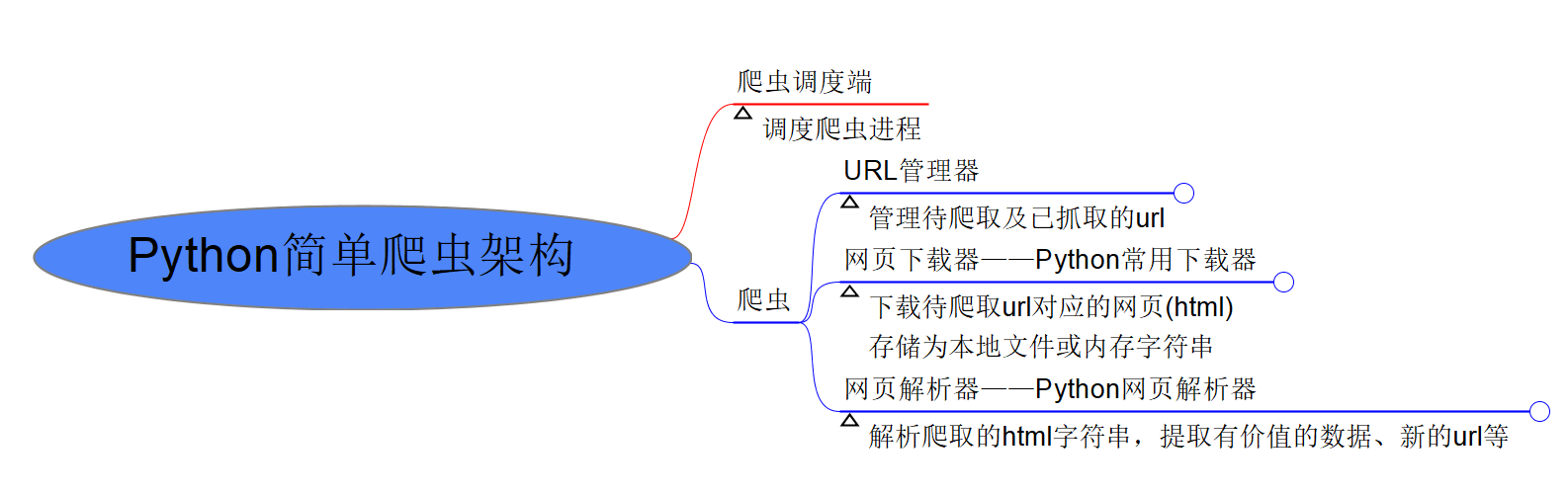
爬虫
简单爬虫架构
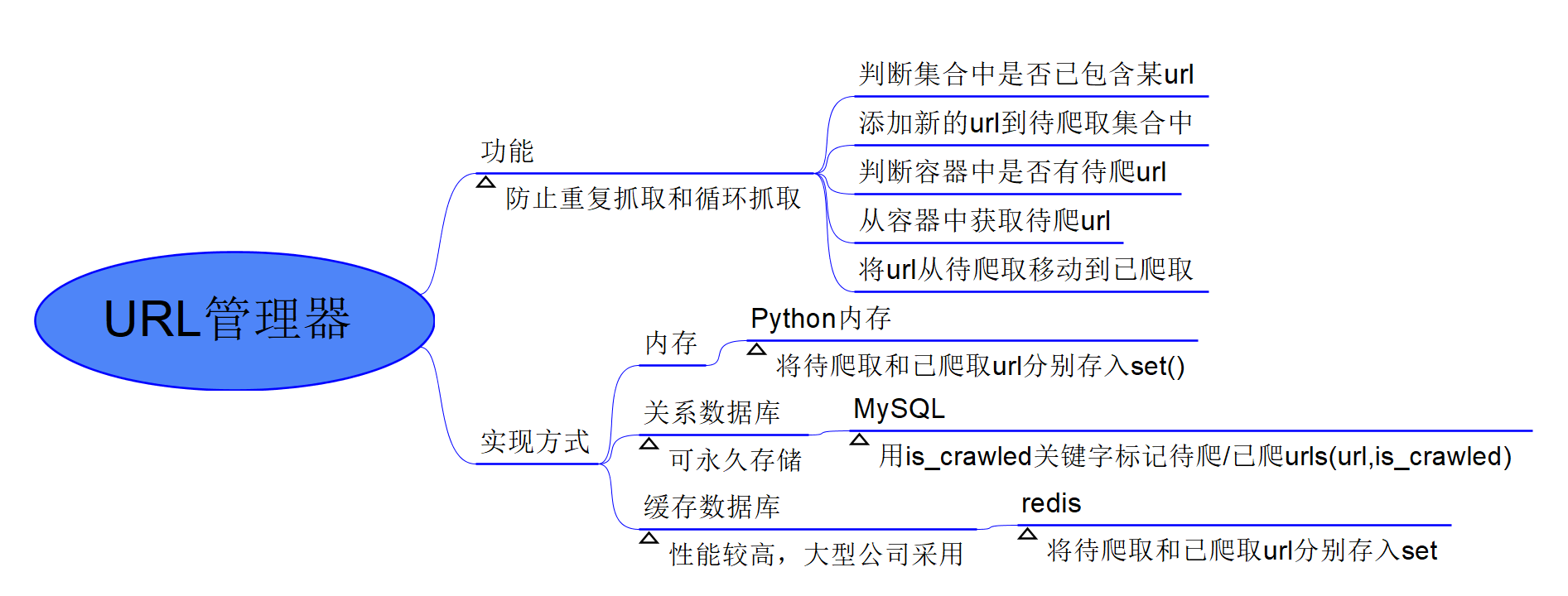
URL管理器
用于管理待爬取及已抓取的url
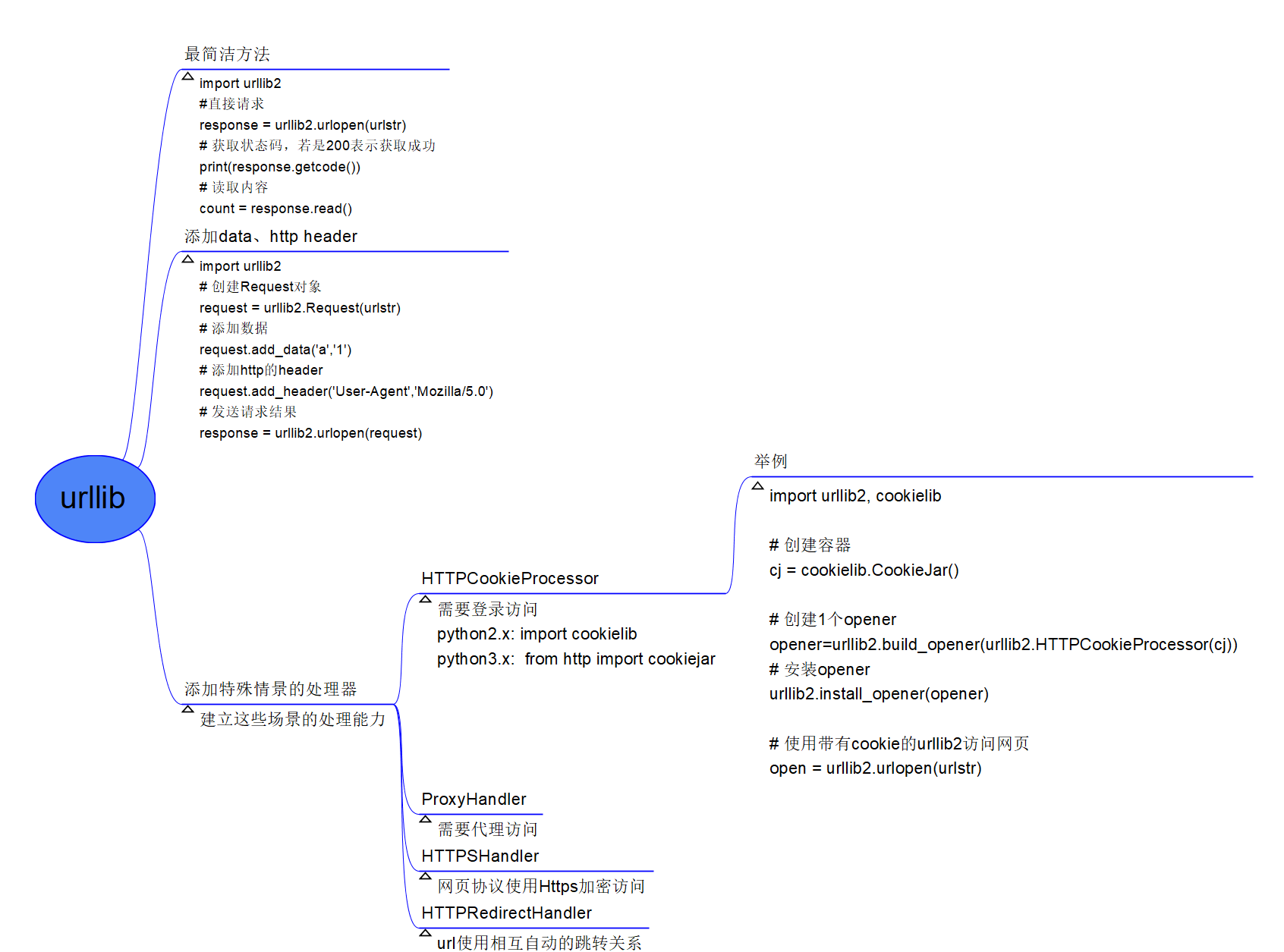
网页下载器
下载待爬取url对应的网页(html)并将其存储为本地文件或内存字符串。Python常用网页下载器为urllib2(Python2.x)或urllib.request(Python3.x)。urllib为Python官方自带模块,不需要额外安装。
网页解析器
解析爬取的html字符串,提取有价值的数据、新的url等
